bevy
 bevy copied to clipboard
bevy copied to clipboard
Internalize task distinction into TaskPool
Objective
Fixes #1907. IO and Async Compute threads are sitting idle even when the compute threads are at capacity. This results in poor thread utilization.
Solution
Move the distinction between compute, async compute, and IO threads out of userspace, and internalize the distinction into TaskPool. This creates three tiers of threads and tasks: one for each group. Higher priority tasks can run on lower priority threads, if and only if they're currently idle, but the lower priority threads will prioritize their specific workload over higher priority ones. Priority goes compute > io > async compute.
For example, heavy per-frame compute workload, async compute and IO otherwise sitting idle: compute tasks will be scheduled onto async compute and IO threads whenever idle. Any IO task that is awoken will take precedence over the compute tasks.
In another case, a heavy IO workload will schedule onto idle async compute threads, but will never use a compute thread. This prevents lower priority tasks from starving out higher priority tasks.
The priority scheme chosen assumes well-behaved scheduling that adheres to the following principles:
- Compute tasks are latency sensitive and generally do not hold the thread indefinitely or at the very minimum for time longer than the course of a frame.
- IO tasks are not CPU intensive and will do minimal processing. Generally will yield readily at any incoming or outbound communication, and thus will only generally be under consistent heavy load only in specific circumstances.
- Async compute tasks may run for a very long time, across multiple frames, and will generally not yield at any point during a given task's execution. Only under heavy load when a developer explicitly needs it, and can otherwise be used for IO or compute in the general case.
TODO:
- [x] Add two additional executors to
TaskPool - [x] Set up TaskPool threads to run tasks from all 3 with some prioritization
- [x] Add user-facing APIs for choosing which priority to spawn tasks under.
- [x] Remove the usages newtypes. Fix up dependent code.
- [x] Properly set up individual thread groups and their individual prioritization schemes.
- [x] Update docs.
Changelog
Changed: Newtypes of TaskPool (ComputeTaskPool, AsyncComputeTaskPool, and IoTaskPool) have been replaced with TaskPool::spawn_as with the appropriate TaskGroup. Thread utilization across these segments has been generally been increased via internal task prioritization. For convenience, TaskPool::spawn will always spawn on the compute task group.
Migration Guide
ComputeTaskPool, AsyncComputeTaskPool, and IoTaskPool have been removed. These individual TaskPools have been merged together, and can be accessed by Res<TaskPool>. To spawn a task on a specific segment of the threads, use TaskPool::spawn_as with the appropriate TaskGroup.
Before:
fn system(task_pool: Res<AsyncComputeTaskPool>) {
task_pool.spawn(async {
...
});
}
After:
fn system(task_pool: Res<TaskPool>) {
task_pool.spawn(TaskGroup::AsyncCompute, async {
...
});
}
I had a slightly different idea on how to combine the task pools. I wanted to give tasks spawned on a scope the highest priority; give tasks spawned onto the task pool a lower priority; and then add a new spawn_blocking function that works like it does in tokio where these tasks are spawned onto a different set of threads. It reuses an idle thread if there are any or spawns a new thread when there aren't any.
I had a slightly different idea on how to combine the task pools. I wanted to give tasks spawned on a scope the highest priority; give tasks spawned onto the task pool a lower priority; and then add a new spawn_blocking function that works like it does in tokio where these tasks are spawned onto a different set of threads. It reuses an idle thread if there are any or spawns a new thread when there aren't any.
I think the first two parts are still reconcilable with the current proposed approach; however, the problem with spawn_blocking as a general approach is that if a compute thread is idle, you can easily starve out the compute tasks, which is unacceptable in a game engine. Spinning up and down threads is also an overhead we generally want to avoid too, particularly since it can cause even heavier thrashing on the CPU for the other threads.
however, the problem with spawn_blocking as a general approach is that if a compute thread is idle, you can easily starve out the compute tasks, which is unacceptable in a game engine.
isn't that a problem with this approach too. If a user starts too many blocking tasks the compute task pool won't have any threads to work with either.
edit: thinking on this more I guess. The approach here prevents the user from running more than x blocking tasks at the same time. So the surprise for the user is that when they run too many blocking tasks, they only get x running in parallel. Even if they were expecting them to all run in parallel. In the case I suggest, they run as many as they want, but suddenly their game starts stuttering because they've used all the threads.
isn't that a problem with this approach too. If a user starts too many blocking tasks the compute task pool won't have any threads to work with either.
