Service proxy causing high CPU usage with ~2.7K services
Hey,
We’re running a Kubernetes cluster with ~150 nodes and ~2.7K services. Each service typically matches one pod. Service endpoints are updated quite often (e.g., due to pod restarts).
Each time a service endpoint is updated, kube-router seems to perform a full resync of services. Due to the number of services, the resync takes ~16 seconds on a m5a.large EC2 instance:

While doing the resync, kube-router aggressively consumes the CPU:
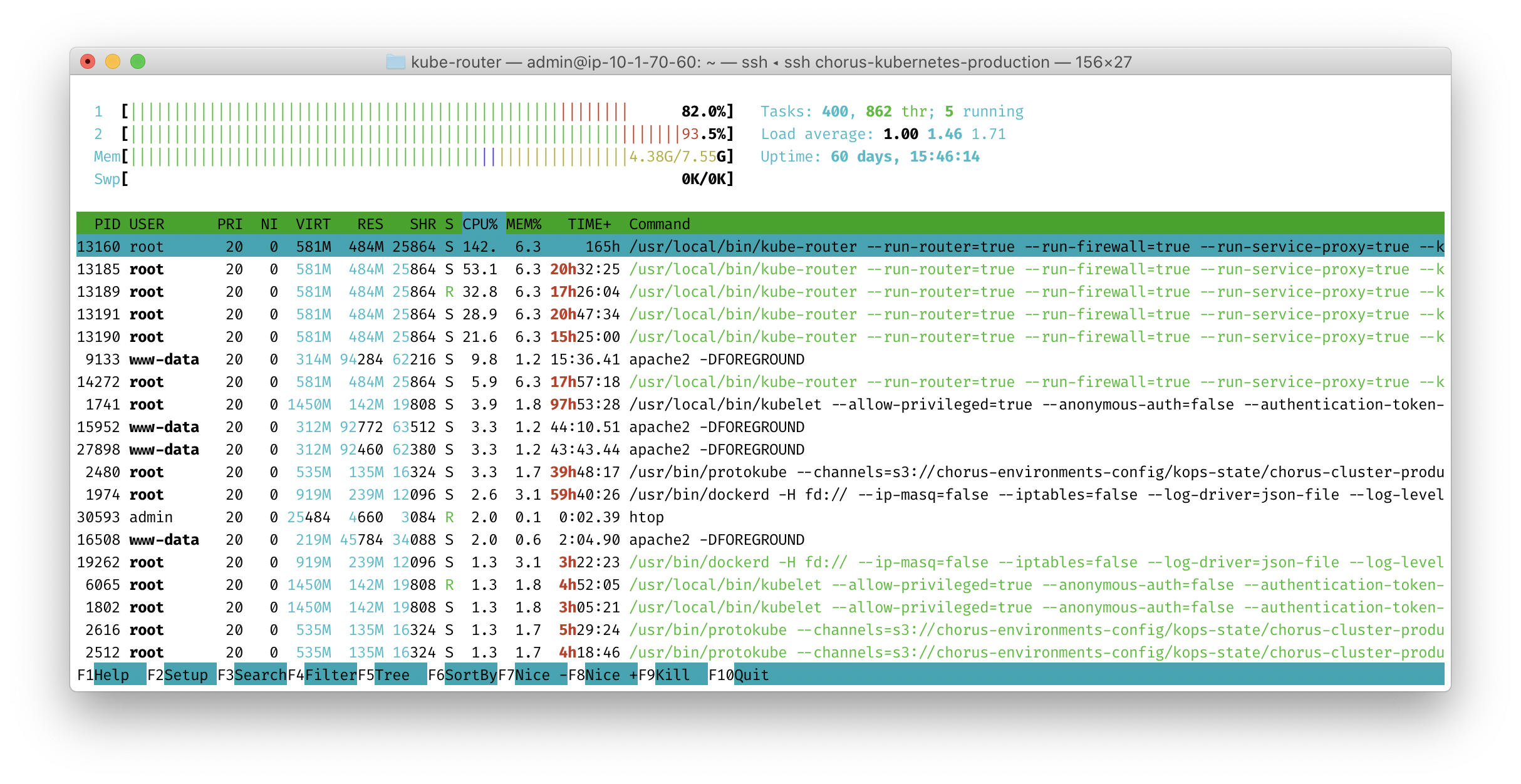
which affects other pods running on that instance.
