bevy
 bevy copied to clipboard
bevy copied to clipboard
Basic adaptive batching for parallel query iteration
Objective
Fixes #3184. Fixes #6640. Makes #4798 obsolete. Using Query::par_for_each(_mut) currently requires a batch_size parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the World it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the World.
Background
Query::par_for_each(_mut) schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of max {archetype, table} size / thread count * COUNT_PER_THREAD is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
Solution
- [x] Remove the
batch_sizefromQuery(State)::par_for_eachand friends. - [x] Add a check to compute
batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD - [x] ~~Panic if thread count is 0.~~ Defer to
for_eachif the thread count is 1 or less. - [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
Changelog
Removed: batch_size parameter from Query(State)::par_for_each(_mut).
Migration Guide
The batch_size parameter for Query(State)::par_for_each(_mut) has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
fn parallel_system(
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
After:
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
To get this API surface to work, I needed to merge in #4705, so I won't take this out of draft until it or an equivalent PR gets merged.
With #4705 merged, this is basically ready to come out of draft. I still need to update docs and do some basic benchmarking, but the base change is ready for review.
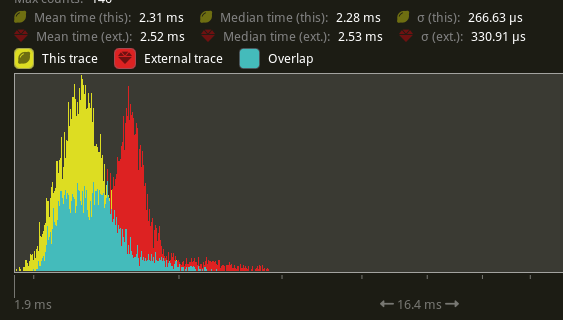
Now that #4489 has been merged, I was able to test this on many_cubes with the check_visibility system, which is the single system in the engine that uses this. This saw a drop from 2.53 ms -> 2.28 ms, a 9.09% improvement.
Below is the change in distribution on my machine, yellow is this PR, red is main.
Great stuff! This will allow much more convenient parallel queries.
Small suggestion, adding the ability to override globally the batch size estimation with a resource enum like:
pub enum BatchSizeBehaviour {
/// The batch size will be `artifact_count / thread_count`
Auto,
/// Custom batch size
Overridden(usize),
/// Custom
Custom(Box<dyn Fn(&ComputeTaskPool, &QueryFetch) -> usize>)
}
That would completely remove the potential need for stuff like https://github.com/bevyengine/bevy/pull/5025
Edit: Also, I don't know if the estimation method is expensive, but if it is, a resource could come in handy to maybe put the etimated value in a cache?
The estimated value comes from iterating over all matched tables or archetypes, something parallel iteration already does on the dispatch thread to begin with. If anything it makes the actual task spawning faster by getting the archetype or table metadata into the CPU cache before spawning tasks.
There are probably some degenerative cases where a query matches an enormous number of otherwise empty or near empty archetypes or tables, but I think we'd want to see some real world use cases for them first.
I'd like to see some perf numbers for varying the batch multiplier and number of threads to see if 4 is a good default. Ideally we'd do this against more workloads than just #4777. Are there any open PR's that we could also use for benching?
In retrospect, testing on that system is likely a poor choice without #4663 due to the contention on the channel. There's also #4775, which could be tested, but that's one where we might want to revisit the parallelism strategy too due to the way the system runs. Unfortunately there aren't many options for an idealized case here right now, at least not until #4663 is merged.