If and only if they start it as a normal compute task, something that would require spawn_blocking should be scheduled to the async compute segment, where under this approach, it'll be delayed until the thread(s) are available.
I just want to say, I am very happy to see this and I think this is the right direction for Bevy.
Using all threads, with internal prioritizing logic for different kinds of tasks, has always seemed like the optimal way to do this. Honestly I was quite surprised when I first learned that Bevy just reserves threads for different task kinds and lets them sit idle when there are no workloads of their kind.
Further, this seems like it would be laying some important groundwork. It should become easier to add more different task classes with different prioritization or scheduling, should we need to do that later.
One example I could think of: we could add a new compute class for the render sub-app tasks. It would make sense, when "actual pipelining" is enabled, to have the render tasks from the previous frame run with higher priority than the compute tasks from the main app update.
This recent change should fix it, though it also doesn't allow for proper prioritization either. It's running the tasks from higher priority task groups, but sometimes it just sits idle. For this to work, we may need to move the distinction into the executor itself.
Thanks to fixes from @hymm the thread utilization of the remaining threads has been fixed.
This PR should be ready for general review now.
Ran benches. Seeing some small improvements to benchmarks with contrived systems. Mostly noise otherwise.
benchmarks
group main task-pool-final
----- ---- ---------------
add_remove_component/sparse_set 1.00 1522.2±39.86µs ? ?/sec 1.05 1605.1±133.12µs ? ?/sec
add_remove_component/table 1.00 1959.7±124.24µs ? ?/sec 1.01 1988.4±170.52µs ? ?/sec
add_remove_component_big/sparse_set 1.00 1733.5±100.03µs ? ?/sec 1.02 1770.9±120.43µs ? ?/sec
add_remove_component_big/table 1.01 5.0±0.44ms ? ?/sec 1.00 4.9±0.34ms ? ?/sec
added_archetypes/archetype_count/100 1.17 835.7±639.85µs ? ?/sec 1.00 711.8±43.34µs ? ?/sec
added_archetypes/archetype_count/1000 1.00 1800.3±197.01µs ? ?/sec 1.17 2.1±0.29ms ? ?/sec
added_archetypes/archetype_count/10000 1.00 23.4±1.76ms ? ?/sec 1.00 23.3±1.16ms ? ?/sec
added_archetypes/archetype_count/200 1.02 838.7±51.34µs ? ?/sec 1.00 819.0±21.59µs ? ?/sec
added_archetypes/archetype_count/2000 1.00 3.3±0.42ms ? ?/sec 1.21 4.0±0.55ms ? ?/sec
added_archetypes/archetype_count/500 1.05 1267.9±99.01µs ? ?/sec 1.00 1202.1±111.63µs ? ?/sec
added_archetypes/archetype_count/5000 1.00 10.7±0.75ms ? ?/sec 1.06 11.3±0.90ms ? ?/sec
