connecting k8s cluster on AWS VPC with on-prem
I mentioned this in https://github.com/cloudnativelabs/kube-router/issues/213, but I'm not receiving BGP routing from kube-router in subnets other than the one quagga (zebra,bgpd) shares with kubernetes nodes.
Here's what I have currently, where sg-5b626129 is the kops master node group and sg-2e55565c is the node security group.
sg-2e55565c:
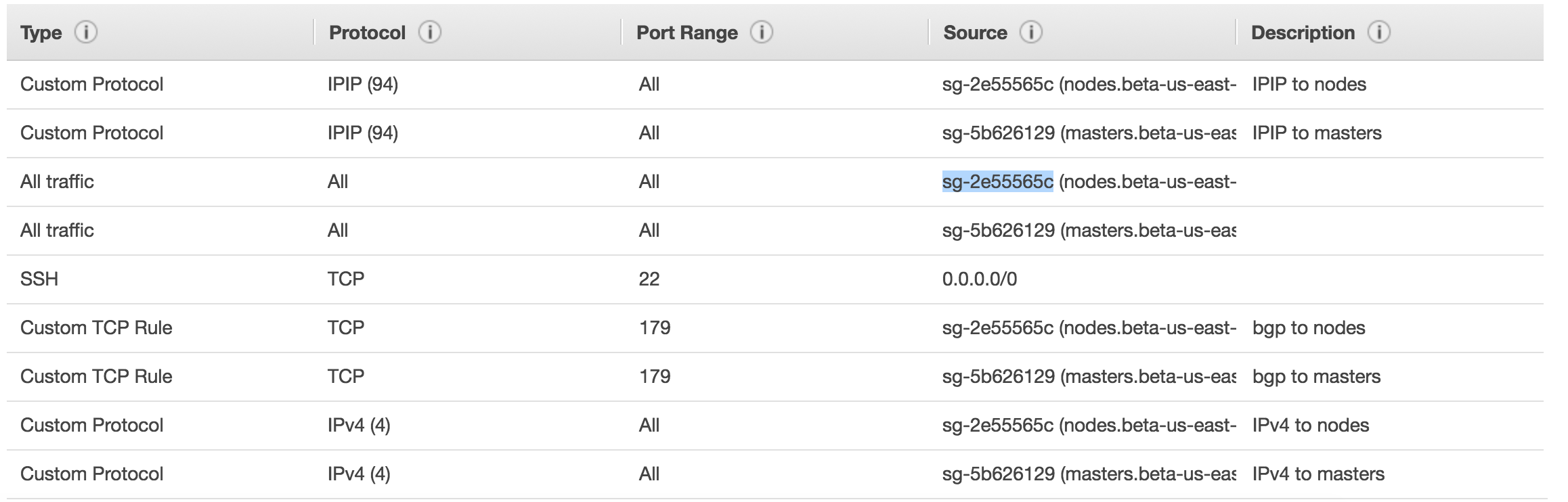
sg-5b626129:
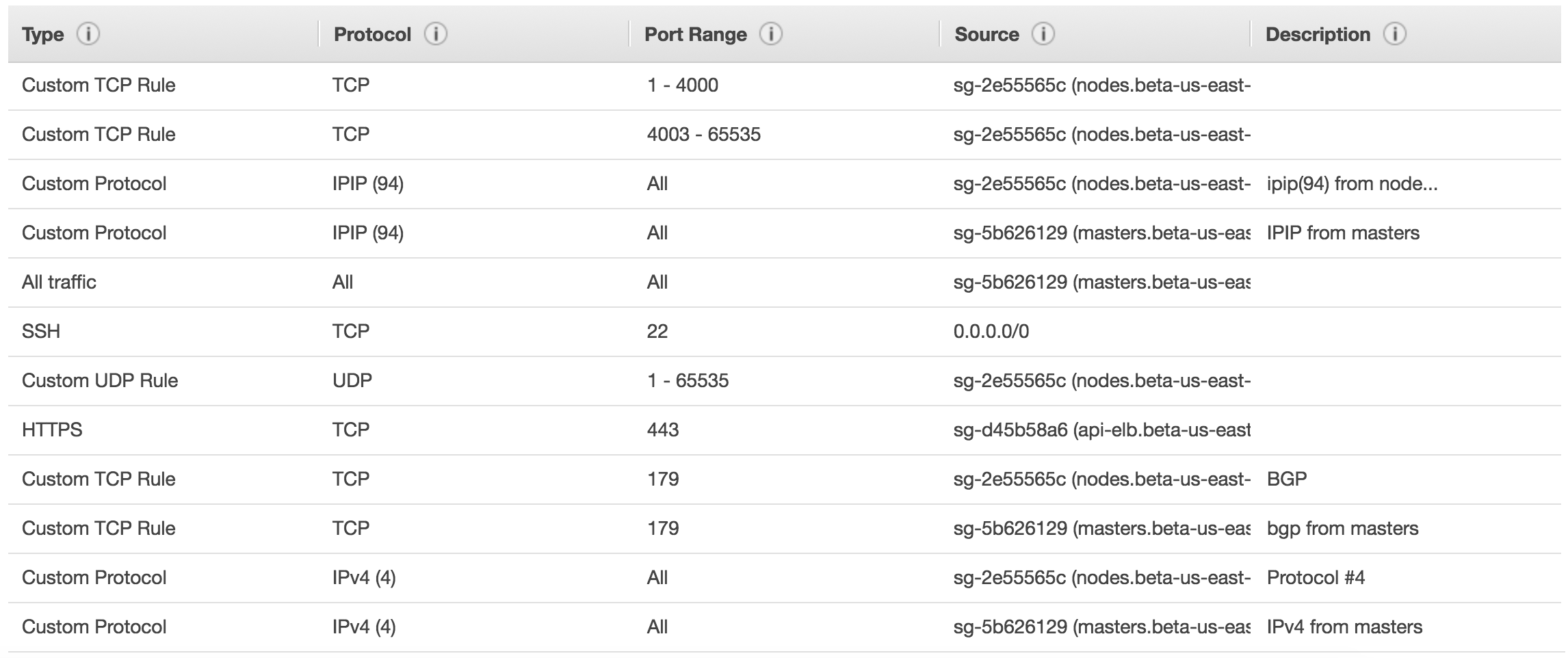
These are probably way more permissive than needed, but I wasn't able to find explicit documentation about this process and some of it I was cribbing from the calico documentation.
Here is my kube-router configuration:
args: --run-router=true --run-firewall=true --run-service-proxy=true --kubeconfig=/var/lib/kube-router/kubeconfig --cluster-cidr=10.30.0.0/16 --advertise-cluster-ip=true --cluster-asn=64512 --peer-router-ips=172.30.92.53 --peer-router-asns=64513 --routes-sync-period=10s --ipvs-sync-period=10s --hairpin-mode=true --nodeport-bindon-all-ip=true
I have a stand-alone router system using quagga running bgpd and zebra daemons using one of the subnets and the node security group.
/etc/quagga/zebra.conf:
interface eth0 ip address 10.30.0.0/16 ipv6 nd suppress-ra interface lo ip forwarding line vty log file /var/log/quagga/zebra.log
bgpd.conf is re-populated by a polling script querying the AWS API every 5 seconds:
/etc/quagga/bgpd.conf
hostname beta-us-east-1-kube-router password zebra router bgp 64513 bgp router-id 172.30.92.53 neighbor 172.30.76.15 remote-as 64512 neighbor 172.30.88.117 remote-as 64512 neighbor 172.30.37.50 remote-as 64512 neighbor 172.30.85.147 remote-as 64512 neighbor 172.30.108.214 remote-as 64512 neighbor 172.30.109.90 remote-as 64512 neighbor 172.30.98.232 remote-as 64512 neighbor 172.30.48.223 remote-as 64512 neighbor 172.30.52.146 remote-as 64512 log file /var/log/quagga/bgpd.log
On that system I'm only seeing things in the same subnet:
# echo "show ip bgp summary" | vtysh
Hello, this is Quagga (version 0.99.24.1). Copyright 1996-2005 Kunihiro Ishiguro, et al.
