distributed
 distributed copied to clipboard
distributed copied to clipboard
Allow workers to talk to multiple schedulers
This is a proof of concept. I was talking with a group last week who wanted to use Dask for production workloads where they had lots of smallish concurrent requests and cared pretty strongly about uptime. They were reasonably concerned about being bottlenecked on a single Scheduler.
For this kind of highly concurrent workload it might make sense to have a pool of workers and a smaller pool of schedulers to query them, possibly behind a traditional load balancer.
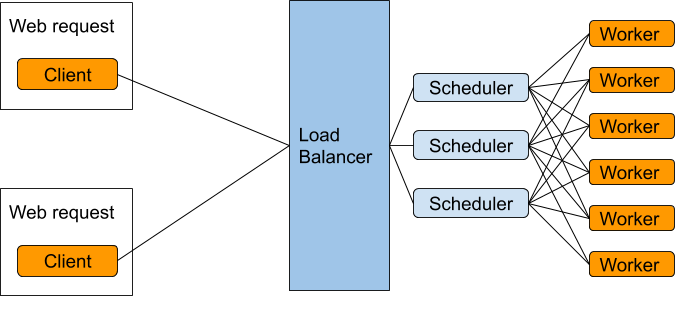
Today, Workers know about only one Scheduler. It turns out not to be difficult to generalize this a bit, and let them talk to multiple Schedulers. Actually that might not be true, I haven't gone through any tricky cases for this yet, but I thought that I'd post what I have here as a proof of concept and a conversation starter. This was only about an hour's work. This could be doable in a day, or maybe a week. We might also choose to reject it for reasons of code complexity.
@jcrist , @fjetter , @mmccarty, @hussainsultan this seems like the sort of thing that might interest you
I'd be curious to know if the high throughput scenario affects more people. I'm very excited about the idea of having a second scheduler but I'm thinking rather about redundancy / fail-safe for long running jobs which feels to be on the opposite side of the spectrum here.
No matter in what shape multi-scheduler are introduced I think we should turn a few rounds and also discuss what kind of features we expect to be supported.
A probably obvious thing to exclude here are the synchronisation primitives (Lock, Semaphore, Event, etc.) since implementing this in a distributed way w/out leader election should be out of scope, I'd assume, and leader election (difficult topic on its own) kind of defeats the purpose of the load balancing scenario, or at the very least makes it more complicated.
Other features are probably working out of the box but may have non-trivial side effects. First thing popping into my mind is work stealing which I would argue is even for a single scheduler a difficult problem and not entirely stable. Similarly features like rebalance and replicate are already known to have reached their limits.
Another topic which will probably pop up as soon as this is implemented is visibility. Do we intend to build super-bokeh dashboards or would draw the line here?
Taking a step back, I assume the shared worker pool is there to save costs? Principally such a system could be already set up by simply deploying two full dask clusters with dedicated worker pools, couldn't it? It should be able to start multiple workers on the same VMs/pod/container if resource isolation is not a concern and cost is a factor. Therefore, I'm wondering what we hope from having this integration other than more complexity :)
but I'm thinking rather about redundancy / fail-safe for long running jobs which feels to be on the opposite side of the spectrum here
Correct. This is really just multiple Dask clusters, which happen to share the same computational resources, which, as you suggest, is merely for cost savings.
I'm also excited about a resilient scheduluing, but I think that is probably a different effort.
Very interesting, indeed. A few questions/thoughts come to mind:
- How intelligent is that load balancer? Assuming a client would connect to it rather than a scheduler. So, I'm wondering how it routes or whether it needs any context of the cluster(s) load at all.
- Assuming the LB is commodity, how would the user choose which scheduler to use? In other words, how does the user know about the scheduler bottlenecks?
- Would a scheduling policy help? Policies could hold information about how the pools are used.
- +1 on
rebalanceandreplicateimpacts. Would you get into a situation where a worker is churning among schedulers. Something like pull data for client (c1) task, complete c1 task, free memory, pull data for another client (c2) task, complete c2, free memory, pull data for c1 again.
How intelligent is that load balancer? Assuming a client would connect to it rather than a scheduler. So, I'm wondering how it routes or whether it needs any context of the cluster(s) load at all.
I haven't done any work here. I'm proposing that we would take one from off the shelf in these situations.
Assuming the LB is commodity, how would the user choose which scheduler to use? In other words, how does the user know about the scheduler bottlenecks?
How do load balancers currently work? I imagine that they have something like a round-robin behavior, or that they track to see if a target is done with a previous request before giving it another.