busy_systems/01x_entities_03_systems 1.17 70.5±3.49µs ? ?/sec 1.00 60.1±2.94µs ? ?/sec
busy_systems/01x_entities_06_systems 1.00 108.2±7.34µs ? ?/sec 1.12 120.7±5.19µs ? ?/sec
busy_systems/01x_entities_09_systems 1.05 179.3±8.51µs ? ?/sec 1.00 171.1±6.34µs ? ?/sec
busy_systems/01x_entities_12_systems 1.02 225.3±9.34µs ? ?/sec 1.00 221.4±9.10µs ? ?/sec
busy_systems/01x_entities_15_systems 1.07 290.1±15.32µs ? ?/sec 1.00 272.0±8.82µs ? ?/sec
busy_systems/02x_entities_03_systems 1.09 106.8±5.11µs ? ?/sec 1.00 98.2±5.59µs ? ?/sec
busy_systems/02x_entities_06_systems 1.16 230.0±14.59µs ? ?/sec 1.00 198.3±8.77µs ? ?/sec
busy_systems/02x_entities_09_systems 1.07 307.6±27.78µs ? ?/sec 1.00 288.4±9.42µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 406.1±26.52µs ? ?/sec 1.00 388.3±16.14µs ? ?/sec
busy_systems/02x_entities_15_systems 1.00 506.9±24.09µs ? ?/sec 1.02 515.1±20.71µs ? ?/sec
busy_systems/03x_entities_03_systems 1.00 168.9±11.40µs ? ?/sec 1.03 174.7±11.79µs ? ?/sec
busy_systems/03x_entities_06_systems 1.00 305.8±26.29µs ? ?/sec 1.04 317.6±36.23µs ? ?/sec
busy_systems/03x_entities_09_systems 1.03 456.9±32.25µs ? ?/sec 1.00 443.2±20.30µs ? ?/sec
busy_systems/03x_entities_12_systems 1.00 590.2±40.64µs ? ?/sec 1.03 609.6±29.64µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 733.3±34.13µs ? ?/sec 1.03 756.9±29.65µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 200.7±12.53µs ? ?/sec 1.00 201.1±12.17µs ? ?/sec
busy_systems/04x_entities_06_systems 1.07 413.2±34.68µs ? ?/sec 1.00 387.3±24.68µs ? ?/sec
busy_systems/04x_entities_09_systems 1.03 607.4±37.26µs ? ?/sec 1.00 590.8±28.60µs ? ?/sec
busy_systems/04x_entities_12_systems 1.13 825.8±80.27µs ? ?/sec 1.00 731.3±35.17µs ? ?/sec
busy_systems/04x_entities_15_systems 1.05 986.2±71.05µs ? ?/sec 1.00 941.4±50.50µs ? ?/sec
busy_systems/05x_entities_03_systems 1.20 289.3±19.91µs ? ?/sec 1.00 242.1±22.95µs ? ?/sec
busy_systems/05x_entities_06_systems 1.10 530.4±48.09µs ? ?/sec 1.00 483.5±53.43µs ? ?/sec
busy_systems/05x_entities_09_systems 1.00 765.1±61.78µs ? ?/sec 1.00 767.1±49.80µs ? ?/sec
busy_systems/05x_entities_12_systems 1.07 1008.5±71.43µs ? ?/sec 1.00 938.8±49.08µs ? ?/sec
busy_systems/05x_entities_15_systems 1.00 1265.9±100.72µs ? ?/sec 1.00 1260.2±72.67µs ? ?/sec
contrived/01x_entities_03_systems 1.00 37.0±1.87µs ? ?/sec 1.03 38.0±3.93µs ? ?/sec
contrived/01x_entities_06_systems 1.14 71.9±3.97µs ? ?/sec 1.00 63.0±5.27µs ? ?/sec
contrived/01x_entities_09_systems 1.07 100.2±4.12µs ? ?/sec 1.00 93.7±4.43µs ? ?/sec
contrived/01x_entities_12_systems 1.00 128.2±7.43µs ? ?/sec 1.00 128.0±6.50µs ? ?/sec
contrived/01x_entities_15_systems 1.00 155.2±9.04µs ? ?/sec 1.01 156.9±8.24µs ? ?/sec
contrived/02x_entities_03_systems 1.02 51.8±5.27µs ? ?/sec 1.00 51.0±2.98µs ? ?/sec
