bevy
 bevy copied to clipboard
bevy copied to clipboard
Implement batched query support
- Only Dense queries are accelerated currently
- Certain features are awaiting on GATs/generic const expressions
- "Alignment-oblivious" architecture designed for best-in-class performance on modern (>2009) microarchitectures for simplicity
Objective
Fixes #1990
Solution
- Implement a batch-oriented view of the Bevy ECS suitable for SIMD acceleration, providing overalignment of table columns to ensure efficient aligned access where possible.
Changelog
- Queries can be executed in batches of
Nusing thefor_each_batched/for_each_mut_batchedinterfaces - Added a `WorldQueryBatch`` trait to support batched queries
- Performance related changes for batches:
- Added a
MAX_SIMD_ALIGNMENTconstant that table columns are aligned to (at minimum) (cache related) BlobVecs are now aligned toMAX_SIMD_ALIGNMENTto support batching use cases and better performance (aligned loads)SimdAlignedVectype was added to provideMAX_SIMD_ALIGNMENTon the inner buffer, providingVec-like semantics (aligned loads)
- Added a
- Tests have been added for the new functionality
- Docs too (with runnable examples)
- Benchmarks provided directly in the Bevy tree (requires AVX to run! Add
-Ctarget-feature=+avxto yourRUSTFLAGSon x86)
A detailed discussion can be found in #1990 , including benchmarks justifying why batched queries are worth implementing. Older benchmarks can be found here: https://github.com/inbetweennames/bevy-simd-bench
Migration Guide
No breaking changes.
Fixes #6161
Wow, you're fast!! I will see about getting these finished in the coming days, thanks for your patience :)
Happy Thanksgiving!
Hah, I'm glad I wrote tests. Found a few soundness issues thanks to the Miri CI we have here. You bet I'll be running that locally now too :) fortunately the issues weren't fundamental.
Currently working on the remaining documentation related problems now that the soundness issues have been resolved.
There's a few ways of using the API and the current example only shows the more "advanced" way with repr(transparent). It's now possible to more easily use batches with a non-"transparent" API using the map and as_array functions of the AlignedBatch trait. The tradeoff is that it seems to optimize worse -- the Rust docs seem to indicate that the performance situation is a little finicky with array maps. In a quick test I did, I saw loads and stores that could have been easily optimized out appearing in the assembly. The docs recommend using the iter() API instead -- maybe I'll play around with that later this week after I clean up the docs a bit more.
Thanks very much for your comments @BoxyUwU -- this is a learning experience in Rust for me and I'll work at addressing yours (and the rest of @alice-i-cecile 's ) comments over the next few weeks. I think delaying until GATs are stable makes sense and I can actually start readying the code for that in the meantime. Thank you for your patience :)
Next up on my list is to get one of the Bevy examples going with batched queries (in a very limited way) to demonstrate batched queries a bit better. Thanks for your comments and your patience everyone.
@InBetweenNames can you please mark in the PR description that this Fixes #6161 so that it gets auto-closed when this is merged? I'll give this a review soon. This has been quite the API hole compared to what Unity's ECS has that Bevy sorely needs.
@InBetweenNames can you please mark in the PR description that this
Fixes #6161so that it gets auto-closed when this is merged? I'll give this a review soon. This has been quite the API hole compared to what Unity's ECS has that Bevy sorely needs.
Not a problem! I have some more changes coming down the pipeline when I get the energy to make the API a little friendlier. With the stabilization of GATs being imminent, I'd like to clean up the code with those (not a big change), and also restructure for_each_mut_batched to work similar to the following:
for_each_mut_batched::<4>( |((mut a, Align16), (b, Align32))| {
println!("a: {:?} b: {:?}", a, b);
} );
That is, the Align parameter now becomes per-component, which is way more flexible. As a bonus, I can provide a for_each_mut_batched variant that doesn't care about alignment -- with the usual caveats that would imply in terms of codegen.
For the above example, such a variant would be equivalent to:
for_each_mut_batched::<4>( |((mut a, Unaligned), (b, Unaligned))| {
println!("a: {:?} b: {:?}", a, b);
} );
Simple, safe, effective :)
Can't promise any timelines for that (hopefully this month), but I am working on it in the evenings here. Bevy is in a very unique position to provide HPC primitives like this :) Down the pipeline, we can look at avoiding false-sharing in a type-safe and compile time checked manner when doing batching across multiple threads, too. That's my dream toolkit for simulations right there :)
Alright, managed to get this ported over to the new GAT way of doing things and simplified a lot in the process. However, the per-component alignment feature isn't implemented yet. I'm going to try seeing if I can use typenum to automatically compute it, which would keep things still relatively simple while still not relying on generic const expressions (which seem to have some foundational problems). I've moved the PR over to "draft" status as I don't think it should be merged before alignments can be manually set per component or they can be automatically computed. Still, it's worth reviewing the changes so far as what is committed shouldn't change drastically after those "feature complete" changes are in.