Is there any way to reduce the CPU usage or make service resyncs happen faster? The ultimate goal is to make sure kube-router doesn’t affect other pods from that node.
(CPU limits are not a solution, unfortunately. We don’t want to apply CPU limits to kube-router because that’d make IPVS resyncs longer, and with long resyncs, we’d start experiencing noticeable traffic issues. E.g. if a service endpoint changes, and it takes kube-router 1 minute to perform an IPVS resync, the traffic to that service will be blackholed or rejected for the full minute.)
Just for the sake of reference, our kube-router configuration is pretty standard:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
k8s-app: kube-router
tier: node
name: kube-router
namespace: kube-system
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kube-router
tier: node
template:
metadata:
creationTimestamp: null
labels:
k8s-app: kube-router
tier: node
spec:
containers:
- args:
- --run-router=true
- --run-firewall=true
- --run-service-proxy=true
- --kubeconfig=/var/lib/kube-router/kubeconfig
- --bgp-graceful-restart
- -v=1
- --metrics-port=12013
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: KUBE_ROUTER_CNI_CONF_FILE
value: /etc/cni/net.d/10-kuberouter.conflist
image: docker.io/cloudnativelabs/kube-router:v0.4.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 20244
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 3
successThreshold: 1
timeoutSeconds: 1
name: kube-router
resources:
requests:
cpu: 100m
memory: 250Mi
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /lib/modules
name: lib-modules
readOnly: true
- mountPath: /etc/cni/net.d
name: cni-conf-dir
- mountPath: /var/lib/kube-router/kubeconfig
name: kubeconfig
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
initContainers:
- command:
- /bin/sh
- -c
- set -e -x; if [ ! -f /etc/cni/net.d/10-kuberouter.conflist ]; then if [
-f /etc/cni/net.d/*.conf ]; then rm -f /etc/cni/net.d/*.conf; fi; TMP=/etc/cni/net.d/.tmp-kuberouter-cfg;
cp /etc/kube-router/cni-conf.json ${TMP}; mv ${TMP} /etc/cni/net.d/10-kuberouter.conflist;
fi
image: busybox
imagePullPolicy: Always
name: install-cni
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/cni/net.d
name: cni-conf-dir
- mountPath: /etc/kube-router
name: kube-router-cfg
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kube-router
serviceAccountName: kube-router
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- effect: NoSchedule
operator: Exists
volumes:
- hostPath:
path: /lib/modules
type: ""
name: lib-modules
- hostPath:
path: /etc/cni/net.d
type: ""
name: cni-conf-dir
- configMap:
defaultMode: 420
name: kube-router-cfg
name: kube-router-cfg
- hostPath:
path: /var/lib/kube-router/kubeconfig
type: ""
name: kubeconfig
templateGeneration: 25
updateStrategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
I can’t test kube-router v1 in production, but, testing locally, v1.0.1 appears to have the same behavior.
Here’s how to reproduce it locally, btw.
Steps to reproduce (with minikube)
-
Start a cluster (if not running already)
minikube start --kubernetes-version=v1.14.10 -
Annotate the node with
kubectl annotate node minikube kube-router.io/pod-cidr=10.0.0.1/24 -
Boot a pod with
kubectl run my-shell --image ubuntu -- bash -c 'sleep 999999999' -
Deploy ~2K services for that pod:
kubectl apply -f https://gist.githubusercontent.com/iamakulov/695fdf0241452c77b2b58f2ecfd0ab38/raw/248ec660e361bc784d6bfe3f6472189125d530be/services-random.yml(Gist)
-
Delete the kube-proxy DaemonSet:
kubectl delete ds kube-proxy -n kube-system -
Deploy kube-router:
kubectl apply -f https://gist.githubusercontent.com/iamakulov/695fdf0241452c77b2b58f2ecfd0ab38/raw/d7d1c78e672503c3bec6bb730a3bdc2ccb4a6706/kube-router.yml # Note: the kube-router yaml above is modified to work with minikube # It also has a 800m CPU limit applied to make it easier to repro the issue on fast devices(Gist)
-
Wait for
kube-routerto start, stream its logs, and edit any service from the list of deployed services:kubectl edit svc my-9973192 # Change targetPort from 3000 to 3001
Observed behavior
The picture is similar for both kube-router v0.4.0 and v1.0.1.