contrived/02x_entities_06_systems 1.02 98.9±10.20µs ? ?/sec 1.00 97.0±5.57µs ? ?/sec
contrived/02x_entities_09_systems 1.13 166.8±9.14µs ? ?/sec 1.00 147.3±7.50µs ? ?/sec
contrived/02x_entities_12_systems 1.05 208.6±21.24µs ? ?/sec 1.00 199.0±20.81µs ? ?/sec
contrived/02x_entities_15_systems 1.00 235.6±16.42µs ? ?/sec 1.02 239.5±10.52µs ? ?/sec
contrived/03x_entities_03_systems 1.04 75.0±6.68µs ? ?/sec 1.00 71.9±4.03µs ? ?/sec
contrived/03x_entities_06_systems 1.01 136.7±17.13µs ? ?/sec 1.00 135.1±5.55µs ? ?/sec
contrived/03x_entities_09_systems 1.01 195.3±16.48µs ? ?/sec 1.00 194.1±10.62µs ? ?/sec
contrived/03x_entities_12_systems 1.02 267.0±21.11µs ? ?/sec 1.00 261.4±10.07µs ? ?/sec
contrived/03x_entities_15_systems 1.00 325.4±27.27µs ? ?/sec 1.00 326.1±9.71µs ? ?/sec
contrived/04x_entities_03_systems 1.09 94.4±8.97µs ? ?/sec 1.00 86.6±8.12µs ? ?/sec
contrived/04x_entities_06_systems 1.00 170.9±18.70µs ? ?/sec 1.09 186.8±17.07µs ? ?/sec
contrived/04x_entities_09_systems 1.02 258.0±16.39µs ? ?/sec 1.00 252.1±10.77µs ? ?/sec
contrived/04x_entities_12_systems 1.04 341.0±25.24µs ? ?/sec 1.00 328.8±10.68µs ? ?/sec
contrived/04x_entities_15_systems 1.02 435.6±21.88µs ? ?/sec 1.00 425.7±33.01µs ? ?/sec
contrived/05x_entities_03_systems 1.07 113.0±8.09µs ? ?/sec 1.00 105.6±5.83µs ? ?/sec
contrived/05x_entities_06_systems 1.08 221.8±19.10µs ? ?/sec 1.00 205.1±14.36µs ? ?/sec
contrived/05x_entities_09_systems 1.05 314.0±20.77µs ? ?/sec 1.00 297.8±15.43µs ? ?/sec
contrived/05x_entities_12_systems 1.03 415.6±36.82µs ? ?/sec 1.00 405.3±18.95µs ? ?/sec
contrived/05x_entities_15_systems 1.04 516.7±18.63µs ? ?/sec 1.00 497.9±19.70µs ? ?/sec
empty_commands/0_entities 1.00 7.6±0.72ns ? ?/sec 1.04 7.9±1.18ns ? ?/sec
empty_systems/000_systems 1.00 3.3±0.52µs ? ?/sec 1.02 3.4±0.71µs ? ?/sec
empty_systems/001_systems 1.02 7.0±0.52µs ? ?/sec 1.00 6.9±0.31µs ? ?/sec
empty_systems/002_systems 1.00 7.8±0.48µs ? ?/sec 1.16 9.1±0.22µs ? ?/sec
empty_systems/003_systems 1.00 10.0±0.33µs ? ?/sec 1.07 10.8±0.28µs ? ?/sec
empty_systems/004_systems 1.00 11.5±0.33µs ? ?/sec 1.13 13.0±0.54µs ? ?/sec
empty_systems/005_systems 1.00 13.2±0.43µs ? ?/sec 1.10 14.5±0.42µs ? ?/sec
empty_systems/010_systems 1.00 21.6±0.35µs ? ?/sec 1.11 23.9±0.43µs ? ?/sec
empty_systems/015_systems 1.00 29.5±0.59µs ? ?/sec 1.01 29.9±0.72µs ? ?/sec
empty_systems/020_systems 1.00 37.0±0.85µs ? ?/sec 1.04 38.4±0.78µs ? ?/sec
empty_systems/025_systems 1.11 50.4±1.51µs ? ?/sec 1.00 45.3±0.98µs ? ?/sec
empty_systems/030_systems 1.05 56.1±1.53µs ? ?/sec 1.00 53.7±1.07µs ? ?/sec
empty_systems/035_systems 1.04 63.2±1.78µs ? ?/sec 1.00 60.7±1.20µs ? ?/sec
empty_systems/040_systems 1.07 74.0±3.03µs ? ?/sec 1.00 68.8±1.90µs ? ?/sec