I took a little detour to try out what this would look like if generic_const_exprs were stable, and it's actually really nice:
q.for_each_mut_batched::<4>(
|(mut position, velocity)| {
//Scalar path
},
|(mut position, velocity)| {
//Batched path
});
Code provided here: https://github.com/inbetweennames/bevy/tree/generic_const_exprs
All alignments automatically computed, absolutely zero work needs to be done by the user to do anything with alignments, and the autovectorizer loves it. The type is very simple to understand too: AlignedBatch<T, N> automatically has the correct batch alignment computed using the gcd! Literally all the user needs to do is select the batch size N, provide a scalar and vector path, and the rest is taken care of for you. It really is that nice.
(One can dream!)
Obviously I can't propose that for merging, but it does serve as an important design validation point that you really can make some trivial changes to the code once it is possible to evaluate const expressions in generics and just have this for free. I suppose this could be hacked in with typenum too, maybe... might be worth a shot.
Bad news :( ... even with the typenum hackery, it seems this can't be done on stable as it's not possible to get the size of a type T as a typenum without using generic_const_exprs. Therefore, it seems the best we can do (for now, on stable) is implement the per-component manual alignments as described previously. That's okay, because the "unaligned" variant can then be promoted to "alignments automatically derived" without code changes once generic_const_exprs are stable, and the manual aligned version can easily migrated off. I'll go ahead and start working on that. The API is still very usable this way :)
I was wrong!
It is indeed possible to do this with typenum, but it makes the code a giant mess, and likes to cause internal compiler errors in rustc. It requires a patched typenum that supports const generics (a U<N> = UN type) and a new trait, SizeOfAsTypenum, which can be conveniently hacked into the derive macro for Component. SizeOfAsTypenum defines a type Output that is set by the implementor to be the size of the type as a typenum. Since this is not a generic context, it is indeed possible to use sizeof here :) (it looks like type Output = U< { sizeof::<T>() }>, hence the dependency on the patched typenum). SizeOfAsTypenum needs to be manually implemented for other, non-component types, which isn't great (and attempting to provide an implementation generically will, of course, require generic_const_exprs).
However, even without the ICEs, this is still a gigantic hack and (I expect) unlikely to be accepted. I think given the options of pushing a little bit of complexity onto the user versus putting a lot of complexity in Bevy to automatically derive the minimum alignments (on stable Rust), it makes sense to prefer the former path. This still provides for a clean upgrade path when generic_const_exprs are stable that reduces both user and implementation complexity compared to the manual alignment approach.
iamthetypesystem.jpg
Small update -- I was unable to get to the proposed implementation without (again) hitting the limits of the type system in Rust as it currently exists. So the proposed:
for_each_mut_batched::<4>( |((mut a, Align16), (b, Align32))| {
println!("a: {:?} b: {:?}", a, b);
} );
isn't implementable without generic_const_exprs, which if those were stable, we'd just use the automatic approach that already has been proven to work in the branch I discussed earlier. I'll discuss the exact limitation of Rust's type system in a moment that gets us in trouble, but first I want to discuss what I think is a suitable compromise:
//Align32, Align16, etc, are just type synonyms for Align<N> from the `elain` crate
//type Unaligned = Align<1>;
q.for_each_mut_batched::<4, (Align32, Align8, Align16, Unaligned)>(
|(mut a, b, c, d)| {
//scalar
},
|(mut a, b, c, d)| {
//batched
});
The above works just fine and is what I'm going to propose for merging after I clean it up a bit and move the definitions to a new file. The main difference is that the alignments can't be passed inline with the arguments as before -- they must be passed as a generic parameter. Unfortunately, Rust's type system again strikes here, where it is not possible to default this to "Unaligned" (i.e. Align<1>). The reason for this is discussed in this thread (most recent comment linked):
https://github.com/rust-lang/rust/issues/36887#issuecomment-1041515594
However, another approach is easily worked around for this: we provide a new function where this is defaulted using another associated type, for the unaligned case. That machinery is pretty unobtrusive, even if it is a bit of a hack. Unfortunately, that machinery is more verbose than it needs to be due to associated_type_defaults again not being stable lol. Still, it's not too bad.