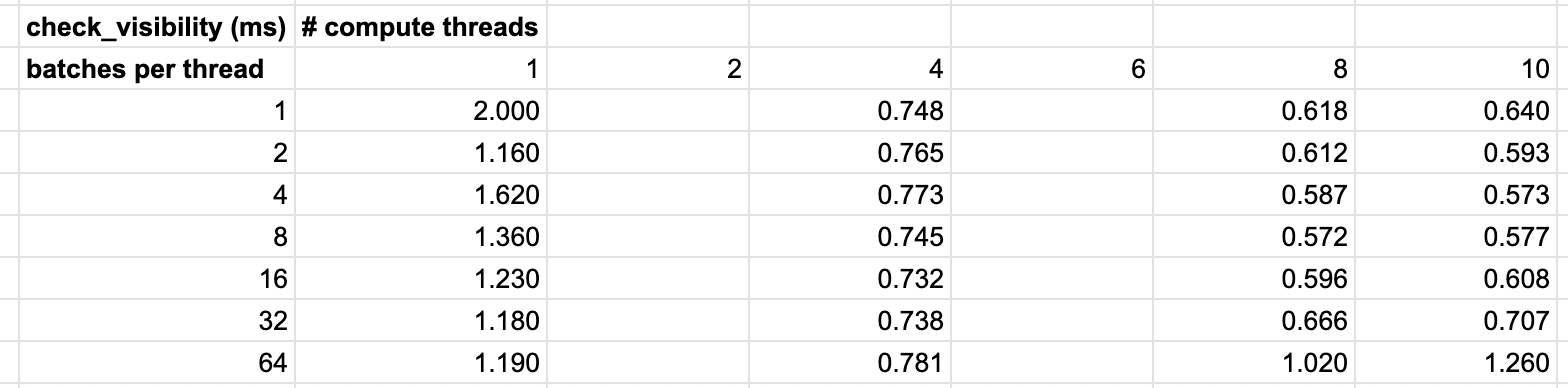
With #4663 merged, the timing on each batch is more consistent now and is more reflective of the "equal amount of work per entity" than before. Here are some updated timings while varying the batches per thread:
| attempt | timing |
|---|---|
| main (static 1024) | 1.67ms |
| 1 batch per thread | 996.43us |
| 2 batches per thread | 1.05ms |
| 4 batches per thread | 1.26ms |
| 8 batches per thread | 2.07ms |
I ended up with very different results on my machine. Looking at check_visibility, my main was 1.46ms. I tried varying the batch size and it performed best for me with a batch size of 32 and a mean time of 1.44ms. I also varied the thread count. Main with 12 threads took 1.27ms and a batch size of 32 took 1.23.
My full results of the things I tested:

Methodology
- set threads with DefaultTaskPoolOptions options
- changed the batches_per_thread in BatchingStrategy::new()
- ran tracy with capture.exe -o -s 180
- removed spans for par_for_each
Edit: I'm not too surprised that the numbers between main and my testing are similar, since the batch size there was optimized a bit. Also there's 160000 cubes / 1024 (batch size) = 156.25 batches and 6 threads * 32 batches = 192 batches, so these numbers are close-ish.
5600x (6 cores/12 logical)
The only reason I haven't approved this yet is that james7132 have different values (1 vs 32) for best batches/thread. We need some more data points from other cpus to determine a good default.
Results from an M1 Max, running many_cubes -- sphere for 1500 frames:
With this patch:
diff --git a/crates/bevy_ecs/src/query/state.rs b/crates/bevy_ecs/src/query/state.rs
index 60643ace4..014ad7ab5 100644
--- a/crates/bevy_ecs/src/query/state.rs
+++ b/crates/bevy_ecs/src/query/state.rs
@@ -936,15 +936,15 @@ impl<Q: WorldQuery, F: WorldQuery> QueryState<Q, F> {
func(item);
}
};
- #[cfg(feature = "trace")]
- let span = bevy_utils::tracing::info_span!(
- "par_for_each",
- query = std::any::type_name::<Q>(),
- filter = std::any::type_name::<F>(),
- count = len,
- );
- #[cfg(feature = "trace")]
- let task = task.instrument(span);
+ // #[cfg(feature = "trace")]
+ // let span = bevy_utils::tracing::info_span!(
+ // "par_for_each",
+ // query = std::any::type_name::<Q>(),
+ // filter = std::any::type_name::<F>(),
+ // count = len,
+ // );
+ // #[cfg(feature = "trace")]
+ // let task = task.instrument(span);
scope.spawn(task);
offset += batch_size;
}
@@ -979,15 +979,15 @@ impl<Q: WorldQuery, F: WorldQuery> QueryState<Q, F> {
}
};
- #[cfg(feature = "trace")]
- let span = bevy_utils::tracing::info_span!(
- "par_for_each",
- query = std::any::type_name::<Q>(),
- filter = std::any::type_name::<F>(),
- count = len,
- );
- #[cfg(feature = "trace")]
- let task = task.instrument(span);
+ // #[cfg(feature = "trace")]
+ // let span = bevy_utils::tracing::info_span!(
+ // "par_for_each",
+ // query = std::any::type_name::<Q>(),
+ // filter = std::any::type_name::<F>(),
+ // count = len,
+ // );
+ // #[cfg(feature = "trace")]
+ // let task = task.instrument(span);
scope.spawn(task);
offset += batch_size;
diff --git a/crates/bevy_render/src/view/visibility/mod.rs b/crates/bevy_render/src/view/visibility/mod.rs
index c1bffec3f..e0f0eede3 100644
--- a/crates/bevy_render/src/view/visibility/mod.rs
+++ b/crates/bevy_render/src/view/visibility/mod.rs