empty_systems/045_systems 1.07 82.3±2.44µs ? ?/sec 1.00 77.0±2.13µs ? ?/sec
empty_systems/050_systems 1.08 90.3±3.40µs ? ?/sec 1.00 83.8±1.97µs ? ?/sec
empty_systems/055_systems 1.06 98.2±4.19µs ? ?/sec 1.00 93.0±2.13µs ? ?/sec
empty_systems/060_systems 1.07 108.6±4.02µs ? ?/sec 1.00 101.7±2.27µs ? ?/sec
empty_systems/065_systems 1.06 117.2±5.12µs ? ?/sec 1.00 110.1±2.92µs ? ?/sec
empty_systems/070_systems 1.09 126.8±5.46µs ? ?/sec 1.00 116.8±2.12µs ? ?/sec
empty_systems/075_systems 1.09 135.5±4.55µs ? ?/sec 1.00 123.8±2.57µs ? ?/sec
empty_systems/080_systems 1.08 145.2±6.00µs ? ?/sec 1.00 134.5±3.19µs ? ?/sec
empty_systems/085_systems 1.07 152.7±6.81µs ? ?/sec 1.00 143.2±3.14µs ? ?/sec
empty_systems/090_systems 1.09 166.4±7.90µs ? ?/sec 1.00 152.1±3.17µs ? ?/sec
empty_systems/095_systems 1.11 175.2±7.79µs ? ?/sec 1.00 158.1±3.45µs ? ?/sec
empty_systems/100_systems 1.12 183.6±8.37µs ? ?/sec 1.00 163.4±3.39µs ? ?/sec
fake_commands/2000_commands 1.00 10.5±0.38µs ? ?/sec 1.03 10.8±0.22µs ? ?/sec
fake_commands/4000_commands 1.00 21.2±0.57µs ? ?/sec 1.03 21.8±1.50µs ? ?/sec
fake_commands/6000_commands 1.00 31.9±0.66µs ? ?/sec 1.02 32.4±2.64µs ? ?/sec
fake_commands/8000_commands 1.14 49.0±4.19µs ? ?/sec 1.00 43.0±0.90µs ? ?/sec
for_each_iter 1.00 229.6±1.61ms ? ?/sec 1.02 233.6±2.48ms ? ?/sec
for_each_par_iter/threads/1 2.38 145.1±18.00ms ? ?/sec 1.00 61.0±0.81ms ? ?/sec
for_each_par_iter/threads/16 1.00 23.6±1.85ms ? ?/sec 1.02 24.0±1.15ms ? ?/sec
for_each_par_iter/threads/2 1.47 89.5±3.95ms ? ?/sec 1.00 60.8±0.98ms ? ?/sec
for_each_par_iter/threads/32 1.00 23.4±1.97ms ? ?/sec 1.02 23.8±0.97ms ? ?/sec
for_each_par_iter/threads/4 1.06 52.3±1.77ms ? ?/sec 1.00 49.3±0.59ms ? ?/sec
for_each_par_iter/threads/8 1.05 31.1±0.73ms ? ?/sec 1.00 29.6±0.73ms ? ?/sec
fragmented_iter/base 1.00 569.2±91.76ns ? ?/sec 1.00 568.2±66.84ns ? ?/sec
fragmented_iter/foreach 1.00 390.1±47.88ns ? ?/sec 1.05 409.3±67.13ns ? ?/sec
get_component/base 1.05 1827.0±239.87µs ? ?/sec 1.00 1740.5±145.88µs ? ?/sec
get_component/system 1.07 1475.2±175.10µs ? ?/sec 1.00 1373.9±55.83µs ? ?/sec
get_or_spawn/batched 1.00 513.0±43.64µs ? ?/sec 1.06 541.6±56.81µs ? ?/sec
get_or_spawn/individual 1.00 1160.6±151.94µs ? ?/sec 1.02 1182.0±105.13µs ? ?/sec
heavy_compute/base 1.00 426.4±1.85µs ? ?/sec 1.32 563.0±173.79µs ? ?/sec
insert_commands/insert 1.00 943.7±133.16µs ? ?/sec 1.08 1022.0±335.22µs ? ?/sec
insert_commands/insert_batch 1.00 497.8±46.99µs ? ?/sec 1.07 531.5±81.43µs ? ?/sec
many_maps_iter 1.00 230.4±2.94ms ? ?/sec 1.01 232.7±2.14ms ? ?/sec
many_maps_par_iter/threads/1 2.32 141.6±16.82ms ? ?/sec 1.00 60.9±0.81ms ? ?/sec
many_maps_par_iter/threads/16 1.00 23.3±2.37ms ? ?/sec 1.04 24.2±1.24ms ? ?/sec