Going to an extreme, we could also have a scheduler per request. They're cheap to start up, and could easily live within a web request cycle.
Would a scheduling policy help? Policies could hold information about how the pools are used.
Sure, but again I'm hoping that this kind of situation has come up before in the web-world and that we can pull something from there.
More generally, I think that this is useful more in a situation where you're hosting lots of small computations rather than serving long-lived interactive sessions (where a single cluster per user is probably best).
+1 on rebalance and replicate impacts. Would you get into a situation where a worker is churning among schedulers. Something like pull data for client (c1) task, complete c1 task, free memory, pull data for another client (c2) task, complete c2, free memory, pull data for c1 again.
I expect other work to start up in a month or so that replaces rebalance/replicate with active memory management.
We might also choose to reject it for reasons of code complexity.
Taking a step back, I assume the shared worker pool is there to save costs? Principally such a system could be already set up by simply deploying two full dask clusters with dedicated worker pools, couldn't it? It should be able to start multiple workers on the same VMs/pod/container if resource isolation is not a concern and cost is a factor. Therefore, I'm wondering what we hope from having this integration other than more complexity :)
I'm in agreement with @fjetter here, this seems like a micro-optimization that could be better served by making good use of existing infrastructure. Scheduling worker pods with < 1 core on k8s and running multiple clusters behind a load balancer would have a similar effect, without requiring changes to the internals of dask. This seems like a fringe use case that most users are unlikely to need, and the support for "multiple schedulers" may confuse users who may think this provides scheduler redundancy and HA, when it doesn't really (at least not in the way that most users would want).
Therefore, I'm wondering what we hope from having this integration other than more complexity :)
this seems like a micro-optimization that could be better served by making good use of existing infrastructure. Scheduling worker pods with < 1 core on k8s and running multiple clusters behind a load balancer would have a similar effect
The best open example I've seen of this was at the UK Met office, where they, in theory, would like to serve large computations behind a web server to the general citizenry. If you want web-responsiveness then you need to have a warm pool of workers running. Introducing Kubernetes into the mix isn't that attractive.
Therefore, I'm wondering what we hope from having this integration other than more complexity :)
This is a fair concern. I think that the real question here is how complex things get. The changes in this PR seem non-trivial to me, but also not-terrible.
Setting aside the complexity and having not thought about it in detail, I like and am excited about this! I see potential here
Is there an application that you have in mind Sean? Or is your excitement of a more general nature?
On Tue, Sep 15, 2020 at 10:08 AM Sean M. Law [email protected] wrote:
Setting aside the complexity and having not thought about it in detail, I like and am excited about this! I see potential here
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub https://github.com/dask/distributed/pull/4098#issuecomment-692850391, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTAKCGMECYYVNGXGJNLSF6NQJANCNFSM4Q3NNFTQ .
Is there an application that you have in mind Sean? Or is your excitement of a more general nature? … On Tue, Sep 15, 2020 at 10:08 AM Sean M. Law @.***> wrote: Setting aside the complexity and having not thought about it in detail, I like and am excited about this! I see potential here — You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub <#4098 (comment)>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTAKCGMECYYVNGXGJNLSF6NQJANCNFSM4Q3NNFTQ .
So, this doesn't revolve around a particular data use case but, internally, I've certainly encountered times where one or more small teams (say, 5-10 people) could benefit from having access to a small, distributed dask cluster but on premise (without kubernetes, raw RHEL instance). So, the jobs that they'd have would be in the "less than 30 minutes range" and they could use some or all of the workers. This is strictly for ad-hoc work to allow the team to have quick access to compute when needed (once in a while). Again, I haven't thought this through thoroughly so I'm sure somebody is going to give me a hard time and tell me that there are better solutions (most of which tend to be more for production than for ad-hoc jobs). Of course, I acknowledge that we are approaching reinventing an HPC queueing system.
I wonder if dask-ssh would be good for this use case.
On Tue, Sep 15, 2020 at 10:38 AM Sean M. Law [email protected] wrote:
Is there an application that you have in mind Sean? Or is your excitement of a more general nature? … <#m_-5644238058435863269_> On Tue, Sep 15, 2020 at 10:08 AM Sean M. Law @.***> wrote: Setting aside the complexity and having not thought about it in detail, I like and am excited about this! I see potential here — You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub <#4098 (comment) https://github.com/dask/distributed/pull/4098#issuecomment-692850391>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTAKCGMECYYVNGXGJNLSF6NQJANCNFSM4Q3NNFTQ .
