gpt_academic
 gpt_academic copied to clipboard
gpt_academic copied to clipboard
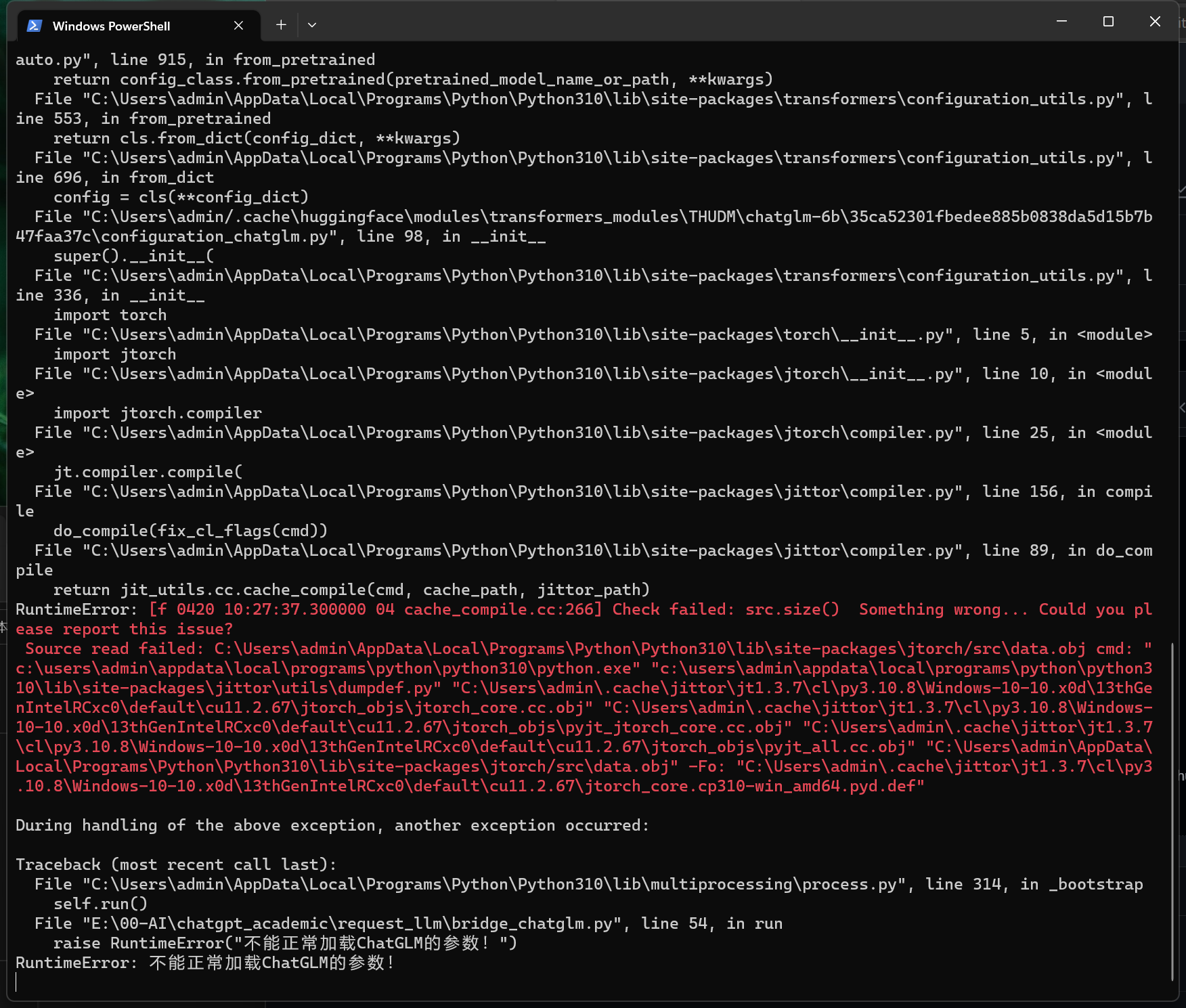
[Local Message] Call ChatGLM fail 不能正常加载ChatGLM的参数。