many_maps_par_iter/threads/2 1.47 89.2±5.14ms ? ?/sec 1.00 60.7±0.96ms ? ?/sec
many_maps_par_iter/threads/32 1.01 23.5±1.47ms ? ?/sec 1.00 23.2±0.97ms ? ?/sec
many_maps_par_iter/threads/4 1.04 51.3±1.62ms ? ?/sec 1.00 49.1±0.58ms ? ?/sec
many_maps_par_iter/threads/8 1.04 30.7±0.64ms ? ?/sec 1.00 29.5±1.41ms ? ?/sec
no_archetypes/system_count/0 1.00 2.8±0.22µs ? ?/sec 1.04 2.9±0.26µs ? ?/sec
no_archetypes/system_count/100 1.04 187.7±6.38µs ? ?/sec 1.00 181.0±2.46µs ? ?/sec
no_archetypes/system_count/20 1.10 38.7±0.74µs ? ?/sec 1.00 35.3±0.88µs ? ?/sec
no_archetypes/system_count/40 1.00 72.2±2.51µs ? ?/sec 1.01 73.0±1.45µs ? ?/sec
no_archetypes/system_count/60 1.00 92.0±3.17µs ? ?/sec 1.17 107.7±2.03µs ? ?/sec
no_archetypes/system_count/80 1.05 149.7±5.37µs ? ?/sec 1.00 141.9±1.92µs ? ?/sec
overhead_par_iter/threads/1 1.00 53.2±8.98µs ? ?/sec 1.61 85.8±1.68µs ? ?/sec
overhead_par_iter/threads/16 1.47 158.1±16.37µs ? ?/sec 1.00 107.4±4.67µs ? ?/sec
overhead_par_iter/threads/2 1.00 70.5±10.55µs ? ?/sec 1.29 90.9±2.41µs ? ?/sec
overhead_par_iter/threads/32 1.32 157.7±13.64µs ? ?/sec 1.00 119.5±7.59µs ? ?/sec
overhead_par_iter/threads/4 1.08 109.8±4.54µs ? ?/sec 1.00 102.1±3.28µs ? ?/sec
overhead_par_iter/threads/8 1.27 140.3±3.75µs ? ?/sec 1.00 110.2±3.54µs ? ?/sec
query_get/50000_entities_sparse 1.01 1136.7±102.01µs ? ?/sec 1.00 1129.9±95.07µs ? ?/sec
query_get/50000_entities_table 1.00 693.8±28.64µs ? ?/sec 1.03 711.5±42.56µs ? ?/sec
query_get_component/50000_entities_sparse 1.00 1602.1±98.26µs ? ?/sec 1.04 1662.4±155.87µs ? ?/sec
query_get_component/50000_entities_table 1.00 1544.7±94.03µs ? ?/sec 1.03 1584.9±107.06µs ? ?/sec
run_criteria/no/001_systems 1.00 2.8±0.16µs ? ?/sec 1.01 2.9±0.15µs ? ?/sec
run_criteria/no/006_systems 1.00 2.9±0.21µs ? ?/sec 1.10 3.2±0.25µs ? ?/sec
run_criteria/no/011_systems 1.00 3.3±0.33µs ? ?/sec 1.00 3.3±0.38µs ? ?/sec
run_criteria/no/016_systems 1.00 3.6±0.41µs ? ?/sec 1.04 3.7±0.53µs ? ?/sec
run_criteria/no/021_systems 1.05 3.5±0.26µs ? ?/sec 1.00 3.4±0.33µs ? ?/sec
run_criteria/no/026_systems 1.00 3.5±0.26µs ? ?/sec 1.05 3.6±0.53µs ? ?/sec
run_criteria/no/031_systems 1.21 4.6±1.46µs ? ?/sec 1.00 3.8±0.43µs ? ?/sec
run_criteria/no/036_systems 1.05 4.4±1.40µs ? ?/sec 1.00 4.2±0.91µs ? ?/sec
run_criteria/no/041_systems 1.00 4.3±1.21µs ? ?/sec 1.04 4.5±0.88µs ? ?/sec
run_criteria/no/046_systems 1.01 5.1±1.65µs ? ?/sec 1.00 5.0±0.86µs ? ?/sec
run_criteria/no/051_systems 1.14 6.0±2.20µs ? ?/sec 1.00 5.2±0.54µs ? ?/sec
run_criteria/no/056_systems 1.20 6.7±2.79µs ? ?/sec 1.00 5.6±0.56µs ? ?/sec
run_criteria/no/061_systems 1.38 8.1±3.83µs ? ?/sec 1.00 5.8±0.86µs ? ?/sec
run_criteria/no/066_systems 1.39 9.5±4.33µs ? ?/sec 1.00 6.8±2.05µs ? ?/sec