If you want the power of stipulating manual alignments because you need that, it is in your hands -- otherwise, no need to worry about it. This should help discoverability of batching and vectorization in general.
On the topic of discoverability, what I propose is to make the "Unaligned" interface the default for simplicity, as there's only a handful of architectures that really care about alignment hints, or have instruction opcodes that demand aligned operands.
For example, x86-64-generic targets SSE2, and a good chunk of SSE2 instructions demand naturally aligned operands. Therefore, without being able to prove natural alignment, the compiler must emit more movup* instructions for the generic x86-64 target and do work in registers, which will hurt performance. So, Align<16> clearly helps here. Even though newer processors don't make a distinction between "aligned" and "unaligned" variants of instructions (the "unaligned" variant performs as fast as "aligned" so long as the data is actually well aligned), you still pay a price for something you're not using because of this. Older processors will of course pay a much steeper price. As another example, armv7a with NEON also accepts alignment hints (which are free to be ignored by the implementation).
Truly modern architectures (things made in the last 10 years)
Of course, truly modern x86 (AVX support and above) makes the full instruction set available for unaligned operands thanks to VEX/EVEX encodings. AArch64 in a similar vein has no "aligned" variants of instructions at all. In both cases, full performance is achieved if the memory operands are naturally aligned, but the instructions don't need to encode that alignment themselves -- meaning there is nothing for your compiler to really do here. We could simply ignore alignment and follow suit, simplifying this PR, but I want to stress that AVX is not in the default enabled instruction sets for x86-64. Even if we move the x86-64-v2, that only enables SSE4_2. It takes x86_64-v3 and above to enable AVX support in the compiler, and so far, I've only seen discussion about moving the default x86-64 target to v2. Also, if Bevy were to ever run on embedded platforms, you'd really want this to eek out every last drop of performance possible. Or, maybe running Bevy systems or queries someday as GPU kernels?
Type madness
I saved this part for the end to not have to inflict it on poor souls casually passing by. You've been warned!
The exact limitation I ran into when trying to implement the former interface is that Rust GATs unfortunately only mirror Haskell's "type families" (which represent "injective" relationships) and there is no way to assert that the combination of alignment specifiers is "unique" with respect to a trait. In formal language terms, you say there is a possibility of "ambiguity" here. The other side of higher kinded types is the ability to model bijective relationships, where you can indeed make that assertion and "work backwards". At the call site, when we say, for example, |Batch16(mut a), Batch8(b), Batch4(c), Batch32(d)|, without that kind of functional dependency (sometimes called fundep in Haskell space), there is no way to assert to Rust that there is exactly one appropriate derivation for that sequence of arguments. Things get even more complicated when you consider weird queries like Query<(&A, (&B, (&C, &D)))>, which are nested. Even if you enforce a flat hierarchy by introducing a new trait (say, WorldQueryBatchBase) to exclude this possibility, having WorldQueryBatch impls for the query tuples depend on those , without generic_const_exprs you can't have WorldQueryBatchBase::fetch_batched return some kind of BatchT<Self::MIN_ALIGN, Self::FullBatchType>, as MIN_ALIGN would have to be chosen by the implementor 🙃...
Conclusion
So... I'm fairly confident that on stable rust, the new proposed interface at the start of this post is the best we can do, with an "unaligned" and a separate "manually aligned" interface for the use cases outlined above. When generic_const_exprs are stable someday, we can eliminate the "manually aligned" variant and automatically upgrade users of the "unaligned" variant to the "automatically aligned" version without breaking any backwards compatibility as the interface is the exact same.
Until next time!
OK, per the discussion on the Bevy ecs-dev channel on Discord with @james7132 @alice-i-cecile and Joy (sorry, can't find your handle on here!), we decided to support best-in-class performance only on modern architectures (x86 w/ AVX, arm64, etc, things largely made since 2010) in the interests of keeping the code maintainable. These architectures do not encode alignment into instruction opcodes and solely rely on memory operands themselves to be aligned to achieve maximum performance. By doing this, we can encode a batch as being simply [T; N].