show ip bgp summary
BGP router identifier 172.30.92.53, local AS number 64513 RIB entries 13, using 1456 bytes of memory Peers 9, using 40 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 172.30.37.50 4 64512 267601 16736 0 0 0 5d12h42m 0 172.30.48.223 4 64512 267595 16738 0 0 0 5d12h42m 0 172.30.52.146 4 64512 267596 16739 0 0 0 5d12h42m 0 172.30.76.15 4 64512 267609 16740 0 0 0 5d12h42m 5 172.30.85.147 4 64512 267591 16738 0 0 0 5d12h42m 5 172.30.88.117 4 64512 267605 16739 0 0 0 5d12h42m 5 172.30.98.232 4 64512 267593 16738 0 0 0 5d12h42m 0 172.30.108.214 4 64512 267586 16737 0 0 0 5d12h42m 0 172.30.109.90 4 64512 267613 16737 0 0 0 5d12h42m 0
Total number of neighbors 9
Any help would be appreciated. Thanks in advance.
@looprock So your Quagga router is running in nodes security group? Can you please elobrate On that system I'm only seeing things in the same subnet:?
You have nods in different subnet, but quagga sees routes from the nodes in same subnet?
@murali-reddy yep, the quagga router is part of sg-2e55565c, the same security group as the kubernetes nodes, as well as sharing the same subnet/az with 1/3 of the nodes and a master, whcih are all able to report BGP data. I have 3 different subnets servicing hosts across availability zones:
subnet-a89a0ccc - us-east-1b
- 172.30.48.223 - node
- 172.30.52.146 - node
- 172.30.37.50 - master
subnet-3f936d10 - us-east-1c
- 172.30.76.15 - node
- 172.30.88.117 - node
- 172.30.85.147 - master
- 172.30.92.53 - quagga router
subnet-4271c909 - us-east-1d
- 172.30.109.90 - node
- 172.30.98.232 - node
- 172.30.108.214 - master
So if you look at the BGP summary you can see only the systems on the same subnet/az are reporting.
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 172.30.37.50 4 64512 267601 16736 0 0 0 5d12h42m 0 172.30.48.223 4 64512 267595 16738 0 0 0 5d12h42m 0 172.30.52.146 4 64512 267596 16739 0 0 0 5d12h42m 0 172.30.76.15 4 64512 267609 16740 0 0 0 5d12h42m 5 172.30.85.147 4 64512 267591 16738 0 0 0 5d12h42m 5 172.30.88.117 4 64512 267605 16739 0 0 0 5d12h42m 5 172.30.98.232 4 64512 267593 16738 0 0 0 5d12h42m 0 172.30.108.214 4 64512 267586 16737 0 0 0 5d12h42m 0 172.30.109.90 4 64512 267613 16737 0 0 0 5d12h42m 0
It does appear my security groups between master and node are sufficient to allow BGP data between the master and node security group.
@looprock could you please log-in to kube-router pods running any of 172.30.76.15,
172.30.88.117, 172.30.85.147 (these nodes are in same subnet as quagga) and check gobgp neighbour and see how does it look?
Interesting, sorry I'm kind of a BGP n00b to know what this means:
Peer AS Up/Down State |#Received Accepted 172.30.37.50 64512 6d 13:01:15 Establ | 1 1 172.30.48.223 64512 6d 13:01:14 Establ | 1 1 172.30.52.146 64512 6d 13:01:16 Establ | 1 1 172.30.85.147 64512 6d 13:01:12 Establ | 1 1 172.30.88.117 64512 6d 13:01:14 Establ | 1 1 172.30.92.53 64513 6d 13:01:22 Establ | 2 0 172.30.98.232 64512 6d 13:01:14 Establ | 1 1 172.30.108.214 64512 6d 13:01:10 Establ | 1 1 172.30.109.90 64512 6d 13:01:18 Establ | 1 1
for good measure here's one of the nodes failing updates:
Peer AS Up/Down State |#Received Accepted 172.30.37.50 64512 6d 13:07:08 Establ | 1 1 172.30.48.223 64512 6d 13:07:08 Establ | 1 1 172.30.76.15 64512 6d 13:07:08 Establ | 1 1 172.30.85.147 64512 6d 13:07:07 Establ | 1 1 172.30.88.117 64512 6d 13:07:08 Establ | 1 1 172.30.92.53 64513 6d 13:07:07 Establ | 7 0 172.30.98.232 64512 6d 13:07:06 Establ | 1 1 172.30.108.214 64512 6d 13:07:06 Establ | 1 1 172.30.109.90 64512 6d 13:07:05 Establ | 1 1
Looks like nodes in same and different subnet are able to reach Quagga, hence you see the BGP FSM state as Established . But Quagga is able to reach and establist BGP session with only to the nodes in the same subnet (state 5), rest of the nodes BGP state is 0.