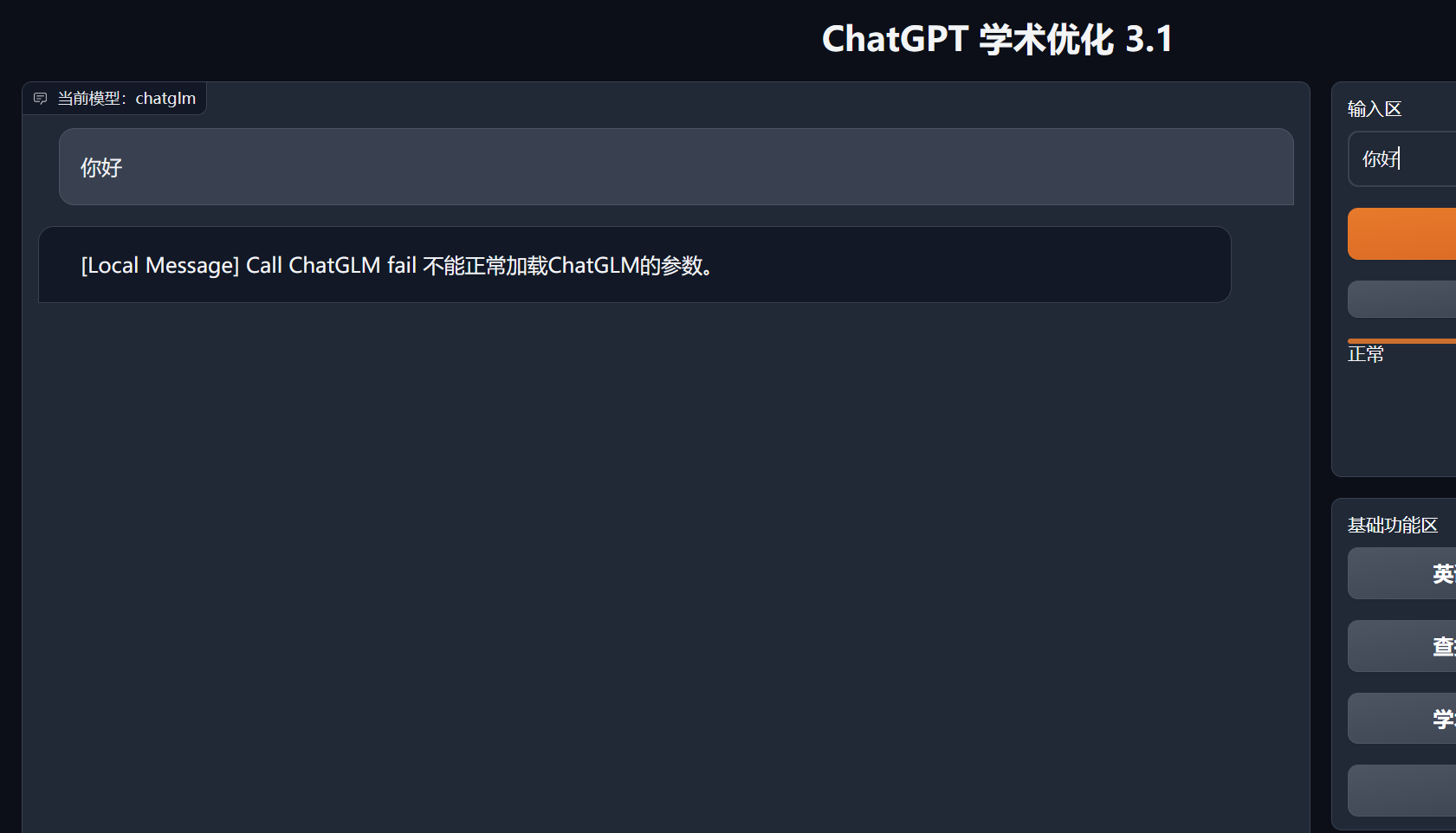
我今天刚完成部署,也是遇到这个问题,gpt-3.5-turbo的调用能正常,ChatGLM调用报参数错误,是不是由于ChatGLM那边新近有参数改变但我们项目还没有及时调整更新?
