ComfyUI
 ComfyUI copied to clipboard
ComfyUI copied to clipboard
[ISSUE] Errors when trying to use CLIP Vision/unCLIPConditioning
Hey,
I've spent quite some time looking at your example on the basic usage of this, I've tried loading in the CLIP model alone, and just using one in a SD model, in both instances I get the same error output in CLI.
Here's my setup -
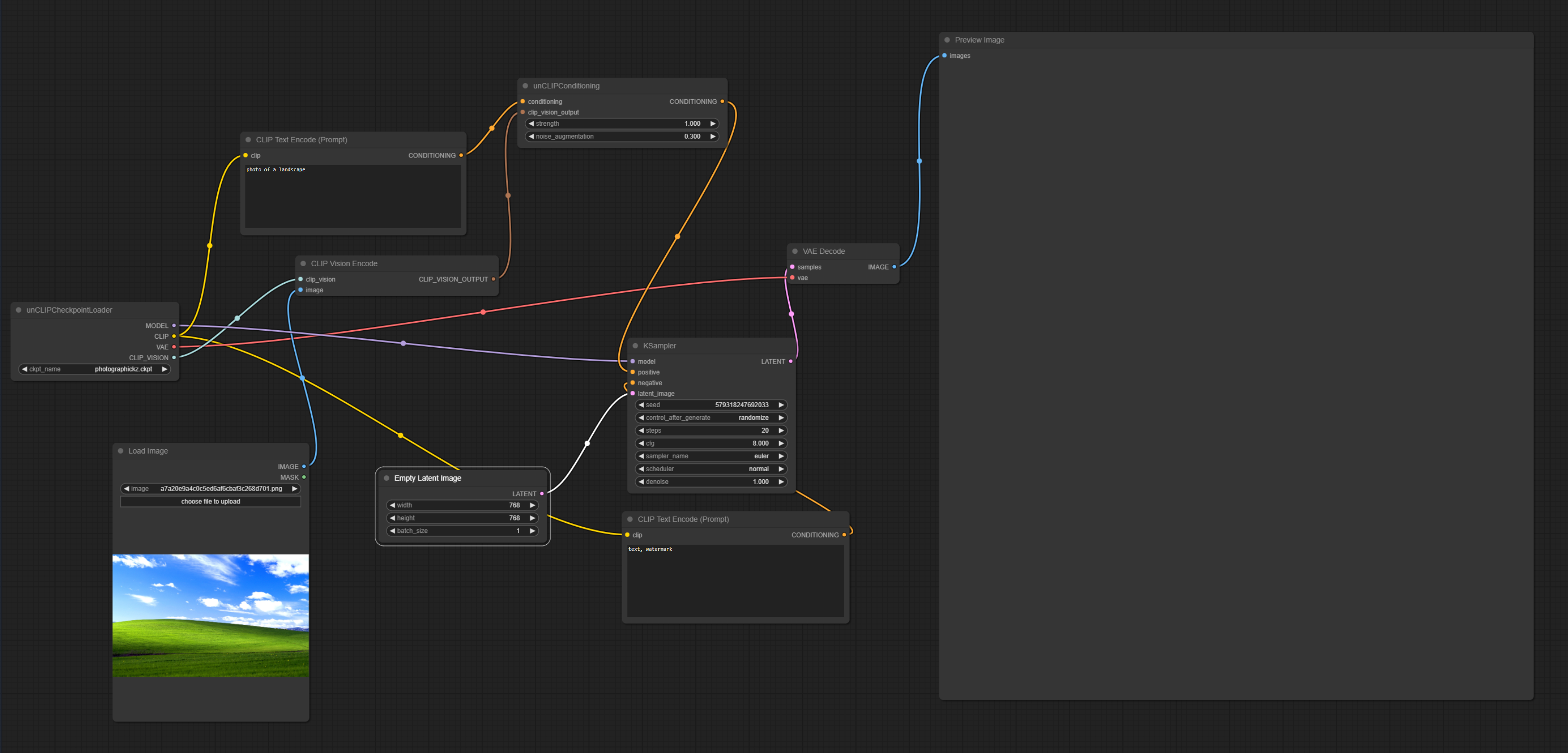
Here's the error I'm getting -
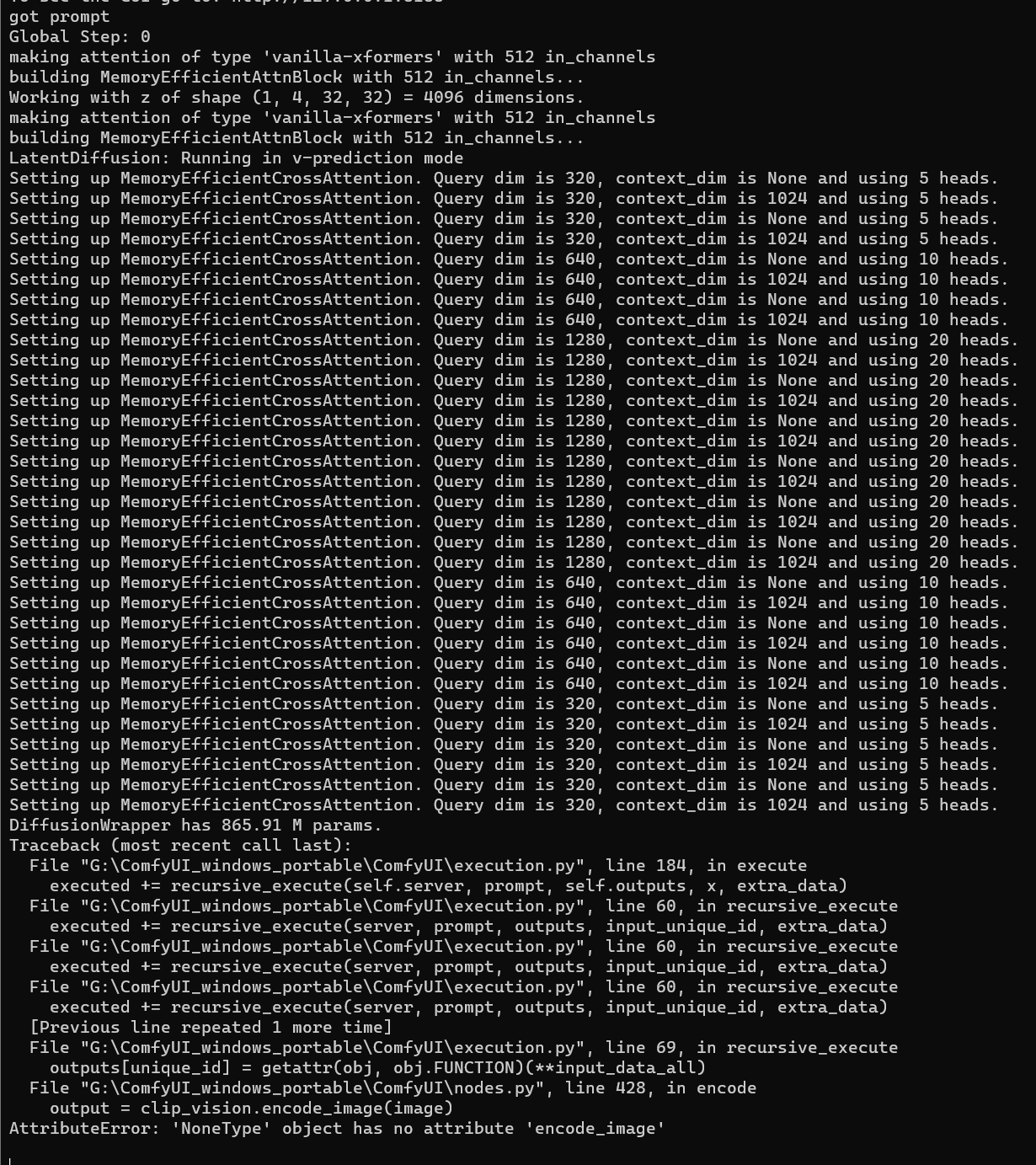
That means your checkpoint isn't an unCLIP checkpoint: it doesn't contain weights for the CLIPVision model.