Could you please check from quagga, if port 1790 (on which GoBGP server listens) of any node in different subnet is reachable (telnet nodeip 1790)?
Sorry is it maybe port 179, minus the 0?
root@ip-172-30-52-146:~# netstat -lntp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 412/rpcbind tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 21862/kube-router tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 534/sshd tcp 0 0 0.0.0.0:56729 0.0.0.0:* LISTEN 421/rpc.statd tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 826/kubelet tcp6 0 0 :::10255 :::* LISTEN 826/kubelet tcp6 0 0 :::111 :::* LISTEN 412/rpcbind tcp6 0 0 :::8080 :::* LISTEN 21862/kube-router tcp6 0 0 :::56434 :::* LISTEN 421/rpc.statd tcp6 0 0 :::179 :::* LISTEN 21862/kube-router tcp6 0 0 :::22 :::* LISTEN 534/sshd tcp6 0 0 :::4194 :::* LISTEN 826/kubelet tcp6 0 0 :::50051 :::* LISTEN 21862/kube-router tcp6 0 0 :::10250 :::* LISTEN 826/kubelet
kube-router$ telnet 172.30.76.15 1790 Trying 172.30.76.15... telnet: Unable to connect to remote host: Connection refused
It seems I can reach both the reporting and non-reporting nodes on 179:
kube-router$ telnet 172.30.76.15 179 Trying 172.30.76.15... Connected to 172.30.76.15. Escape character is '^]'. Connection closed by foreign host. kube-router$ telnet 172.30.52.146 179 Trying 172.30.52.146... Connected to 172.30.52.146. Escape character is '^]'. Connection closed by foreign host.
Ok. There are no connectivity issues (due to security groups etc). BGP configuration (for the kube-router and quagga) seems fine as well. Do you see any error/warnings in log file /var/log/quagga/bgpd.log in Quagga? Or in kube-router logs while peering up with 172.30.92.53
I was in the middle of testing something else and the IPs in the cluster are different, but the situation is the same..
The quagga router is now at 172.30.98.97.
The only error or warning logs I can find are warnings on one of the nodes not updating routes on the router:
$ kubectl logs kube-router-cbvm4 -n kube-system |grep -i warn time="2017-11-15T18:56:42Z" level=warning msg="No matching path for withdraw found, may be path was not installed into table" Key=10.30.0.10/32 Path="{ 10.30.0.10/32 | src: { 172.30.98.97 | as: 64513, id: 172.30.98.97 }, nh: 172.30.98.97, withdraw }" Topic=Table time="2017-11-15T18:56:42Z" level=warning msg="No matching path for withdraw found, may be path was not installed into table" Key=10.30.0.1/32 Path="{ 10.30.0.1/32 | src: { 172.30.98.97 | as: 64513, id: 172.30.98.97 }, nh: 172.30.98.97, withdraw }" Topic=Table time="2017-11-15T18:57:12Z" level=warning msg="No matching path for withdraw found, may be path was not installed into table" Key=10.30.132.0/24 Path="{ 10.30.132.0/24 | src: { 172.30.98.97 | as: 64513, id: 172.30.98.97 }, nh: 172.30.98.97, withdraw }" Topic=Table time="2017-11-15T18:57:12Z" level=warning msg="No matching path for withdraw found, may be path was not installed into table" Key=10.30.130.0/24 Path="{ 10.30.130.0/24 | src: { 172.30.98.97 | as: 64513, id: 172.30.98.97 }, nh: 172.30.98.97, withdraw }" Topic=Table time="2017-11-15T18:57:53Z" level=warning msg="received notification" Code=6 Data="[]" Key=172.30.98.97 Subcode=3 Topic=Peer
@looprock No i could not figure. I will try to see if i can reproduce the similar behaviour.
@looprock sorry it took a while. Actually reason is pretty simple. eBGP peers need to be directly connected for neighbor adjacency. Please see https://networklessons.com/bgp/ebgp-multihop/ for explanation. There is EBGP multi-hop, that perhaps wont work as well.