brary/base.py", line 59, in init raise RuntimeError("Unknown platform: %s" % sys.platform) RuntimeError: Unknown platform: darwin
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/Users/xy/miniconda3/envs/gptac_venv/lib/python3.11/multiprocessing/process.py", line 314, in _bootstrap self.run() File "/Volumes/MacData/SynologyDrive/S_Software/chatgpt_academic/request_llm/bridge_chatglm.py", line 54, in run raise RuntimeError("不能正常加载ChatGLM的参数!") RuntimeError: 不能正常加载ChatGLM的参数!
我也是这样。我在一台AMD集成显卡的笔记本上部署,chatgpt正常加载,但是模型切换到ChatGLM会出错,config.py中设置的是cpu,但是出错说是找不到 nvcuda.dll
我也是这样。我在一台AMD集成显卡的笔记本上部署,chatgpt正常加载,但是模型切换到ChatGLM会出错,config.py中设置的是cpu,但是出错说是找不到 nvcuda.dll
不太清楚,有可能只能用NVIDIA的卡
我也是这样。我在一台AMD集成显卡的笔记本上部署,chatgpt正常加载,但是模型切换到ChatGLM会出错,config.py中设置的是cpu,但是出错说是找不到 nvcuda.dll
不太清楚,有可能只能用NVIDIA的卡 是不是chatglm这个模型即使设置使用cpu,相应的库和硬件也需要有对应的GPU。就是指没有CPU版本的?
@knight134 @csw630 @xy317272 @Moximixi @leomsn
用这段代码测试一下环境的问题
from transformers import AutoModel, AutoTokenizer
chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
device = 'cpu'
if device=='cpu':
chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
else:
chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
chatglm_model = chatglm_model.eval()
我也是这样。我在一台AMD集成显卡的笔记本上部署,chatgpt正常加载,但是模型切换到ChatGLM会出错,config.py中设置的是cpu,但是出错说是找不到 nvcuda.dll
不太清楚,有可能只能用NVIDIA的卡 是不是chatglm这个模型即使设置使用cpu,相应的库和硬件也需要有对应的GPU。就是指没有CPU版本的?
有没有traceback?
RuntimeError: Unknown platform: darwin
https://github.com/THUDM/ChatGLM-6B/issues/635
brary/base.py", line 59, in init raise RuntimeError("Unknown platform: %s" % sys.platform) RuntimeError: Unknown platform: darwin
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/Users/xy/miniconda3/envs/gptac_venv/lib/python3.11/multiprocessing/process.py", line 314, in _bootstrap self.run() File "/Volumes/MacData/SynologyDrive/S_Software/chatgpt_academic/request_llm/bridge_chatglm.py", line 54, in run raise RuntimeError("不能正常加载ChatGLM的参数!") RuntimeError: 不能正常加载ChatGLM的参数!