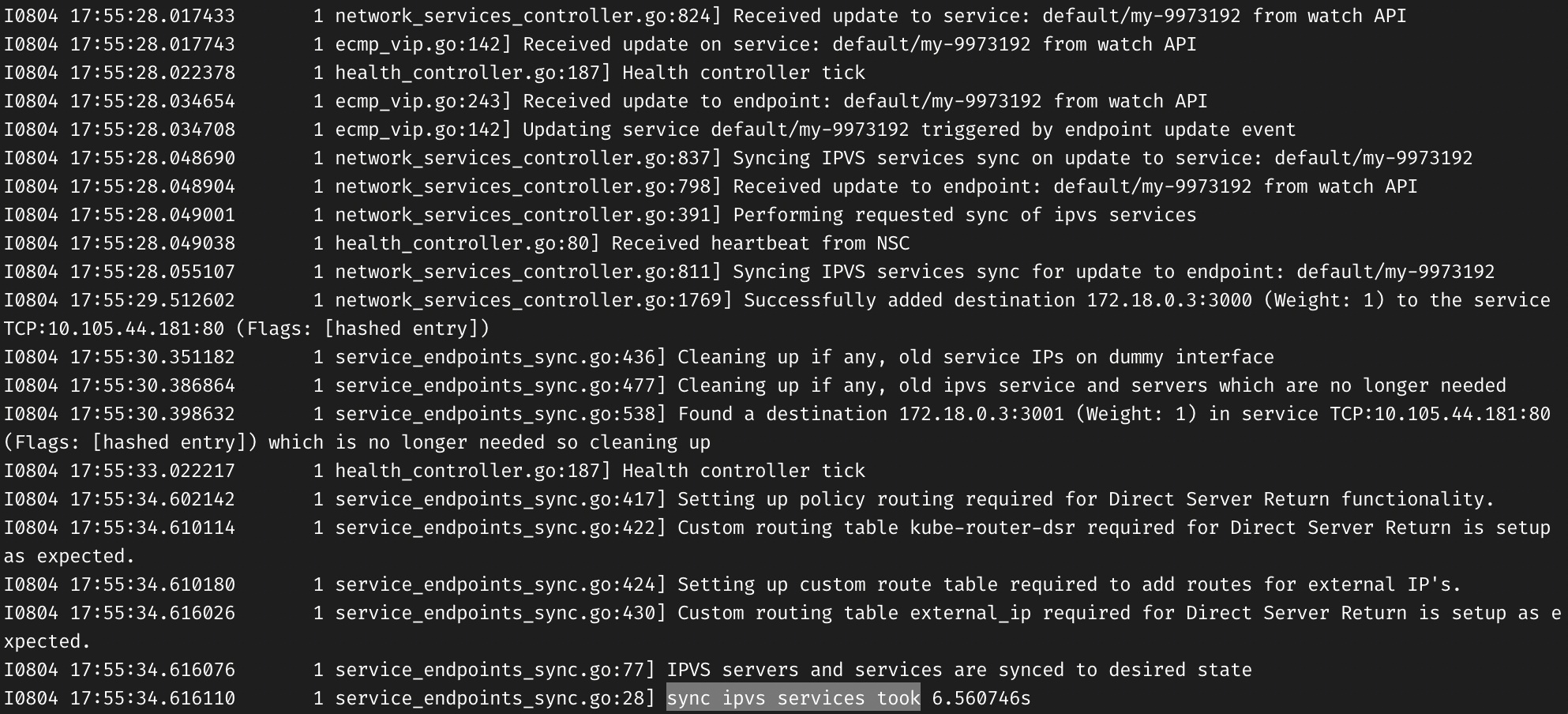
IPVS resync takes ~6 seconds:
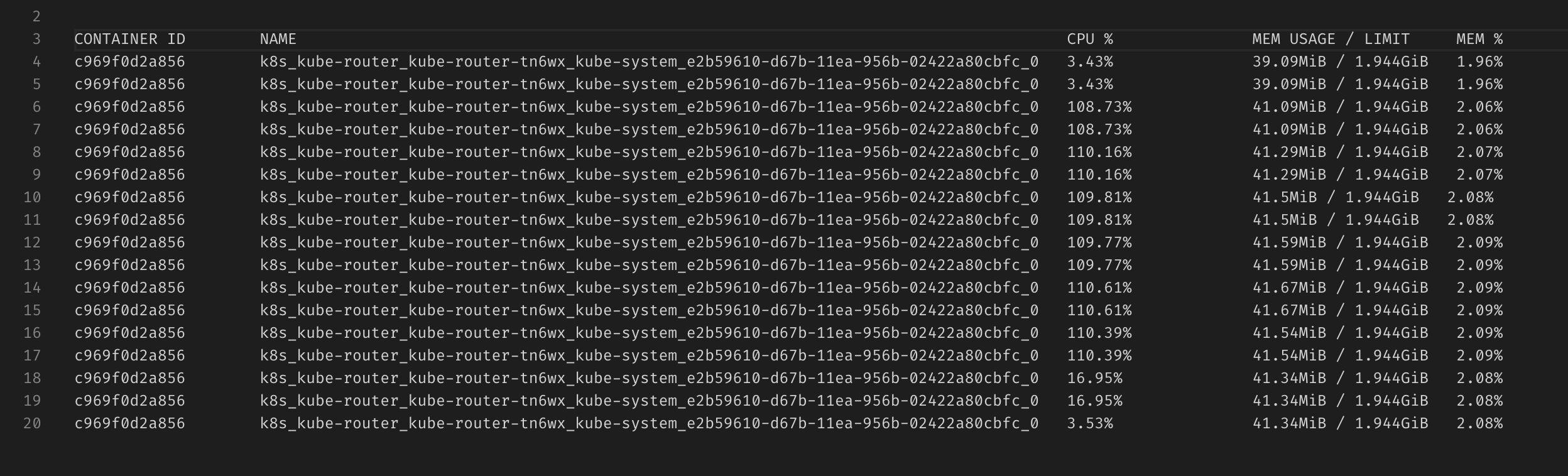
The CPU usage (tracked by docker stats) stays high during the whole duration of the IPVS update:
While I’m trying to figure out how to debug/profile kube-router (not a Go pro :), here’re some high-level timestamps from inside syncIpvsServices():
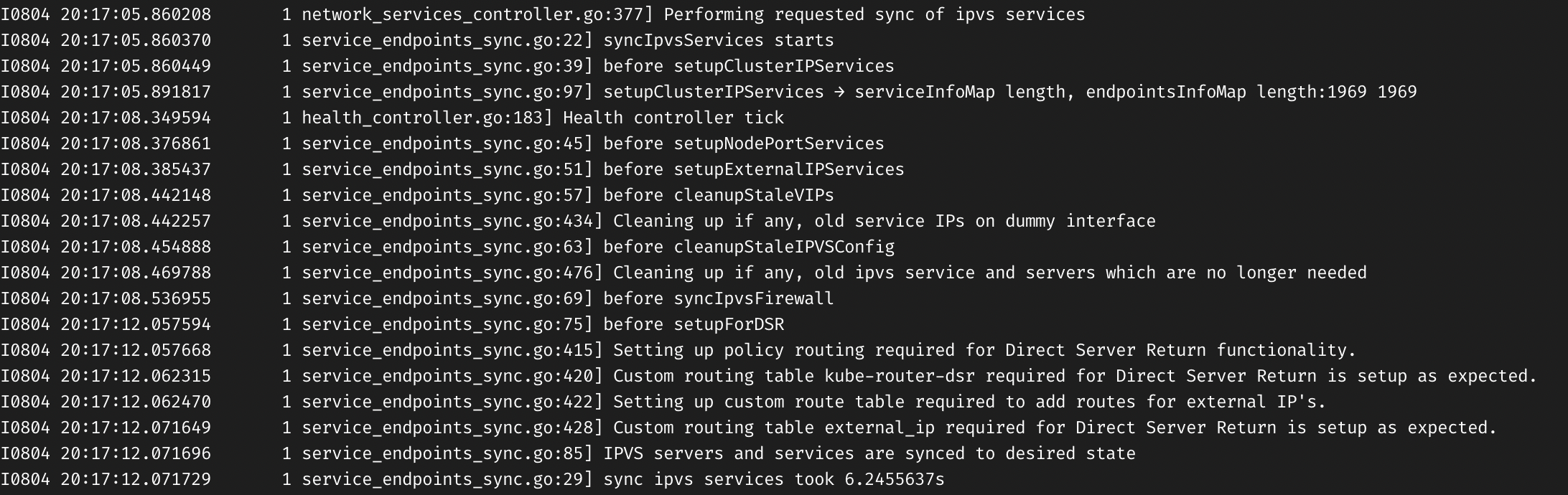
The slowest functions appear to be setupClusterIPServices (2.5s out of 6.2s) and syncIpvsFirewall (3.5s out of 6.2s).
