kafka-connect-jdbc
 kafka-connect-jdbc copied to clipboard
kafka-connect-jdbc copied to clipboard
Adding support for Snowflake dialect using merge table for upserts.
This is purposed implementation for issue #698
Implementing snowflake database dialect is straightforward. However, poor performance was encountered when upserting large batches of rows (e.g., approximately 3 seconds per row). To mitigate the poor performance of upserts, the rows to be upserted are first inserted to a temporary table, then then temporary table is upserted into the target table.
Summary of changes:
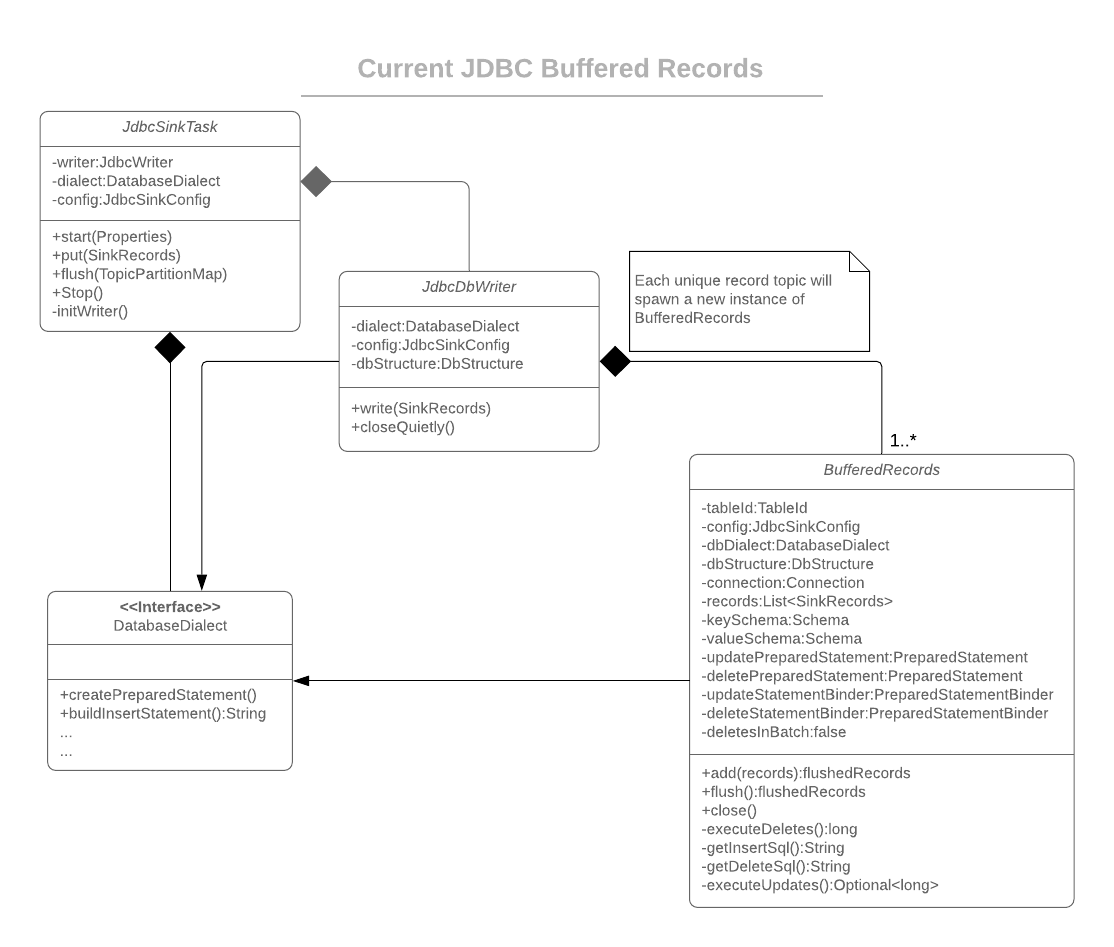
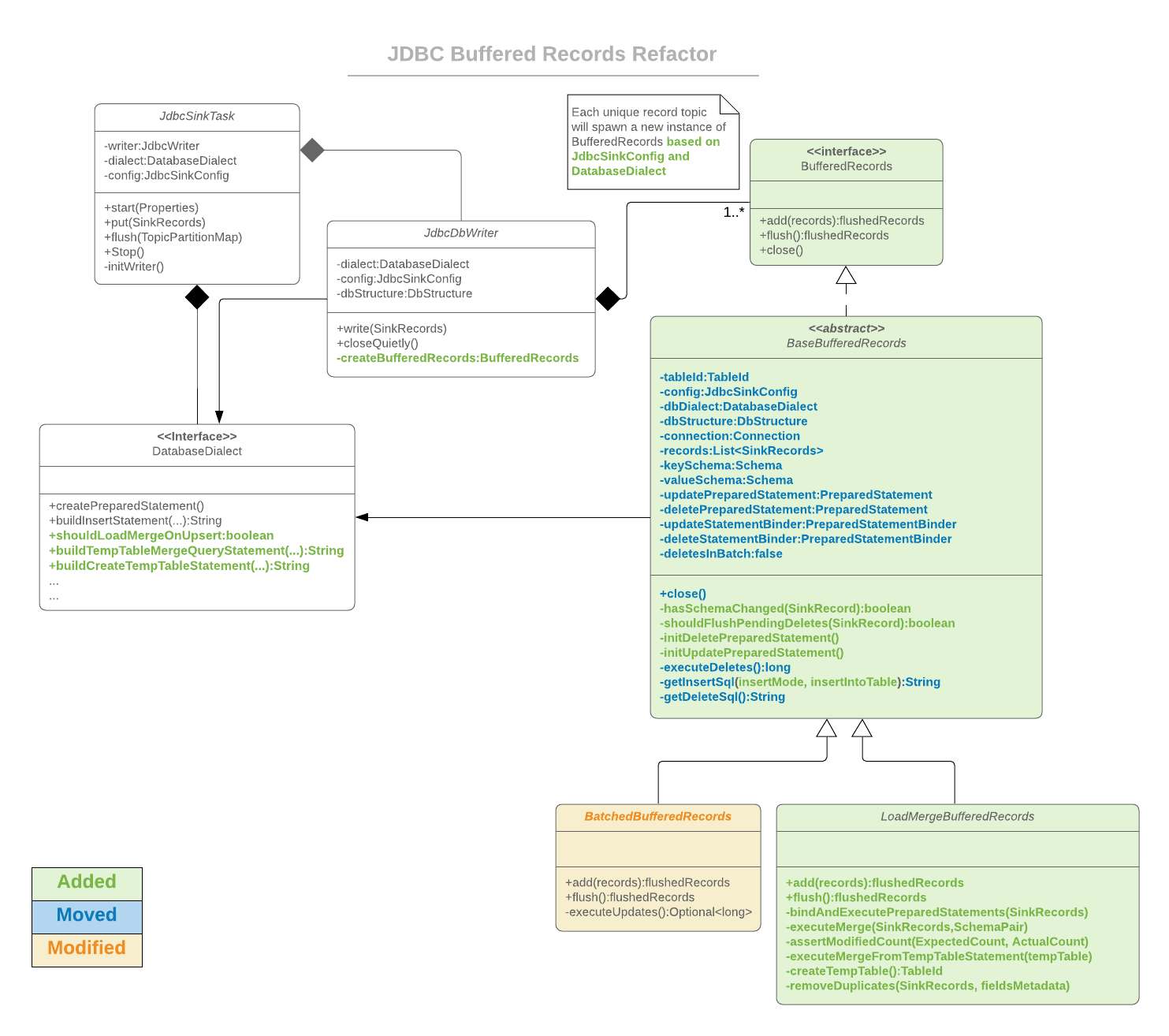
BufferedRecords
-Added interface BufferedRecords to be an interface contain method headers for add, flush, and close.
-Added abstract class BaseBufferedRecords to contain shared logic belonging to all inherited BufferedRecords types.
-Renamed old BufferedRecords class to BatchedBufferedRecords. Logic remains the same however some calls have been cleaned up and moved to base class.