https://github.com/THUDM/ChatGLM-6B#mac-%E4%B8%8A%E7%9A%84-gpu-%E5%8A%A0%E9%80%9F
是mac吗,需要修改一下request_llm/bridge_chatglm.py的第43,45行
from transformers import AutoModel, AutoTokenizer
chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) device = 'cpu' if device=='cpu': chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() else: chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() chatglm_model = chatglm_model.eval()
win11 64位家庭版,AMD 6800H 笔记本
Python3.11
>>> chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() Explicitly passing a revisionis encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision. Explicitly passing arevision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Traceback (most recent call last):
File "
`
@knight134 @csw630 @xy317272 @Moximixi @leomsn
用这段代码测试一下环境的问题
from transformers import AutoModel, AutoTokenizer chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) device = 'cpu' if device=='cpu': chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() else: chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() chatglm_model = chatglm_model.eval()
另外我发现https://github.com/THUDM/ChatGLM-6B的readme中记录了很多解决方法,可以试试。 对应代码在request_llm/bridge_chatglm.py的第40行~50行之间
from transformers import AutoModel, AutoTokenizer chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) device = 'cpu' if device=='cpu': chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() else: chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() chatglm_model = chatglm_model.eval()
win11 64位家庭版,AMD 6800H 笔记本 Python3.11
>>> chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() Explicitly passing arevisionis encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision. Explicitly passing arevision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision. Traceback (most recent call last): File "", line 1, in File "D:\software\python\Lib\site-packages\transformers\models\auto\auto_factory.py", line 462, in from_pretrained model_class = get_class_from_dynamic_module( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 388, in get_class_from_dynamic_module final_module = get_cached_module_file( ^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 299, in get_cached_module_file get_cached_module_file( File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 269, in get_cached_module_file