This is in contrast to older x86, where with e.g., SSE2, memory operands were required to be aligned in the vast majority of cases (movu* not withstanding), meaning if the compiler could not prove an access was naturally aligned, it would have to emit code assuming it would not be, which necessarily would require more unaligned loads and doing work in registers. Intel Nehalem made movu* perform the same as mova* if memory operands were aligned, but still a price would be paid in terms of code size when natural alignment could not be proven. AVX (with the VEX prefix) removed these alignment restrictions entirely, allowing memory operands to refer to unaligned memory. However, to get full performance on AVX and onwards, one still needs to ensure memory operands are aligned -- it just means it's not a requirement of the CPU. This means that it is sufficient to align your data in memory to achieve full performance, and let the CPU take care of the rest.
Most newer architectures take this approach, including RISC-V and ARMv8 64-bit and onwards. ARMv8 32-bit still retains the alignment hint qualifier for NEON instructions, but it was always implementation dependent whether those did anything anyway. ARM64 NEON and SVE discards them entirely. WebAssembly SIMD follows a similar vein.
Originally, this PR was written to guarantee maximum performance on all architectures, no matter how old or esoteric. However, the code complexity was a little high to achieve this, and maintainability concerns have been raised. As fun as it is doing code golf to support all of this, at the end of the day, we have to be practical about what we can maintain as a community.
Note that in the future, when generic_const_exprs are stable, it will be possible to introduce an AlignedBatch type as we did before and automatically compute the batch alignment using the gcd, also restoring performance for architectures that encode alignment in opcodes, or are sensitive to alignment hints, without much added complexity. I expect that's far off though, given the state of that feature in nightly. Heh, who knows, maybe I should go work on that 😆
According to Steam's hardware statistics, AVX has a 95% market penetration, so on the x86 front, we should be quite safe. On the odd chance someone can't run AVX, an SSE2 version of the binary could be made available. SSE2 will still continue to work, but at a slight penalty relative to what it could be.
So, the next iteration of this PR will be reworked as follows:
- A batch will be
[T; N], with TODOs for whengeneric_const_exprsbecome stable for guaranteeing max performance on all target configurations - The documentation will be updated to reflect that AVX should be preferred when building on x86 (with a quick howto on enabling that, since it is off by default)
I'm not sure where this should be written down, exactly, but it's better to have it here than have it nowhere haha. If there's a better place to document this, feel free to steal the text above or point me at the right place. Thanks again for your input everyone!
Small update; code has been reworked, but I'm trying to find a way to recommend using batches without using the array map function, which optimizes horribly for some reason. TransparentWrapper from bytemuck may be the way to go, but I'll be exploring options over the coming days. If anyone has ideas on how to do this, your advice would be most welcome. It may be that we just recommend people to unroll their batches manually such as let [Position(p1), Position(p2), ..., Position(pn)] = batch to handle these kinds of cases.
So it seems array::map can be fixed, and there is work upstream on doing that: here and here. It is also possible to provide a new trait to use the proposed implementations that fix these problems, e.g. ArrayMap. I found in my own tests, taking the array by reference instead of by value (move) was sufficient for the compiler to generate sane code for a map function. Of course, this is solely to work around the poor performance of array::map. Since it seems like the upstream implementation is likely to be fixed in the next 6 months, I'm going to go forward and recommend users unroll their batches manually as mentioned before. There's no sense in introducing a new trait due to an upstream bug IMO, which would be obsolete as soon as it's fixed.
It's curious that the upstream API takes the array by move -- it seems there's no real benefit to doing that and it makes the function harder to optimize. I should try to dig up some of the discussion around array_map and figure out what's going on there.
With that said, all that's left to do is update the examples and docs and satisfy the CI here. At which point, I'll mark this again for review. Shouldn't be too long now :)
I have an idea for a new example to showcase this PR, but I haven't had time to get it implemented with benchmarks and everything. However, I think the actual code itself is ready for review.
A universal "batching is always better" example is very hard to write, because hardware isn't universal. The best I've been able to come up with, in stable rust at least, is using x86 AVX intrinsics directly to perform a layout transform and doing some math that way. AVX intrinsics are not beginner friendly though, and I'm concerned about putting those into an example that is intended to be beginner friendly. std::simd helps here, but it isn't available in stable Rust unfortunately -- and has it's own problems (that appear to be being worked on).
I think some properties for a good enough example would be:
- Has to be realistic, not contrived in any way: e.g., collision detection, some kind of physics, etc
- If it uses
core::archintrinsics, has to be relatively portable, and can't use anything "too deep"- If it doesn't, and it relies on autovectorization, then it must be very obvious, because rustc/LLVM is fickle between versions on what it will autovectorize and what it won't.
