ComfyUI
 ComfyUI copied to clipboard
ComfyUI copied to clipboard
DeepFloyd IF
Is this model significant enough to merit a built-in set of ComfyUI nodes or should they be made as extensions
For now it seems like more of a research model than something that is actually useful in practice. If people actually start using it I'll consider adding support.
For now it seems like more of a research model than something that is actually useful in practice. If people actually start using it I'll consider adding support.
It can be used to create unique images too. Just imo, at least, it's so uncanny valley. This is the best image I've seen from it actually, but it's all blown out, from expected input

For me, it seemed quite unimpressive, apart from text handling, which at least for some cases, can be approximated using control net. Same way with SD2.X, I just fail to see much advantage. Well maybe better text/prompt handling, but for high res stuff nether of them seem all that better than what seems to be possible with SD1.5 models.
the 64x64 module for deepfloydIF seems to be really good compared to baseline SD, consistently has better formation than resizing SD 512x512 image to 64. The 2 upscalers aren't too impressive still. My use case would be to use IF for 64x64 image, then use stable diffusion for x4 upscale 64 -> 256 -> 1024. That would be pretty cool IMO
it just need the comunity to create some chekpoints for it , and then it will boom , hopfully -- also any one have any idea about its speed and ram usage compared to SD
it just need the comunity to create some chekpoints for it , and then it will boom , hopfully -- also any one have any idea about its speed and ram usage compared to SD
If the sole benefit is sorta better text, I don't know if that's going to happen. I mean we got Blended Diffusion which has been able to do this for awhile, AND can do img2img actually changing bits without changing the rest like hair color, but it's sat stagnant. It's img2img abilities alone are amazing. But no one training fine-tunes or anything
That's the momentum advantage, SD15 has crazy ass momentum with all custom models and merges and loras. And I actually think it "makes smarter" (models themselves), as obviously the amount of training those models are exposed to are definitely bigger than the newer ones. Also a reason why I'm not keen on abandoning it, and looking into ways to make it be able to gent higher res images (with some success). Cause I see it definitely can. So far those new models were somehow extremely underwhelming to me for the most part. Somewhere I read that SD is strongly limited by text understanding, and is seems to be the case, so I would be more excited it somehow someone could "franken-combine" SD1.5 with say vicunia or other open LLM on a deeper level, but that I guess is somewhere in viciny of impossible, implossible or extremely weirdly hard.
That's the momentum advantage, SD15 has crazy ass momentum with all custom models and merges and loras. And I actually think it "makes smarter" (models themselves), as obviously the amount of training those models are exposed to are definitely bigger than the newer ones. Also a reason why I'm not keen on abandoning it, and looking into ways to make it be able to gent higher res images (with some success). Cause I see it definitely can. So far those new models were somehow extremely underwhelming to me for the most part. Somewhere I read that SD is strongly limited by text understanding, and is seems to be the case, so I would be more excited it somehow someone could "franken-combine" SD1.5 with say vicunia or other open LLM on a deeper level, but that I guess is somewhere in viciny of impossible, implossible or extremely weirdly hard.
ViTl14 that SD 1.4/1.5 uses is old. It wasn't even much better for Disco Diffusion. They honestly should have waited the 3 months to train on one of the bigger language models that got released like ViTlH.
I made a couple nodes for IF. Just following the huggingface doc so diffusers are required, not really a true implementation but it works (most of the time).
Text encoder needs a bit above 8GB of VRAM loaded in 8bit, so the whole thing should be able to run on 10GB cards. Not sure if it can be brought down further or if my optimizations even do anything. Loading the fp16 weights since Windows dlls for bitsandbytes floating around don't work with 0.38.
Workflow's in the image, stage 3 doesn't work with the t5 encoder so you have to pass it normal strings. Might update the readme later if there's any interest, cheers.