modules_needed = check_imports(resolved_module_file) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 134, in check_imports importlib.import_module(imp) File "D:\software\python\Lib\importlib__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "", line 1206, in gcd_import File "", line 1178, in find_and_load File "", line 1149, in find_and_load_unlocked File "", line 690, in load_unlocked File "", line 940, in exec_module File "", line 241, in call_with_frames_removed File "D:\software\python\Lib\site-packages\cpm_kernels__init.py", line 1, in from . import library File "D:\software\python\Lib\site-packages\cpm_kernels\library__init.py", line 2, in from . import cuda File "D:\software\python\Lib\site-packages\cpm_kernels\library\cuda.py", line 7, in cuda = Lib.from_lib("cuda", ctypes.WinDLL("nvcuda.dll")) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\ctypes__init.py", line 376, in init self._handle = _dlopen(self.name, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: Could not find module 'nvcuda.dll' (or one of its dependencies). Try using the full path with constructor syntax.`
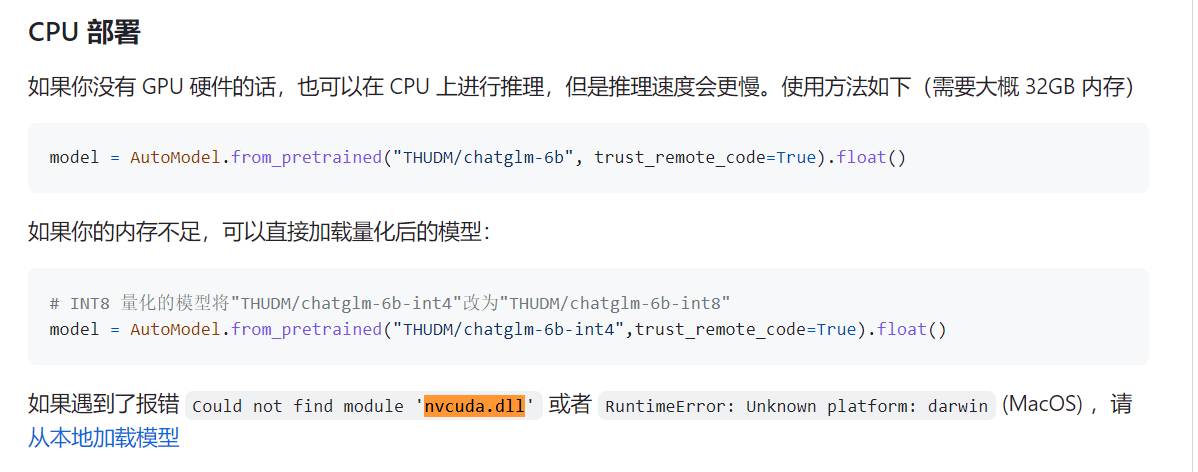
根据chatglm的文档,这个需要从本地加载模型 https://github.com/THUDM/ChatGLM-6B/blob/main/README.md#%E4%BB%8E%E6%9C%AC%E5%9C%B0%E5%8A%A0%E8%BD%BD%E6%A8%A1%E5%9E%8B
from transformers import AutoModel, AutoTokenizer chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) device = 'cpu' if device=='cpu': chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() else: chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() chatglm_model = chatglm_model.eval()
win11 64位家庭版,AMD 6800H 笔记本 Python3.11
>>> chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() Explicitly passing arevisionis encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision. Explicitly passing arevision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision. Traceback (most recent call last): File "", line 1, in File "D:\software\python\Lib\site-packages\transformers\models\auto\auto_factory.py", line 462, in from_pretrained model_class = get_class_from_dynamic_module( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 388, in get_class_from_dynamic_module final_module = get_cached_module_file( ^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 299, in get_cached_module_file get_cached_module_file( File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 