@@ -5,7 +5,7 @@ pub use render_layers::*;
use bevy_app::{CoreStage, Plugin};
use bevy_asset::{Assets, Handle};
-use bevy_ecs::prelude::*;
+use bevy_ecs::{prelude::*, query::BatchingStrategy};
use bevy_reflect::std_traits::ReflectDefault;
use bevy_reflect::Reflect;
use bevy_transform::components::GlobalTransform;
@@ -174,51 +174,63 @@ pub fn check_visibility(
let view_mask = maybe_view_mask.copied().unwrap_or_default();
visible_entities.entities.clear();
- visible_entity_query.p1().par_iter().for_each_mut(
- |(
- entity,
- visibility,
- mut computed_visibility,
- maybe_entity_mask,
- maybe_aabb,
- maybe_no_frustum_culling,
- maybe_transform,
- )| {
- if !visibility.is_visible {
- return;
- }
-
- let entity_mask = maybe_entity_mask.copied().unwrap_or_default();
- if !view_mask.intersects(&entity_mask) {
- return;
- }
-
- // If we have an aabb and transform, do frustum culling
- if let (Some(model_aabb), None, Some(transform)) =
- (maybe_aabb, maybe_no_frustum_culling, maybe_transform)
- {
- let model = transform.compute_matrix();
- let model_sphere = Sphere {
- center: model.transform_point3a(model_aabb.center),
- radius: (Vec3A::from(transform.scale) * model_aabb.half_extents).length(),
- };
- // Do quick sphere-based frustum culling
- if !frustum.intersects_sphere(&model_sphere, false) {
+ visible_entity_query
+ .p1()
+ .par_iter()
+ .batching_strategy(
+ BatchingStrategy::new().batches_per_thread(
+ std::env::args()
+ .nth(3)
+ .and_then(|arg| arg.parse::<usize>().ok())
+ .unwrap(),
+ ),
+ )
+ .for_each_mut(
+ |(
+ entity,
+ visibility,
+ mut computed_visibility,
+ maybe_entity_mask,
+ maybe_aabb,
+ maybe_no_frustum_culling,
+ maybe_transform,
+ )| {
+ if !visibility.is_visible {
return;
}
- // If we have an aabb, do aabb-based frustum culling
- if !frustum.intersects_obb(model_aabb, &model, false) {
+
+ let entity_mask = maybe_entity_mask.copied().unwrap_or_default();
+ if !view_mask.intersects(&entity_mask) {
return;
}
- }
-
- computed_visibility.is_visible = true;
- let cell = thread_queues.get_or_default();
- let mut queue = cell.take();
- queue.push(entity);
- cell.set(queue);
- },
- );
+
+ // If we have an aabb and transform, do frustum culling
+ if let (Some(model_aabb), None, Some(transform)) =
+ (maybe_aabb, maybe_no_frustum_culling, maybe_transform)
+ {
+ let model = transform.compute_matrix();
+ let model_sphere = Sphere {
+ center: model.transform_point3a(model_aabb.center),
+ radius: (Vec3A::from(transform.scale) * model_aabb.half_extents)
+ .length(),
+ };
+ // Do quick sphere-based frustum culling
+ if !frustum.intersects_sphere(&model_sphere, false) {
+ return;
+ }
+ // If we have an aabb, do aabb-based frustum culling
+ if !frustum.intersects_obb(model_aabb, &model, false) {
+ return;
+ }
+ }
+
+ computed_visibility.is_visible = true;
+ let cell = thread_queues.get_or_default();
+ let mut queue = cell.take();
+ queue.push(entity);
+ cell.set(queue);
+ },
+ );
for cell in thread_queues.iter_mut() {
visible_entities.entities.append(cell.get_mut());
diff --git a/examples/stress_tests/many_cubes.rs b/examples/stress_tests/many_cubes.rs
index 6ced37ee1..844584f2d 100644
--- a/examples/stress_tests/many_cubes.rs
+++ b/examples/stress_tests/many_cubes.rs
@@ -11,13 +11,27 @@
//! `cargo run --example many_cubes --release sphere`