setupClusterIPServicesis slow, perhaps, simply due to algorithmic complexity? Its complexity is O(N^2), and N (in this test case) is ~2000.- Not sure what the bottleneck in
syncIpvsFirewallis yet
Not sure if this helps, but here’s a 15-second CPU trace I captured through pprof which includes the IPVS sync.
Looking further into this.
Here’s the scheduler latency profile generated from the above trace. Most of the time is spent in external exec() calls:
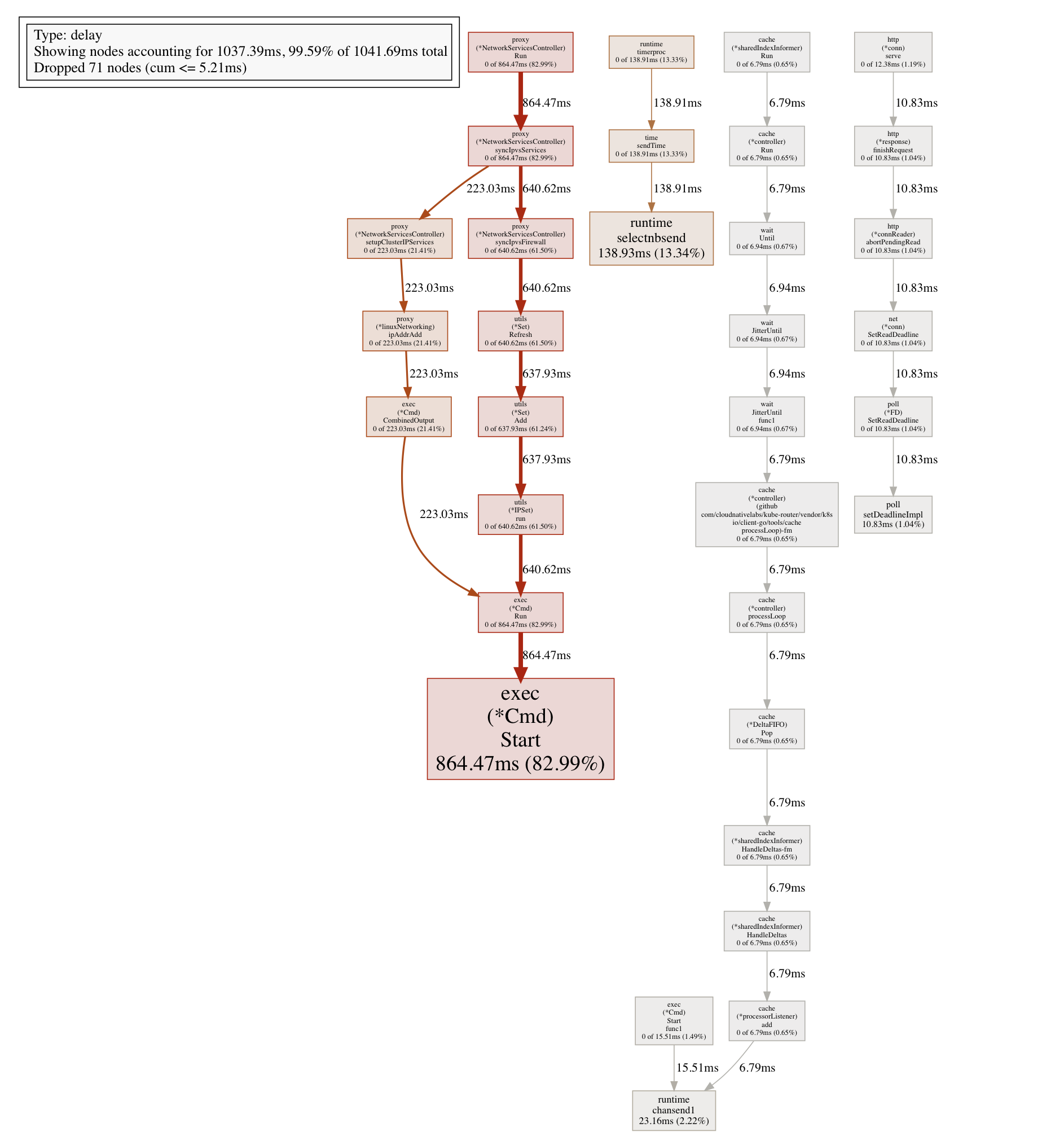
Initially, I assumed I might be misunderstanding the profile (I don’t have any Go debugging experience). However, this actually seems correct.
I’ve tried adding a bunch of log points into syncIpvsFirewall(), and the bottlenecks there are these two Refresh calls:
https://github.com/cloudnativelabs/kube-router/blob/e35dc9d61ef9507902c13f0e7d06b9ea5dc942ce/pkg/controllers/proxy/network_services_controller.go#L704-L714
Each Refresh() call invokes the ipset binary multiple times – once for each Kubernetes service. A single invocation is inexpensive, but 2K invocations add up to ~1.5s (out of ~6s total) for me. And syncIpvsFirewall() calls Refresh() twice (so 1.5s × 2 = 3s).
TBH not sure how to proceed from here. A good solution would be, perhaps, to avoid full resyncs on each change – and, instead, carefully patch existing networking rules. But I don’t know what potential drawbacks this might have, nor am I experienced with Go/networking enough to do such change.
Wait, I might’ve found an easy win!!
ipset supports two ways of loading rules into it:
a) you can call ipset add multiple times, or
b) you can call ipset restore with a list of rules.