269, in get_cached_module_file modules_needed = check_imports(resolved_module_file) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\site-packages\transformers\dynamic_module_utils.py", line 134, in check_imports importlib.import_module(imp) File "D:\software\python\Lib\importlib__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "", line 1206, in gcd_import File "", line 1178, in find_and_load File "", line 1149, in find_and_load_unlocked File "", line 690, in load_unlocked File "", line 940, in exec_module File "", line 241, in call_with_frames_removed File "D:\software\python\Lib\site-packages\cpm_kernels__init.py", line 1, in from . import library File "D:\software\python\Lib\site-packages\cpm_kernels\library__init.py", line 2, in from . import cuda File "D:\software\python\Lib\site-packages\cpm_kernels\library\cuda.py", line 7, in cuda = Lib.from_lib("cuda", ctypes.WinDLL("nvcuda.dll")) ^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\software\python\Lib\ctypes__init.py", line 376, in init self._handle = _dlopen(self.name, mode) ^^^^^^^^^^^^^^^^^^^^^^^^^ FileNotFoundError: Could not find module 'nvcuda.dll' (or one of its dependencies). Try using the full path with constructor syntax.`
根据chatglm的文档,这个需要从本地加载模型 https://github.com/THUDM/ChatGLM-6B/blob/main/README.md#%E4%BB%8E%E6%9C%AC%E5%9C%B0%E5%8A%A0%E8%BD%BD%E6%A8%A1%E5%9E%8B
下载完之后,放在C:\Users\用户名\.cache\huggingface\modules\transformers_modules\THUDM\chatglm-6b试试
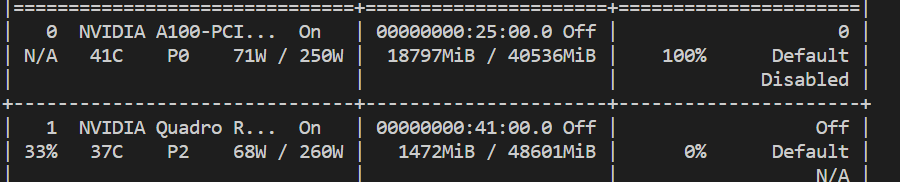
我的个人电脑最高只有8G 3060Ti,但是集群上可以部署一个A100, 这个是不是可以调用更高规格的ChatGLM。
那必须的,a100至少40G显存呢
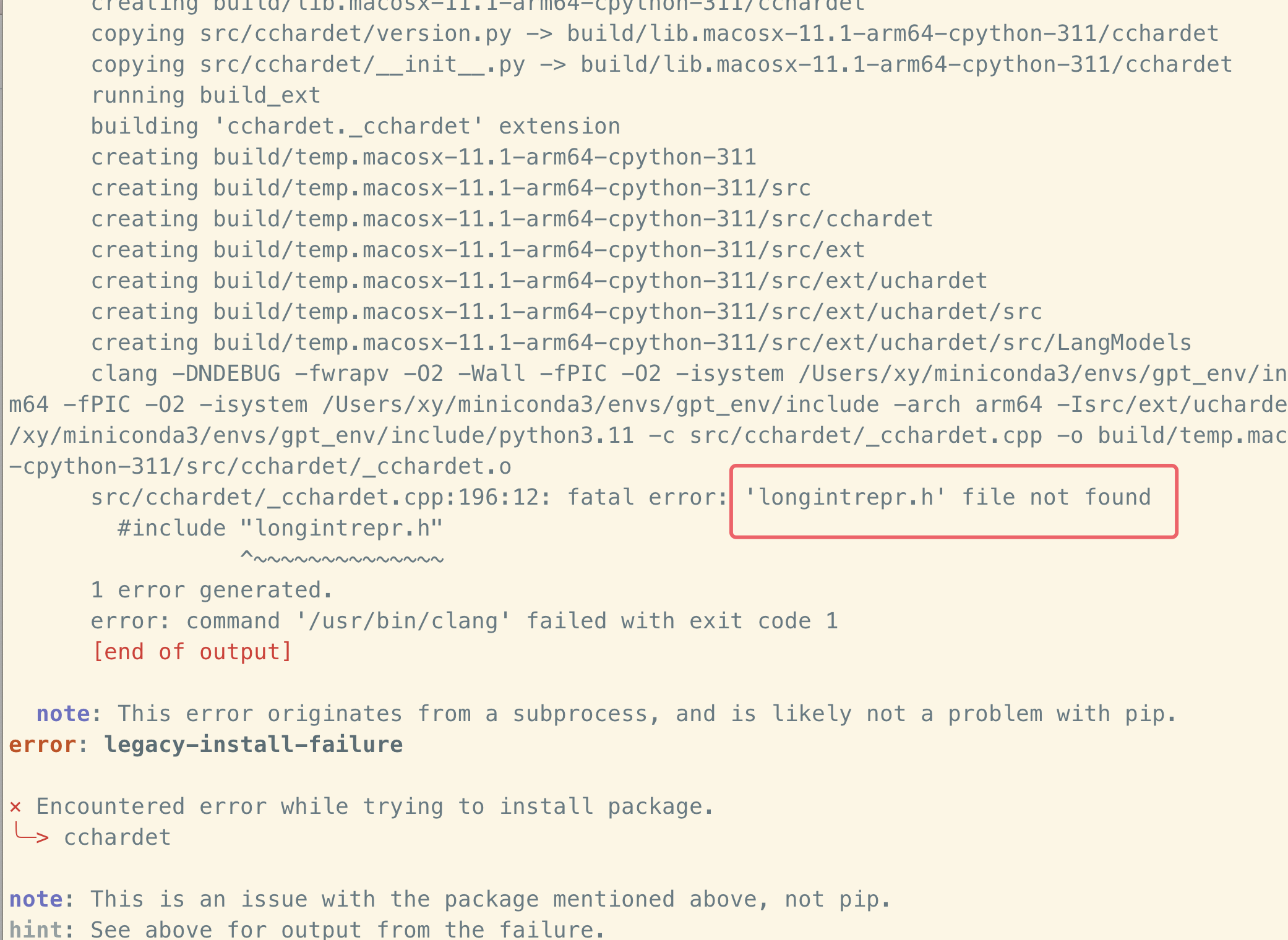
 经过努力,终于在我的 mac 上弄好了glm模型,mac(M1max 64GB内存+32),其实也没多难,注意一点,就是楼主教程中给出的conda 创建虚拟环境如果定意 python3.11会导致一个必要包『cchardet』安装的时候出现如下图'longintrepr.h' 这个不存在的问题,这个问题在 arm 构架的 mac的python3.11中 暂时解决不了(如果有解决办法可以告诉我下哈)
经过努力,终于在我的 mac 上弄好了glm模型,mac(M1max 64GB内存+32),其实也没多难,注意一点,就是楼主教程中给出的conda 创建虚拟环境如果定意 python3.11会导致一个必要包『cchardet』安装的时候出现如下图'longintrepr.h' 这个不存在的问题,这个问题在 arm 构架的 mac的python3.11中 暂时解决不了(如果有解决办法可以告诉我下哈)
 换python3.9的 conda 环境重新来一遍,就可以成功安装这个包
换python3.9的 conda 环境重新来一遍,就可以成功安装这个包
 然后就可以顺利同时加载本地的GPT和ChatGLM模型了
然后就可以顺利同时加载本地的GPT和ChatGLM模型了

感谢xy317272 我是MACos,i7cpu的,3.10.7环境尝试了独立安装cchardet python -m pip install cchardet
完成后继续报错:RuntimeError: Unknown platform: darwin RuntimeError: 不能正常加载ChatGLM的参数!
