confluent-kafka-python
 confluent-kafka-python copied to clipboard
confluent-kafka-python copied to clipboard
consumer heartbeat error response in state up
Description
I have a topic with 24 partitions which is produced about 1000 messages/sec. The cosumer-commit-offset is manual.
1.After starting consumer, the Broker logs : "Preparing to rebalance group····· Stabilized group ····· Assignment received from leader for group ·····" about every 2 minutes all the time.
- The debug log of consumer is:
%7|1650878105.949|OFFSET|rdkafka#consumer-1| [thrd:main]: Topic speech-xxx [21]: stored offset 3888754141, committed offset 3888751506: setting st ored offset 3888754141 for commit %7|1650878105.949|OFFSET|rdkafka#consumer-1| [thrd:main]: Topic speech-xxx [22]: stored offset -1001, committed offset -1001: not including in com mit %7|1650878105.949|OFFSET|rdkafka#consumer-1| [thrd:main]: Topic speech-xxx [23]: stored offset -1001, committed offset -1001: not including in com mit %7|1650878105.949|COMMIT|rdkafka#consumer-1| [thrd:main]: GroupCoordinator/1: Committing offsets for 14 partition(s): manual %7|1650878105.949|OFFSET|rdkafka#consumer-1| [thrd:main]: GroupCoordinator/1: Enqueue OffsetCommitRequest(v1, 14/24 partition(s))): manual %5|1650878105.949|REQTMOUT|rdkafka#consumer-1| [thrd:GroupCoordinator]: GroupCoordinator/1: Timed out HeartbeatRequest in flight (after 10326ms, timeout #0): possibly held back by preceeding OffsetCommitRequest with timeout in 46873ms %7|1650878105.949|REQERR|rdkafka#consumer-1| [thrd:main]: GroupCoordinator/1: HeartbeatRequest failed: Local: Timed out: actions Retry %7|1650878105.949|HEARTBEAT|rdkafka#consumer-1| [thrd:main]: Group "anti-xxx" heartbeat error response in state up (join state started, 24 partition(s) assigned): Local: Timed out %7|1650878105.949|HEARTBEAT|rdkafka#consumer-1| [thrd:main]: Heartbeat failed: _TIMED_OUT: Local: Timed out %7|1650878105.949|REBALANCE|rdkafka#consumer-1| [thrd:main]: Group "anti-xxx" is rebalancing in state up (join-state started) with assignment: Local: Timed out %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Library pausing 24 partition(s) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-room-audiofile [0]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Pause speech-xxx [0] (v3) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-xxx [1]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Pausespeech-xxx [1] (v3) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-xxx [2]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Pause speech-xxx [2] (v3) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-xxx [3]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Pause speech-xxx [3] (v3) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-room-audiofile [4]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %7|1650878105.949|PAUSE|rdkafka#consumer-1| [thrd:main]: Pause speech-room-audiofile [4] (v3) %7|1650878105.949|BARRIER|rdkafka#consumer-1| [thrd:main]: speech-room-audiofile [5]: rd_kafka_toppar_op_pause_resume:2311: new version barrier v3 %4|1650878105.949|REQTMOUT|rdkafka#consumer-1| [thrd:GroupCoordinator]: GroupCoordinator/1: Timed out 1 in-flight, 0 retry-queued, 0 out-queue, 0 partially-sent requests
Also, this group-id has lag as 100,167,242 . Restart this consumer program has no help. so,is there some reasons for this ?
How to reproduce
the codes of consumer is below:
while 1:
try:
msg = kafka_client.poll(timeout=1.0)
if not msg:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
time.sleep(0.1)
continue
else:
print("Consumer error: {}".format(msg.error()))
else:
queue.put(msg.value()) # multiprocessing.Queue
count += 1
if count > 100:
kafka_client.commit()
count = 0
Checklist
Please provide the following information:
- [x] confluent-kafka-python and librdkafka version (('1.0.0', 1048576)and ('1.0.0', 16777471)):
- [x] Apache Kafka broker version: 0.11.0.2
- [x] Client configuration:
{ "auto.offset.reset": "latest", "fetch.message.max.bytes": "10485760", "enable.auto.commit": "false",} - [x] Operating system: centos 7.4 with 3.10.0 kernel , python version: 2.7.12
- [x] Provide client logs (with
'debug': 'all'as necessary) - [x] Provide broker log excerpts
- [ ] Critical issue
suggest upgrading the client. after a quick look, i believe this might be a head of line blocking issue that was resolved after v1.0
Thanks a million. I add "time.sleep(0.5)" after "kafka_client.commit()" in the code. After restarting the consumer , it seems to be well. So, Is it actually caused by head of line blocking?
time.sleep(0.5) should not change behavior. did you upgrade to the latest client version?
