cloud_controller_ng
 cloud_controller_ng copied to clipboard
cloud_controller_ng copied to clipboard
[Post-Mortem] Deserialization errors caused by Rails update
Symptom
We have a monitor for cf push; that means we push a simple application once every 5 minutes. This monitor detected a "downtime" while we were updating our largest internal foundation from CAPI 1.124.0 to 1.126.0.
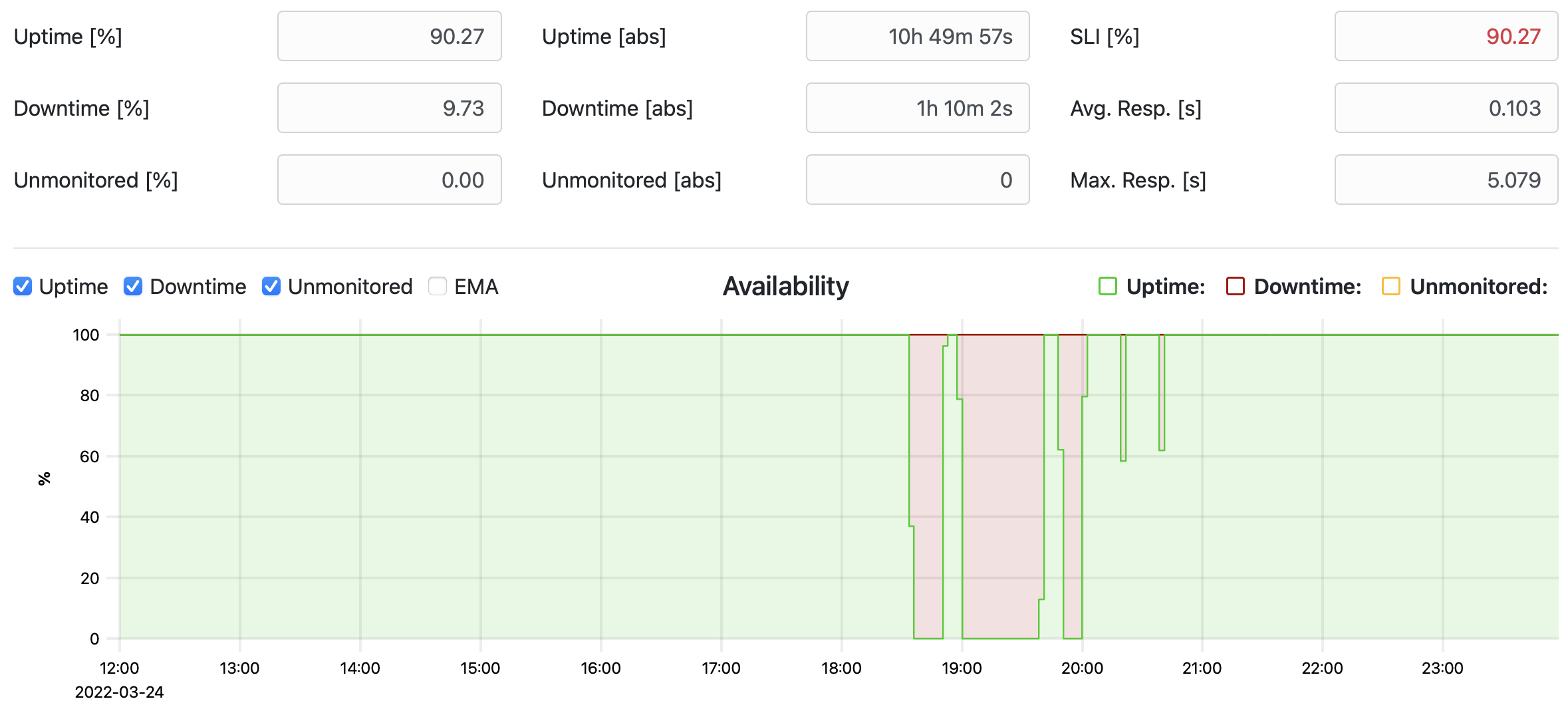
Failure
The errors lasted for about 1.5 hours. When looking into the logs of the monitor, it could be seen that cf push did not fail, but did not succeed in time (it has a timeout of less than 5 minutes).