可以看一下自己的torch是不是cuda版的
gpt_academic配置里默认安装的ChatGLM环境的torch好像是torch+cpu版的
可以自己手动卸载一下torch然后官网重装个带cuda的就可以用了
另外还可能是显存或内存不够炸了,可以改一下chatGLM py代码里的模型精度,模型改成INT4量化的就可以了
本地环境:Windows10 + torch2.0+ cuda117 + RTX2060 6G
成功测试,是可以使用的,效果还可以。
conda info --envs
conda activate gptac_venv
python cuda_test.py
# cuda_test.py
import torch
print('CUDA版本:',torch.version.cuda)
print('Pytorch版本:',torch.__version__)
print('显卡是否可用:','可用' if(torch.cuda.is_available()) else '不可用')
print('显卡数量:',torch.cuda.device_count())
print('当前显卡的CUDA算力:',torch.cuda.get_device_capability(0))
print('当前显卡型号:',torch.cuda.get_device_name(0))
# https://pytorch.org/get-started/locally/
pip uninstall torch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
我的是支持cuda的。docker-compose.yml文件内容如下:
version: '3'
services:
gpt_academic_full_capability:
image: ghcr.io/binary-husky/gpt_academic_with_all_capacity:master
volumes:
- /mnt/data/meeee/.cache/huggingface:/root/.cache/huggingface
environment:
# 请查阅 `config.py`或者 github wiki 以查看所有的配置信息
API_KEY: ' sk-**********************************'
USE_PROXY: ' False '
proxies: ' { "http": "http://127.0.0.1:8118", "https": "http://127.0.0.1:8118", } '
LLM_MODEL: ' chatglm'
AVAIL_LLM_MODELS: ' ["gpt-3.5-turbo", "gpt-4", "qianfan", "sparkv2", "spark", "chatglm"] '
BAIDU_CLOUD_API_KEY : ' bTUtwEAveBrQipEowUvDwYWq '
BAIDU_CLOUD_SECRET_KEY : ' jqXtLvXiVw6UNdjliATTS61rllG8Iuni '
XFYUN_APPID: ' 53a8d816 '
XFYUN_API_SECRET: ' MjMxNDQ4NDE4MzM0OSNlNjQ2NTlhMTkx '
XFYUN_API_KEY: ' 95ccdec285364869d17b33e75ee96447 '
ENABLE_AUDIO: ' False '
DEFAULT_WORKER_NUM: ' 20 '
WEB_PORT: ' 12345 '
ADD_WAIFU: ' False '
ALIYUN_APPKEY: ' RxPlZrM88DnAFkZK '
THEME: ' Chuanhu-Small-and-Beautiful '
ALIYUN_ACCESSKEY: ' LTAI5t6BrFUzxRXVGUWnekh1 '
ALIYUN_SECRET: ' eHmI20SVWIwQZxCiTD2bGQVspP9i68 '
LOCAL_MODEL_DEVICE: ' cuda '
我自己加了个volumes映射,这个目录下已经下载了很多的models了: models--OpenAssistant--reward-model-deberta-v3-large-v2 models--Vision-CAIR--vicuna-7b models--lmsys--vicuna-7b-v1.3 models--vicuna_data--vicuna-13b-v1.1 version.txt models--THUDM--chatglm-6b models--bert-base-uncased models--lmsys--vicuna-7b-v1.5 tmpf_25sj81 version_diffusers_cache.txt models--THUDM--chatglm2-6b models--h2oai--h2ogpt-oig-oasst1-512-6_9b models--models--vicuna-13b-v1.1 tmpqhaofnzc models--TheBloke--vicuna-7B-1.1-HF models--lmsys--vicuna-13b-delta-v1.1 models--stabilityai--stable-diffusion-2-1-base
居然还是这个报错!到底咋回事?也没见可以开启debug的配置的地方?