So, this doesn't revolve around a particular data use case but, internally, I've certainly encountered times where a small team (say, 5-10 people) could benefit from having access to a small, distributed dask cluster but on premise (without kubernetes, raw RHEL instance). So, the jobs that they'd have would be in the "less than 30 minutes range" and they could use some or all of the workers. This is strictly for ad-hoc work to allow the team to have quick access to compute when needed (once in a while). Again, I haven't thought this through thoroughly so I'm sure somebody is going to give me a hard time and tell me that there are better solutions (most of which tend to be more for production than for ad-hoc jobs).
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub https://github.com/dask/distributed/pull/4098#issuecomment-692866790, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTDR7M2LO5PX6LZJDADSF6RANANCNFSM4Q3NNFTQ .
I wonder if dask-ssh would be good for this use case. On Tue, Sep 15, 2020 at 10:38 AM Sean M. Law [email protected] wrote: … Is there an application that you have in mind Sean? Or is your excitement of a more general nature? … <#m_-5644238058435863269_> On Tue, Sep 15, 2020 at 10:08 AM Sean M. Law @.***> wrote: Setting aside the complexity and having not thought about it in detail, I like and am excited about this! I see potential here — You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub <#4098 (comment) <#4098 (comment)>>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTAKCGMECYYVNGXGJNLSF6NQJANCNFSM4Q3NNFTQ . So, this doesn't revolve around a particular data use case but, internally, I've certainly encountered times where a small team (say, 5-10 people) could benefit from having access to a small, distributed dask cluster but on premise (without kubernetes, raw RHEL instance). So, the jobs that they'd have would be in the "less than 30 minutes range" and they could use some or all of the workers. This is strictly for ad-hoc work to allow the team to have quick access to compute when needed (once in a while). Again, I haven't thought this through thoroughly so I'm sure somebody is going to give me a hard time and tell me that there are better solutions (most of which tend to be more for production than for ad-hoc jobs). — You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub <#4098 (comment)>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AACKZTDR7M2LO5PX6LZJDADSF6RANANCNFSM4Q3NNFTQ .
It depends on the team. The teams that I'm thinking of are tech savvy business analysts that are stellar at pulling data with SQL but may only be interested/capable of submitting data to in a form via an API endpoint. There's almost a muddy transition area where they need to be able to have access to the compute power before they'll fully embrace just committing to learning programming. 🤷♂️
I was talking with a group last week who wanted to use Dask for production workloads
As a member of that group, @mrocklin I greatly appreciate you trying this out—thank you! But after a bit of thought (though I haven't tested it), I also don't think it's the right solution for our use-case.
Users typically submit ~20,000 dask tasks to the system per job, and we're often processing ~100 jobs/min. Our concern with a single Scheduler was also whether it could reliably handle 2 million tasks churning per minute—at some point, the scheduler might become the limit on the total number of tasks in the system, limiting horizontal scalability.
With this design, every scheduler still knows about every task in the system, so that (again, untested) limitation doesn't go away. I also wonder what would happen as you grow the number of schedulers to the 10s or 100s. The need to communicate every update to 100 schedulers could add meaningful tail latencies, and also increases the potential for transient comm failures, which would warrant more granular error-handling code, and perhaps lead to questions about wanting a distributed consensus algorithm instead, and so on. If this strategy is only effective with, say, max of 5 schedulers, then you're still bottlenecked, just with a wider neck (though if it's much wider, that's still helpful).
running multiple clusters behind a load balancer
is the better solution for us I think. We might get slightly worse cost-efficiency, and ensuring load is actually balanced between the clusters could be tricky, but ultimately I think we'd get better scalability and availability.
Basically I agree with @jcrist:
the support for "multiple schedulers" may confuse users who may think this provides scheduler redundancy and HA, when it doesn't really
This seems like a clever and relatively straightforward change, but I have a feeling the ways in which it'll work well are limited, and it'll invite people to use it in all sorts of ways that won't work well.
@mrocklin Thanks for your solution.
@fjetter First let me share the use case in my company. When we use Dask cluster on production, we need to make sure the high availability. Current deployment solution uses only one scheduler and it is hard to accept on production about HA. We try to start multiple workers on the same pod but the reason why we do this is because the worker can only connect one scheduler and we have to.
May I know there is any solution about Dask HA on production?
May I know there is any solution about Dask HA on production?
To my knowledge there is no dask-native solution for this, yet. We can handle worker failures but the scheduler is still a singleton head node we rely on. Introducing a second scheduler as proposed in this PR is not a solution to this problem as discussed above.