The "downtime" correlated with the update of api and cc-worker vms. When searching for logs produced for a cf push that timed out, a deserialization error could be found:
Mar 24, 2022 @ 18:29:29.407 (0.000888s) (lib/delayed_job_plugins/deserialization_retry.rb:12:in `block (2 levels) in <class:DeserializationRetry>') (query_length=21114) UPDATE "delayed_jobs" SET "guid" = '920c6540-0f2d-4f46-91dc-2769fefec587', "created_at" = '2022-03-24 18:29:29.250646+0000', "updated_at" = CURRENT_TIMESTAMP, "priority" = 0, "attempts" = 1, "handler" = '--- !ruby/object:VCAP::CloudController::Jobs::LoggingContextJob
handler: !ruby/object:VCAP::CloudController::Jobs::TimeoutJob
handler: !ruby/object:VCAP::CloudController::Jobs::PollableJobWrapper
existing_guid:
handler: !ruby/object:VCAP::CloudController::Jobs::SpaceApplyManifestActionJob
[...]
', "last_error" = 'Job failed to load: undefined method `default_proc='' for nil:NilClass.'
Root Cause
Further analyses showed that the root cause for this error is the Ruby on Rails update from version 5.x to 6.x that included a change in the error model (rails/rails/pull/32313). The serialization of an empty ActiveModel::Errors object changed from:
--- !ruby/object:ActiveModel::Errors
messages: {}
details: {}
to:
--- !ruby/object:ActiveModel::Errors
errors: []
The nil:NilClass error is raised when a cc-worker running Rails 5 tries to deserialize a job created by an api node already updated to Rails 6 as the payload does not contain messages anymore.
sequenceDiagram
participant API 1.124.0
participant WORKER 1.124.0
participant CCDB
participant API 1.126.0
participant WORKER 1.126.0
rect rgba(0, 255, 0, .4)
API 1.124.0->>CCDB: serialize job
CCDB->>WORKER 1.124.0: deserialize job
note over WORKER 1.124.0: success
end
note over API 1.124.0,WORKER 1.126.0: update started
rect rgba(255, 0, 0, .4)
API 1.126.0->>CCDB: serialize job
CCDB->>WORKER 1.124.0: deserialize job
note over WORKER 1.124.0: failure
end
note over API 1.124.0,WORKER 1.126.0: update finished
rect rgba(0, 255, 0, .4)
API 1.126.0->>CCDB: serialize job
CCDB->>WORKER 1.126.0: deserialize job
note over WORKER 1.126.0: success
end
Mitigation
There already is a mitigation in place, i.e. the DeserializationRetry plugin that ensures that all jobs failing with Job failed to load are rescheduled.
Although this retry mechanism works as intended, it could not prevent the significant service degradation we experienced. Due to the fact that we have many api nodes (far more than 100), it simply takes some time until all of them are updated. And only after all api nodes have been updated, the cc-worker vms are in line.
So when the job was finally processed by an updated cc-worker, it failed as the app was already deleted. This is due to the fact that the cf push monitor deletes the app in the end and also cleans up failed apps from previous runs:
# Mar 24, 2022 @ 19:59:33.598 (0.001951s) (51086a20d7be919cc370b15e4225a7ea526e809f/gem_home/ruby/2.7.0/gems/talentbox-delayed_job_sequel-4.3.0/lib/delayed/backend/sequel.rb:111:in `save!') (query_length=19799) UPDATE "delayed_jobs" SET "guid" = '920c6540-0f2d-4f46-91dc-2769fefec587', "created_at" = '2022-03-24 18:29:29.250646+0000', "updated_at" = CURRENT_TIMESTAMP, "priority" = 1, "attempts" = 19, "handler" = '--- !ruby/object:VCAP::CloudController::Jobs::LoggingContextJob
handler: !ruby/object:VCAP::CloudController::Jobs::TimeoutJob
handler: !ruby/object:VCAP::CloudController::Jobs::PollableJobWrapper
existing_guid:
handler: !ruby/object:VCAP::CloudController::Jobs::SpaceApplyManifestActionJob
[...]
', "last_error" = 'App with guid ''279c616d-2e8c-4cfa-9eca-bda9ec464740'' not found'
Fix
Before continuing to rollout the update to customer-facing foundations, we decided to patch the deserialization to be compatible between Rails versions 5 and 6.
Therefore we cherry-picked this commit onto CAPI 1.124.0 and 1.126.0.