use bevy::{
+ core::TaskPoolThreadAssignmentPolicy,
diagnostic::{FrameTimeDiagnosticsPlugin, LogDiagnosticsPlugin},
math::{DVec2, DVec3},
prelude::*,
};
fn main() {
+ let n_compute_threads = std::env::args()
+ .nth(2)
+ .and_then(|arg| arg.parse::<usize>().ok())
+ .unwrap();
App::new()
+ .insert_resource(DefaultTaskPoolOptions {
+ compute: TaskPoolThreadAssignmentPolicy {
+ min_threads: n_compute_threads,
+ max_threads: n_compute_threads,
+ percent: 1.0,
+ },
+ ..default()
+ })
.add_plugins(DefaultPlugins)
.add_plugin(FrameTimeDiagnosticsPlugin::default())
.add_plugin(LogDiagnosticsPlugin::default())
@james7132
From an earlier comment:
As I proposed on Discord, it might be a good idea to schedule one task per thread, and just push the archetypes/batches through a SPMC channel. It'd be likely be lighter weight than scheduling a new task per archetype or batch.
Why wasn't this implemented instead? Why does this PR keep the old approach?
As I proposed on Discord, it might be a good idea to schedule one task per thread, and just push the archetypes/batches through a SPMC channel. It'd be likely be lighter weight than scheduling a new task per archetype or batch.
It probably doesn't work well if all the threads aren't available, since there's no task stealing in this model.
Why wasn't this implemented instead? Why does this PR keep the old approach?
Actually completely slipped my mind why I didn't. Even then, I would like to avoid conflating the performance differences of both adaptive batching and a channel based approach in a single PR.
It probably doesn't work well if all the threads aren't available, since there's no task stealing in this model.
The work stealing here definitely helps smooth out the workload across each thread. However, even with that said, the idea of decreasing contention on the global executor, using a fixed sized channel to minimize allocator time, fewer atomics per batch, and potentially not needing to yield time to park threads is pretty appealing.
I was holding off from merging this, even with multiple ECS SME approvals, as there was a regression with check_visibility in many_foxes due to it generating too many small tasks, (216us -> 316us), though the other internally parallel systems showed no significant changes.
Checking against many_cubes, this does have a much higher benefit, showing a near 3x speedup in PostUpdate (2.05ms -> 896.43us).

This does seem to suggest we're oversplitting on worlds with too many archetypes or too many threads with small archetypes, while also delivering on reducing scheduling overhead on times when we're underclustering the batches before.
As mentioned before, in the interest of both improving developer UX for parallel iteration, probably best not to block this PR any further and make changes to the heuristics and tuning in followup PRs.
bors r+
Pull request successfully merged into main.
Build succeeded:
- build-and-install-on-iOS
- build-android
- build (macos-latest)
- build (ubuntu-latest)
- build-wasm
- build (windows-latest)
- build-without-default-features (bevy)
- build-without-default-features (bevy_ecs)
- build-without-default-features (bevy_reflect)
- check-compiles
- check-doc
- check-missing-examples-in-docs
- ci
- markdownlint
- msrv
- run-examples
- run-examples-on-wasm
- run-examples-on-windows-dx12