- It can't be too complicated: ideally it shouldn't define a bunch of types, etc, and should be short
- It shouldn't be worse than letting
rustcautovectorize everything.
So far, I have a contrived example involving explosions and damage calculations, but I fear it's not super realistic with what you might actually see in a game. I was thinking maybe a collision detection off a solid plane would make more sense to implement, and might not be too much longer.
For now, I took out the old example because it wasn't very good -- on recent rustcs, it got unrolled and autovectorized optimally, making batching actually perform worse as rustc couldn't optimize the batched version as easily.
From this point onwards I'll focus on the documentation and seeing what we can do for a cool "intro example" for vectorized queries.
For anyone curious what a raw AoS -> SoA transform looks like in AVX, see the following snippet:
// 8 Vec3s loaded into three YMM registers:
// r0 = [x0 y0 z0 x1 y1 z1 x2 y2]
// r1 = [z2 x3 y3 z3 x4 y4 z4 x5]
// r2 = [y5 z5 x6 y6 z6 x7 y7 z7]
let ymm9 = _mm256_blend_ps::<0b10010010>(r0, r1);
let ymm10 = _mm256_blend_ps::<0b10010010>(r1, r2);
let ymm11 = _mm256_blend_ps::<0b11110000>(r1, r2);
let ymm12 = _mm256_permute2f128_ps::<0b00100001>(r0, r2);
let ymm11 = _mm256_shuffle_ps::<0b00010010>(ymm12, ymm11);
let x = _mm256_shuffle_ps::<0b10001100>(ymm9, ymm11);
let ymm4 = _mm256_blend_ps::<0b00100100>(ymm10, r0);
let ymm10 = _mm256_permute2f128_ps::<0b00100001>(r2, r1);
let ymm4 = _mm256_shuffle_ps::<0b11001001>(ymm4, ymm10);
let y = _mm256_permute_ps::<0b01111000>(ymm4);
let ymm10 = _mm256_permute2f128_ps::<0b00000001>(r1, r1);
let ymm5 = _mm256_blend_ps::<0b01001001>(r1, r2);
let ymm8 = _mm256_shuffle_ps::<0b00100001>(ymm10, ymm5);
let z = _mm256_shuffle_ps::<0b11000010>(ymm8, ymm5);
// x = x0 x1 x2 x3 x4 x5 x6 x7
// y = y0 y1 y2 y3 y4 y5 y6 y7
// z = z0 z1 z2 z3 z4 z5 z6 z7
I really want to avoid using something like that in the example. It's standard AVX code, but it's in no way accessible to beginners.
Some benchmarks from the latest commit, using the contrived "explosion" example:

Legend:
- soa* -- these represent direct "SoA" style components, where e.g. a Position is broken up into separate X, Y and Z components.
- aos* -- these represent "AoS" style components, where e.g., a Position is represented as a Vec3
- batch_N -- this indicates the query was executed with a batch size of N
- swizzle -- for "aos" runs, this indicates that the components were "swizzled" using something like the above AoS -> SoA transform to get the data in the desired shape for SIMD
- nochangedetect -- a leftover from earlier code, all runs were executed bypassing change detection
The "aos_nochangedetect" and "soa_nochangedetect" runs were just straight Query iteration using for_each_mut, no batching at all. This represents the autovectorizer's attempt at optimizing the code -- if it could do so at all. Notice that the autovectorizer behaved a lot better with the SoA layout than the AoS layout. I believe this to be worth looking more at in the future :)
The code for the benchmarks can be found in my other repository, https://github.com/inbetweennames/bevy-simd-bench (The code isn't the cleanest, it's really just set up for testing this out).
Hey all, just lettying you know I haven't forgotten about this. I've found a suitable example using collision detection that is easy to explain and directly benefits from batched queries. It's simply doing an inside/outside test of a convex polygon with respect to a set of entities. So we've got some dot products, comparisons, etc, but nothing crazy, and it's something you might expect to see in an actual game. Currently working on getting that written up in a non-ugly way for inclusion. Unfortunately, due to std::simd being unstable, I have to write it using core::arch intrinsics. I hope that's not a dealbreaker!