-Added new LoadMergeBufferedRecords class to handle upsert classes where it is more efficient to use the temporary table / merging transitions to land records.
JdbcDbWriter
-Added method to decide on which BufferedRecords type to use based off JdbcSinkConfig and DatabaseDialect.
DatabaseDialect
-Added Snowflake database dialect
-Added method to return wither merge loading on upserts should be used.
-Added method to return a create temp table query string.
-Added method to return a create temp table merge statement query string.
The existing behavior of BufferedRecords renamed to BatchedBufferedRecords is preserved and is performed by default. Individual SinkRecords are processed individually as they are added; detecting changes in schema, records flagged for deletion, or if enough batch limit was reached. In any of those events, a flush is triggered where all pending records are bound to the relevant prepared statement object and then executed. This process will continue until all remaining SinkRecords have been processed.
The new LoadMergeBufferedRecords logic flow is similar to BatchedBufferedRecords' when triggering flushes in response to schema changes, flagged deletes, and exceeding batch limits. The 'LoadMergeBufferedRecords differs by using a temporary table to insert rows and then upsert the contents of the temporary table to the target table. This new behavior is only triggered for dialects that indicate the capability and if the sink is configured to perform upserts. It should be noted that this flow is only supported on upserts and on database dialects that support it (Currently only Snowflake and SqlLite).
It looks like @Davidtedwards2017 hasn't signed our Contributor License Agreement, yet.
The purpose of a CLA is to ensure that the guardian of a project's outputs has the necessary ownership or grants of rights over all contributions to allow them to distribute under the chosen licence. Wikipedia
You can read and sign our full Contributor License Agreement here.
Once you've signed reply with [clabot:check] to prove it.
Appreciation of efforts,
clabot
@confluentinc It looks like @Davidtedwards2017 just signed our Contributor License Agreement. :+1:
Always at your service,
clabot
@Davidtedwards2017, thank you for the hard work and contribution!
A challenge we have with merging new dialects is that in order to fully support them, we need integration tests that validate end-to-end functionality. I understand this is especially challenging with connectors to cloud services, which require shared accounts, and typically cost money to operate, even for testing.
For Snowflake, specifically, we highly recommend using the connector developed by Snowflake: https://docs.snowflake.net/manuals/user-guide/kafka-connector.html. This connector will soon also be available on Confluent Hub!
I am very interested in this functionality. I understand the problem with integration testing, however, the connector developed by Snowflake only loads the raw message data, which leaves many problems unsolved. The functionality of this PR goes much further than that. Is there any path forward for this? @Davidtedwards2017 do you have any ideas as to how to workaround this integration testing limitation?
@jfinzel what are the problems that are unsolved with the Kafka connector? Many Snowflake customers use it for a schema on read approach, keeping the raw data decoupled from processed data, which ensures the connector does not error when Kafka topic structure changes. Some customers use the Snowflake JDBC driver to load topics to Snowflake in a normalized manner, so schema on write approach.
I love this solution and was finding myself writing something quite similar to address the exact same problem. I would love to see this actually release so it could be used.
As the primary issue to merging(post a conflict resolution) is the ability to integration test this snowflake connection, what if this solution was broken up into parts. The advancements to batched records and for dialects to be able to extend them could come into this main project along with all their tests. The SnowflakeDialect could be left unmerged but instead be available in a separate standalone repository.
See https://github.com/confluentinc/kafka-connect-jdbc/blob/master/src/main/java/io/confluent/connect/jdbc/dialect/DatabaseDialectProvider.java, as Dialect providers are brought in using Java's Service Provider Api, any individual who wishes to make use of the SnowflakeDialect could bring it in as a separate jar and place it on the kafka-connect jdbc classpath.
Thank you for your submission! We really appreciate it. Like many open source projects, we ask that you sign our Contributor License Agreement before we can accept your contribution.
Tyler Edwards seems not to be a GitHub user. You need a GitHub account to be able to sign the CLA. If you have already a GitHub account, please add the email address used for this commit to your account.
You have signed the CLA already but the status is still pending? Let us recheck it.