Can you provision the instance you are using to run Quagaa to present in both subnets of the VPC and give it a try? Any ways I am afraid this is not standard topology kube-router is designed for. Please re-open if you think anything kube-router can do support this.
Adding little more details.
Lets say node A in Zone A, is trying to peer with Quagga router in Zone B. Here node A and Qugga there is no direct connectivity as they are in different subnets. Packets has to traverse through VPC router for node A and Quagga connectivity.
I understand your point but I guess I'm confused about how the kube-router nodes are handling this since they're talking across subnets as well?
As a side note, I would think a multi-az kubernetes cluster is a very typical configuration. Are there other topologies that would provide me with direct service and pod routing in this configuration? I'm happy to adapt what I'm doing, I just can't think of how to accomplish what I'd like to do in another way.
Nodes form iBGP peering (which does not required direct connectivity). For cross-zone connectivty of pods, kube-router uses IPIP tunnels. Cross-zone cluster with kube-router is fully supported out-of-the box. You dont need to do any thing special.
Are there other topologies that would provide me with direct service and pod routing in this configuration?
Can you please elaborate what you mean by direct service (from on prem?)
We have a VPN endpoint terminating in our VPC which allows us to route directly to addresses within the VPC subnet. We're currently using flannel and I've set up a flannel endpoint with the -ip-masq option plus a routing rule in AWS to route traffic to our current kubernetes pods' private address space managed by flannel through the node running flanneld so we can directly access pods. So all traffic from the VPC to 10.1.x.x passes through the flanneld 'router'.
I was hoping to be able to set up the quagga node in a similar capacity, as a router for traffic coming from our VPC to the kube-router managed IP space.
@looprock your use case makes perfect sense. i will have to try and see how to make it work. Re-opening the issue.
Thanks so much @murali-reddy. Would it make sense to try to use kube-router directly as I've been using flanneld, versus trying to pick up routes via ibgp/quagga? Would that be possible or provide any kind of advantage?
@looprock What backend are you using with Flannel? Kube-router can masqurade outbound traffic. But it does not configure pod CIDR's on the VPC routing table. Also there is limit of 50 entries. So inbound traffic from on-prem to pod's running in the VPC can not be easily achived.
From what i read you leverage AWS VPC routing table? Also what is flanneld 'router'?
@murali-reddy we're using etcd as that backend for flannel. The basic setup is pretty straight-forward. I'm running a stand-alone node running flanneld connected to the same backend the kubernetes nodes:
/usr/local/bin/flanneld --etcd-endpoints=http://xxx.kube.cluster:2379 -ip-masq
Flanneld will actually configure iptables for you when you set the -ip-masq flag:
Chain FORWARD (policy ACCEPT 3649K packets, 2043M bytes) pkts bytes target prot opt in out source destination 0 0 ACCEPT all -- flannel.1 eth0 10.1.0.0/16 0.0.0.0/0 ctstate NEW
Chain POSTROUTING (policy ACCEPT 118K packets, 14M bytes) pkts bytes target prot opt in out source destination 0 0 MASQUERADE all -- any eth0 ip-10-1-0-0.ec2.internal/16 anywhere 0 0 MASQUERADE all -- any eth0 ip-10-8-0-0.ec2.internal/24 anywhere 0 0 RETURN all -- any any ip-10-1-0-0.ec2.internal/16 ip-10-1-0-0.ec2.internal/16
0 0 MASQUERADE all -- any any ip-10-1-0-0.ec2.internal/16 !base-address.mcast.net/4
118K 7321K MASQUERADE all -- any any !ip-10-1-0-0.ec2.internal/16 ip-10-1-0-0.ec2.internal/16
On the AWS side I only have one rule:
10.1.0.0/16 | eni-xxxxxxxx / i-xyxyxyxyxyxyxyxyx
Where i-xyxyxyxyxyxyxyxyx is the stand-alone flanneld instance where I've disabled the src/destination checks.
So in the kube-router setup I would imagine doing the same thing and the only VPC routing rule would be for the full subnet managed by kube-router, RE: the nonMasqueradeCIDR in kops. So no need to worry about the 50 route limit because you'd only be adding one.
@looprock Yes. that should work. Each node of the cluster knows how to route traffic to any pod runnning on any node of the cluster. So if you setup your AWS rule to any of the nodes in the cluster, connectivity from on-prem network to any pod in the cluster should work.