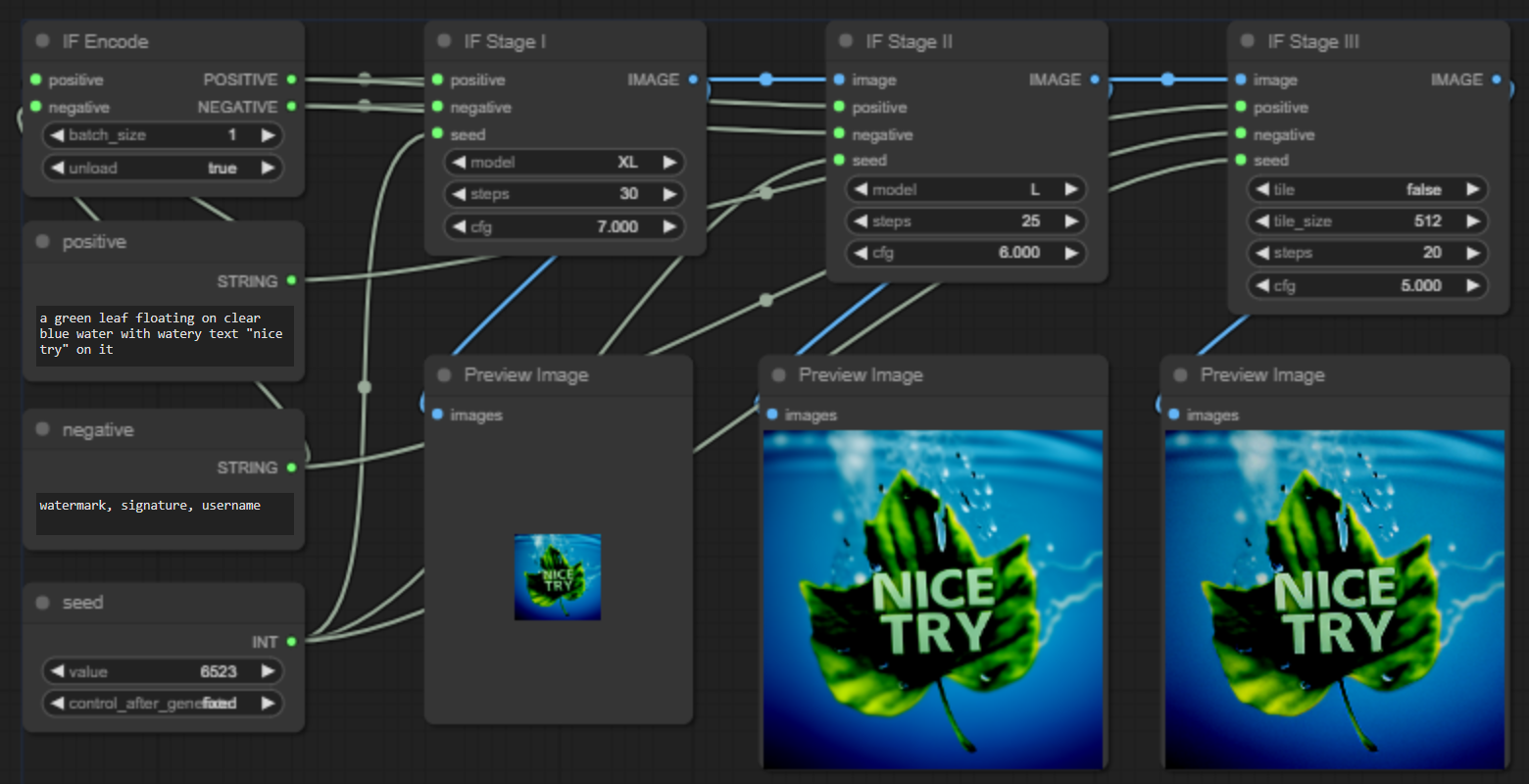

//Models are saved in .cache, it's a pain, I know, but the whole repo is such a mess of different versions in the same branch I have no idea how to do it better.
I made a couple nodes for IF. Just following the huggingface doc so diffusers are required, not really a true implementation but it works (most of the time).
Text encoder needs a bit above 8GB of VRAM loaded in 8bit, so the whole thing should be able to run on 10GB cards. Not sure if it can be brought down further or if my optimizations even do anything. Loading the fp16 weights since Windows dlls for bitsandbytes floating around don't work with 0.38.
Workflow's in the image, stage 3 doesn't work with the t5 encoder so you have to pass it normal strings. Might update the readme later if there's any interest, cheers.
//Models are saved in .cache, it's a pain, I know, but the whole repo is such a mess of different versions in the same branch I have no idea how to do it better.
Diffusers is a mess. It's just a wrapper for anything they find that may be used by people it seems. And in doing so, created a very slow and heavy API. The timing just traverse through the API to start diffusions and stuff is bad.
Would be cool to see Blended Stable Diffusion in ComfUI. It's like 95% lighter, and was doing the same thing as IF months beforehand. It is made for img2img altering, can diffuse text, etc.
It just has no exposure cause not under the umbrella with Stability.AI stuff and HF. Maybe we could help.
@WASasquatch the main benefit of diffusers/transformers is integration. you can easily install the libs and run mostly any model out there. but i agree that it comes with peformance costs. Supporting different versions of stable diffusion/other models is a pain and so far HF has been really fast implementing new stuff.
I made a couple nodes for IF. Just following the huggingface doc so diffusers are required, not really a true implementation but it works (most of the time).
Text encoder needs a bit above 8GB of VRAM loaded in 8bit, so the whole thing should be able to run on 10GB cards. Not sure if it can be brought down further or if my optimizations even do anything. Loading the fp16 weights since Windows dlls for bitsandbytes floating around don't work with 0.38.
Workflow's in the image, stage 3 doesn't work with the t5 encoder so you have to pass it normal strings. Might update the readme later if there's any interest, cheers.
//Models are saved in .cache, it's a pain, I know, but the whole repo is such a mess of different versions in the same branch I have no idea how to do it better.
Can you share your workflow?