The version of PYTHON is 2.7.12, so I upgrade the client to 1.6.0. But, the problem still exists.
In addition,I find the broker always has many establieshed connections with large value of "Recv-Q" .
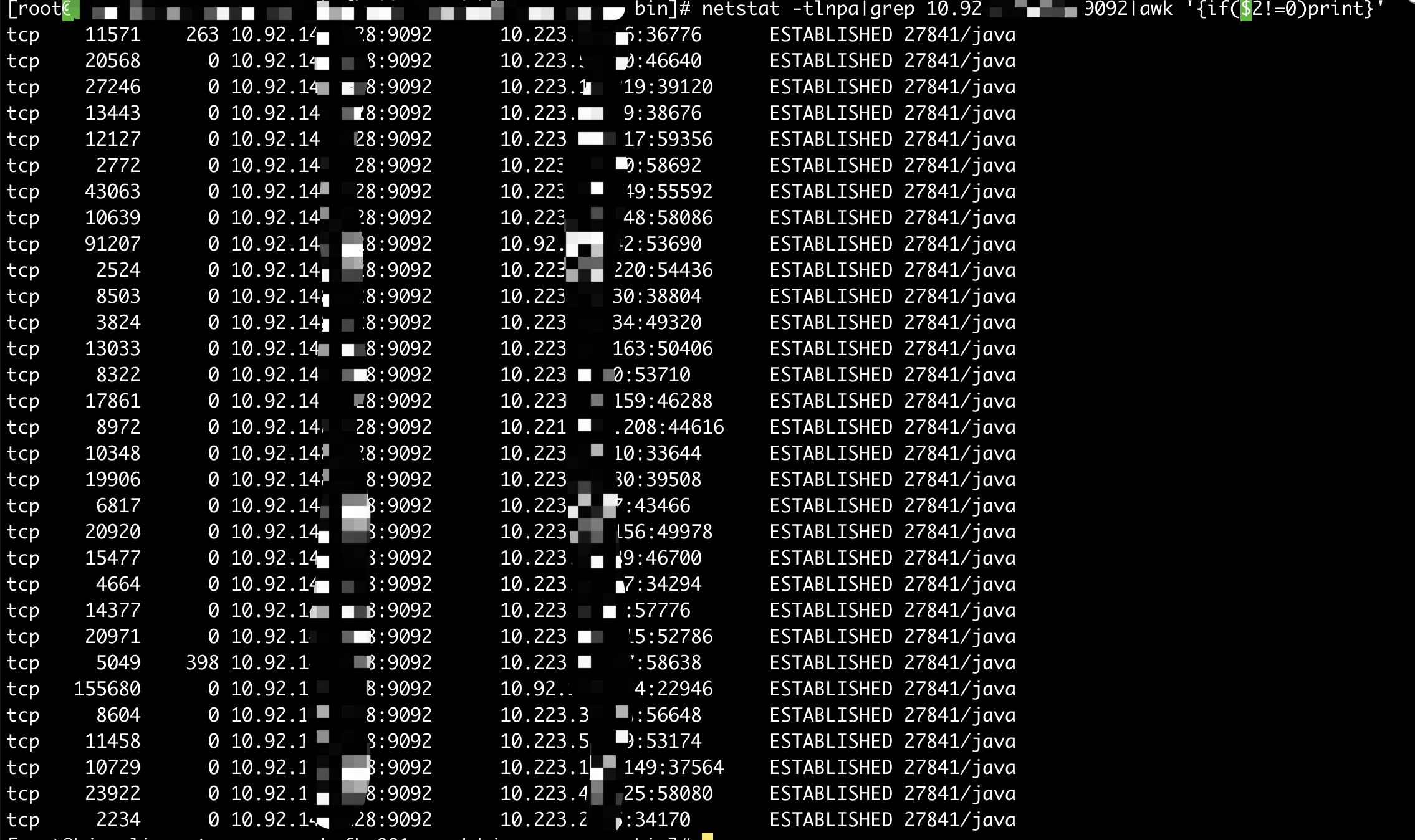
closing - we can investigate further if the issue presents in the latest version.