On a side note, Rust seriously needs some kind of copy elision baked into the standard:
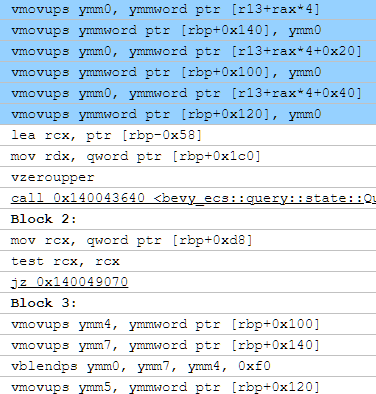
What you're seeing here is literally the following:
"copy this crap to my stack, then load the stuff i just copied into my stack into registers"
This seems to be a similar problem as we've seen with array::map, where copies aren't elided when they could be. In C++, we have guaranteed copy elision which helps in some cases as this gets enforced in the language frontend. In Rust, it seems that the lower levels of the stack are relied upon to get rid of extraneous copies, but it's a little flakey.
Otherwise, even with that shortcoming, the code still outperforms its scalar and autovectorized counterparts.
On the topic of benchmarks, it's my hope that I can move the ones out of my bevy_simd_bench repo into the main tree without much fuss.
On the topic of benchmarks, it's my hope that I can move the ones out of my bevy_simd_bench repo into the main tree without much fuss.
Excellent: these will be much easier to merge in their own PR.
The new example and associated benchmark are up. Results look good!

This benchmark has been included in the main Bevy benchmark suite. To run it, ensure you have AVX enabled -- the suite will exclude it it isn't enabled.
The worst case shown is the autovectorized path -- or the lack thereof. Following that is the AVX path with a width of 4 (SSE4 with the VEX prefix), and after that is AVX with a width of 8.
@alice-i-cecile @james7132 @BoxyUwU @TheRawMeatball I think this is now fully ready for review!
For example usage, see this benchmark 😄 -- it has been included in the docs too.
Awesome :D I'll aim to do a full review by the end of next Monday: there's a ton of ECS work in the air right now.
Sounds good, no rush! :)
EDIT: Hmm weird, I guess I don't know the review request interface that well... didn't mean to remove the requests for reviews.
No changes in the latest commit; just rebased. I see some new verbiage in main about "BatchedStrategies" for parallel queries. That's cool -- just wondering if maybe a different name should be given to this different concept introduced in this PR to avoid confusion. While similar, the intent is different: the batching introduced in this PR is about processing batches of N components at a time using SIMD, whereas parallel batch sizes appear to be more about managing overhead and synchronization costs when executing a query across multiple threads. I'm open to suggestions here :)
When #6773 is merged, I'll port this over to using the new style of iteration.
FYI: did a little reading into the naming convention behind this concept. EnTT refers to it as "chunked iteration": https://github.com/skypjack/entt/issues/462
How do we feel about using the name "chunk" instead of "batch" for this PR, to set it apart from other uses of "batch" in Bevy? Is there a better name we could use instead?
[7:27 AM] james7132: On closer inspection, I don't think the batched queries is going to be ready for 0.11 (or even 0.13 at this rate), it's reliance on unstable rust features is probably a non-starter for it.
From @james7132 on Discord. If you can find a way to make it work without this, or convince us that the assessment is wrong / it's worth making an exception, let us know.
Similarly, if you need us to make changes to the internals to allow 3rd party crates that need unstable Rust features to implement this externally, we're also generally very open to that!
Hey Alice, this was an old comment that was addressed already. This code does not rely on any unstable rust features. Thank you!
On Tue, Feb 28, 2023, 8:22 a.m. Alice Cecile @.***> wrote:
[7:27 AM] james7132: On closer inspection, I don't think the batched queries is going to be ready for 0.11 (or even 0.13 at this rate), it's reliance on unstable rust features is probably a non-starter for it.
From @james7132 https://github.com/james7132 on Discord https://discord.com/channels/691052431525675048/749335865876021248/1080103960943267911. If you can find a way to make it work without this, or convince us that the assessment is wrong / it's worth making an exception, let us know.
Similarly, if you need us to make changes to the internals to allow 3rd party crates that need unstable Rust features to implement this externally, we're also generally very open to that!
— Reply to this email directly, view it on GitHub https://github.com/bevyengine/bevy/pull/6161#issuecomment-1448173367, or unsubscribe https://github.com/notifications/unsubscribe-auth/AB3VLDEEHERTHWTCNL26MULWZX32LANCNFSM6AAAAAAQ4QFHE4 . You are receiving this because you were mentioned.Message ID: @.***>
Sorry about that, must have been reading an old version of the PR. Really shouldn't be doing this stuff at 4AM, haha.
Quick pass seems to suggest we can aim for a 0.11 timeline for this. I really want something like this to help round out the last bits of CPU performance we may be lacking in the ECS.