I suspected that might be the case.
Assuming I just try to load unCLIP independently from the SD model, should this be the correct checkpoint? https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip/blob/main/sd21-unclip-h.ckpt
Because I'm getting the same issue with that too.
Yaou can't load the unCLIP independently because unCLIP models are different from regular SD models.
In which case, what is the correct usage? I believe the node tree is correct already.
How does one create a model that is compatible with unclip?
You can create some from SD2.1 checkpoints by merging: (sd21-unclip-h.ckpt - v2-1_768-ema-pruned.ckpt) + your_sd2.1_checkpoint
This is how I made these: https://huggingface.co/comfyanonymous/wd-1.5-beta2_unCLIP https://huggingface.co/comfyanonymous/illuminatiDiffusionV1_v11_unCLIP/tree/main
what method are you using to merge?
(not even necessarily full instructions, just need to be pointed in the right direction please)
Are you converting everything to diffusers and just swapping it out, converting back to ckpt/safetensor after?
I have my own simple scripts for merging.
I dump the text encoder and unet weights for the 3 checkpoints and then do: (sd21-unclip-h.ckpt - v2-1_768-ema-pruned.ckpt) + sd2.1_checkpoint on those weights
then I take the sd21-unclip-h.ckpt and replace the text encoder and unet weights with my new merged weights.
Here's one but you'll have to modify it for your use case:
import os
import torch
import safetensors.torch
import sys
unclip_name = "unclip-h"
output_dir = "wd-1.5-beta3_unCLIP"
orig_name = "sd21-{}.ckpt".format(unclip_name)
diff_name = "v2-1_768-ema-pruned.ckpt"
orig_weights = torch.load(orig_name, map_location="cuda:0")["state_dict"]
orig_diff = torch.load(diff_name, map_location="cuda:0")["state_dict"]
os.remove(orig_name)
os.remove(diff_name)
def diff_merge(w1, w2, w3):
if w1.dtype == torch.float16:
w1 = w1.to(torch.float32)
if w2.dtype == torch.float16:
w2 = w2.to(torch.float32)
if w3.dtype == torch.float16:
w3 = w3.to(torch.float32)
return w1 - w2 + w3
with torch.inference_mode():
files = os.listdir()
for x in files:
if x.endswith("fp16.safetensors"):
print(x)
nam = x[:-len("fp16.safetensors")]
new_dict = {}
weights_ = safetensors.torch.load_file(x, device="cuda:1")
os.remove(x)
for ww in weights_:
if ww.startswith("model.") or ww.startswith("cond_stage_model."):
if ww in orig_weights:
temp = weights_[ww].to(orig_weights[ww].device)
new_dict[ww] = diff_merge(orig_weights[ww], orig_diff[ww], temp).to("cuda:1").half()
del temp
else:
print("missing?", ww)
new_dict[ww] = weights_[ww].to("cuda:1").half()
if ww.startswith("first_stage_model."):
new_dict[ww] = weights_[ww].to("cuda:1").half()
for tt in orig_weights:
if tt not in new_dict:
new_dict[tt] = orig_weights[tt].half().to("cuda:1")
safetensors.torch.save_file(new_dict, "{}/{}{}-fp16.safetensors".format(output_dir, nam, unclip_name))
del new_dict
del weights_
My upload speed sucks so I do my model merging on colab or kaggle so that's the reason for the two different cuda devices.