Depending on the Rails version (Rails::VERSION::MAJOR) it monkey patches ActiveModel::Errors.init_with either with a version that can also deserialize errors serialized with Rails 6 or those serialized with Rails 5.
The error outlined above could be prevented by solely making the old CAPI release capable of deserializing Rails 6 errors; but as there is also the possibility that jobs created by an api node running Rails 5 are still in the database after the update (e.g. due to retries of failed jobs), we also patched the new CAPI release to be able to deserialize Rails 5 errors.
I added a warning to the release that contains the upgrade: https://github.com/cloudfoundry/capi-release/releases/tag/1.125.0
Maybe we could do some work to prevent these issues in the future, like adding a Concourse job that attempts deserialization of jobs between different CAPI versions?
I was thinking a bit about testing:
One option would be to test running the API and workers with different versions and then triggering jobs. This would be similar to how y'all test for backwards-incompatible database migrations. It might be difficult to ensure you have triggered all the jobs (but maybe only the cf push-related jobs are critical). This would definitely be the more "real" option.
Another option could be to record serialized jobs into test fixtures and then fail whenever they change. This would definitely result in some false positives and require human judgement for what constitutes a breaking change, but it would probably be simpler to implement. It would probably also be easier to trigger jobs, since you could do it at a lower level.
I would like to start with a more lightweight test if possible in terms of managing environments, simply because the burden of maintaining our pipeline is already significant.
I was thinking something similar to recording fixtures as you mentioned. Something like:
- every release, record fixtures of jobs and commit somewhere
- have a ruby test file/directory for jobs that at the minimum deserializes the relevant job and checks that it can be run without failure
- run that file on the N past versions' generated fixtures
Slightly trickier: 4. generate a file for the latest commit of CCNG, and run the previous release against that file.
Thanks for your ideas. I will simply paste here what I added to our internal backlog tool. These are also just ideas that go into the direction of adding test fixtures. The procedure seems a little complicated, but the problem is that we have to "change the past" to make it compatible (i.e. prevent rolling out incompatible changes).
What we could do:
- Serialize different jobs and store them as files (e.g. job_v1.yml).
- Create unit tests that serialize jobs and compare them to these files. => Detect format changes.
- Document how to tackle future changes.
A possible procedure (when a change is detected):
- Scenario 1: cc_workers can process jobs created by api nodes from the next release; i.e. jobs created during the update.
- Add serialized jobs to new files (e.g. job_v2.yml).
- Revert changes that caused the format diff.
- Implement compatible deserialization (i.e. works with job_v1.yml and job_v2.yml).
- Create and ship CAPI release.
- Scenario 2: cc_workers can process jobs created by api nodes from the previous release; i.e. jobs that have already been in the queue before the update.
- Incorporate format change.
- Implement compatible deserialization (i.e. works with job_v2.yml and job_v1.yml).
- Create and ship CAPI release.
One problem I see is that we'll never know which is the 'old' and the 'new' version. Also in cf-deployment some capi releases are skipped.
Another option (maybe mid/long term) would be to change/optimize the dependency between api and worker nodes (maybe ccng_clock is also relevant in that context). Some ideas:
- Deploy
workernodes beforeapinodes or deploytemp-workernodes which take care of newer jobs -> Might require job versioning or a modified queuing mechanism (e.g. multiple queues) - Implement a errand/process/job which can migrate jobs between any version
@johha That would be for sure be a nice way to ensure compatibillity. However now bosh has to wait for the "old" CC Job Queue to be empty before removing all "old" cc_workers. Otherwise you are left with old stuff in this queue and they wouldnt be picket up anymore. I dont have experience in syncing such operations with bosh, could imagine this is quite complex and delays a cf deployment as long as the job timeout is. So by hours or days depending what is set.
I modified enqueuer to serialize jobs (job.to_yml) and executed the unit tests. Unfortunately not all jobs are covered (e.g. SpaceApplyManifestActionJob) and also the jobs are not as nested compared to real jobs.
For writing a "detection test" we'd need to run a more complex test suite like CATs and dump the serialized jobs so that we can compare them later on.
A description of what has been done to test the Rails 7.0/7.1 update can be found here: https://github.com/cloudfoundry/cloud_controller_ng/pull/3577#pullrequestreview-1827629114
For now this seems to be the best procedure to ensure compatibility of a major Rails upgrade.
Also the deserialization unit test has been updated.