The list of rules looks exactly like the list of exec() commands, just without the binary name. E.g.:
create kube-router-ipvs-services- hash:ip,port family inet hashsize 1024 maxelem 65536 timeout 0
add kube-router-ipvs-services- 10.100.7.98,tcp:80 timeout 0
add kube-router-ipvs-services- 10.100.23.110,tcp:80 timeout 0
add kube-router-ipvs-services- 10.107.15.194,tcp:80 timeout 0
add kube-router-ipvs-services- 10.96.235.209,tcp:80 timeout 0
add kube-router-ipvs-services- 10.111.75.75,tcp:80 timeout 0
add kube-router-ipvs-services- 10.102.127.111,tcp:80 timeout 0
add kube-router-ipvs-services- 10.105.77.80,tcp:80 timeout 0
add kube-router-ipvs-services- 10.98.135.77,tcp:80 timeout 0
add kube-router-ipvs-services- 10.97.235.184,tcp:80 timeout 0
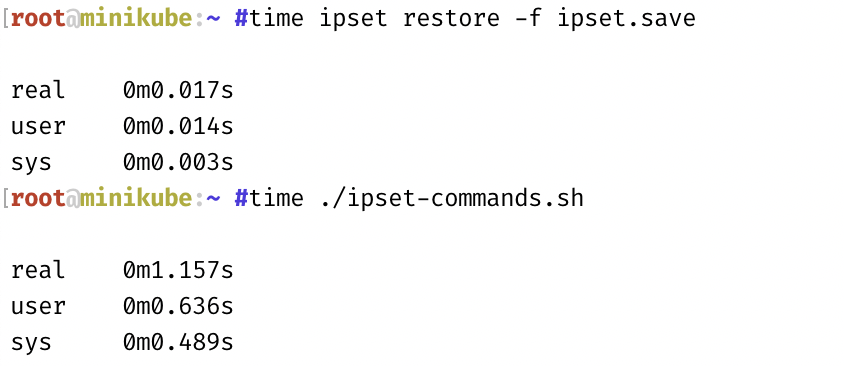
I measured both approaches, and with the same list of rules (but different sets, of course), ipset restore runs two orders of magnitude faster:
That seems like a reasonable approach to me. This is very similar to the approach we intend to take with iptables/nftables for the NPC in 1.2. As a matter of fact it looks like some of the functionality already exists in pkg/utils/ipset.go there are already a Restore() and buildIPSetRestore(), but it doesn't really look like they have been used so far and it probably doesn't do quite as much as you need for your use case. But it gives building blocks to go off.
Do you feel comfortable submitting a PR for this work? If so, we could probably put it in our 1.2 release which is going to focus on performance. We're currently working on fixing bugs in 1.0 and addressing legacy go and go library versions for 1.1.
Ha, I was just finishing the PR for this. Here you go: https://github.com/cloudnativelabs/kube-router/pull/964
Now, a question about ipAddrAdd() (which is the second – and the last – remaining bottleneck).
In https://github.com/cloudnativelabs/kube-router/commit/725bff6b87c489bd7759bb0c9668a9b112f4c252, @murali-reddy mentioned that he’s calling ip route replace instead of netlink.RouteReplace because the latter succeeds but doesn’t actually replace the route. The commit was two years go.
Locally, if I’m replacing ip route replace with netlink.RouteReplace:
- out, err := exec.Command("ip", "route", "replace", "local", ip, "dev", KubeDummyIf, "table", "local", "proto", "kernel", "scope", "host", "src",
- NodeIP.String(), "table", "local").CombinedOutput()
+ err = netlink.RouteReplace(&netlink.Route{
+ Dst: &net.IPNet{IP: net.ParseIP(ip), Mask: net.IPv4Mask(255, 255, 255, 255)},
+ LinkIndex: iface.Attrs().Index,
+ Table: 254,
+ Protocol: 0,
+ Scope: netlink.SCOPE_HOST,
+ Src: NodeIP,
+ })
the second bottleneck gets resolved. With this change, for me, setupClusterIPServices now takes ~0.3s (down from 2.5s), and the whole ipvs sync-up goes down to ~0.6s (from ~6.5s).
Questions:
-
How could I verify whether the issue quoted by @murali-reddy still holds true? (Don’t know networking enough to test this on my own.) It’s been two years, and there’re other places in the code which use
RouteReplace, so perhaps it’s safe to do this change now? -
What’s the correct way to write the
RouteReplacecall above? I’ve never worked withiprouting before.I mapped some arguments from
ip route replacetonetlink.Route, but I’m not sure that’s 100% correct. I also had to copy some magic numbers (like the table number and the protocol number) from the result ofnetlink.RouteGet()– I’m not sure how to properly maptable localtoTable: 254andproto kerneltoProtocol: 0.
Okay, I think I have answers to both questions. Here’s the second PR: https://github.com/cloudnativelabs/kube-router/pull/965
Most of this was addressed via #964
There were a few outstanding chances for additional improvement that weren't quite implemented in #965
However, since that PR has been closed and the original author has moved on to other projects, I'm closing this issue as "mostly fixed"