run_criteria/no/071_systems 1.38 9.4±3.57µs ? ?/sec 1.00 6.8±0.68µs ? ?/sec
run_criteria/no/076_systems 1.68 12.1±3.33µs ? ?/sec 1.00 7.2±0.82µs ? ?/sec
run_criteria/no/081_systems 1.00 7.3±1.83µs ? ?/sec 1.05 7.7±1.03µs ? ?/sec
run_criteria/no/086_systems 1.00 8.0±2.03µs ? ?/sec 1.08 8.6±1.91µs ? ?/sec
run_criteria/no/091_systems 1.15 11.1±3.93µs ? ?/sec 1.00 9.6±0.92µs ? ?/sec
run_criteria/no/096_systems 1.03 11.0±3.56µs ? ?/sec 1.00 10.7±1.31µs ? ?/sec
run_criteria/no/101_systems 1.00 12.3±3.22µs ? ?/sec 1.01 12.4±1.93µs ? ?/sec
run_criteria/no_with_labels/001_systems 1.00 2.8±0.21µs ? ?/sec 1.12 3.2±0.39µs ? ?/sec
run_criteria/no_with_labels/006_systems 1.00 3.0±0.36µs ? ?/sec 1.09 3.2±0.28µs ? ?/sec
run_criteria/no_with_labels/011_systems 1.00 3.2±0.27µs ? ?/sec 1.07 3.4±0.49µs ? ?/sec
run_criteria/no_with_labels/016_systems 1.00 3.4±0.29µs ? ?/sec 1.06 3.6±0.45µs ? ?/sec
run_criteria/no_with_labels/021_systems 1.07 4.0±0.42µs ? ?/sec 1.00 3.8±0.58µs ? ?/sec
run_criteria/no_with_labels/026_systems 1.33 5.2±1.31µs ? ?/sec 1.00 3.9±0.48µs ? ?/sec
run_criteria/no_with_labels/031_systems 1.01 4.0±0.51µs ? ?/sec 1.00 3.9±0.53µs ? ?/sec
run_criteria/no_with_labels/036_systems 1.16 4.7±0.89µs ? ?/sec 1.00 4.1±0.76µs ? ?/sec
run_criteria/no_with_labels/041_systems 1.05 4.7±1.17µs ? ?/sec 1.00 4.5±0.78µs ? ?/sec
run_criteria/no_with_labels/046_systems 1.03 4.8±1.26µs ? ?/sec 1.00 4.7±0.84µs ? ?/sec
run_criteria/no_with_labels/051_systems 1.00 4.8±1.54µs ? ?/sec 1.06 5.1±1.05µs ? ?/sec
run_criteria/no_with_labels/056_systems 1.00 5.1±1.67µs ? ?/sec 1.03 5.2±0.79µs ? ?/sec
run_criteria/no_with_labels/061_systems 1.00 5.3±1.97µs ? ?/sec 1.01 5.4±0.95µs ? ?/sec
run_criteria/no_with_labels/066_systems 1.02 6.5±2.58µs ? ?/sec 1.00 6.3±1.46µs ? ?/sec
run_criteria/no_with_labels/071_systems 1.08 6.7±2.72µs ? ?/sec 1.00 6.2±1.53µs ? ?/sec
run_criteria/no_with_labels/076_systems 1.13 8.0±3.03µs ? ?/sec 1.00 7.0±2.14µs ? ?/sec
run_criteria/no_with_labels/081_systems 1.20 8.7±3.29µs ? ?/sec 1.00 7.2±2.08µs ? ?/sec
run_criteria/no_with_labels/086_systems 1.09 8.8±3.47µs ? ?/sec 1.00 8.0±2.59µs ? ?/sec
run_criteria/no_with_labels/091_systems 1.16 9.3±3.35µs ? ?/sec 1.00 8.0±2.26µs ? ?/sec
run_criteria/no_with_labels/096_systems 1.58 11.3±4.17µs ? ?/sec 1.00 7.2±1.99µs ? ?/sec
run_criteria/no_with_labels/101_systems 1.23 10.4±3.27µs ? ?/sec 1.00 8.4±2.52µs ? ?/sec
run_criteria/yes/001_systems 1.00 6.6±0.56µs ? ?/sec 1.02 6.8±0.39µs ? ?/sec
run_criteria/yes/006_systems 1.00 16.6±0.57µs ? ?/sec 1.01 16.7±0.45µs ? ?/sec
run_criteria/yes/011_systems 1.04 24.0±0.66µs ? ?/sec 1.00 23.0±0.45µs ? ?/sec
run_criteria/yes/016_systems 1.09 32.2±1.49µs ? ?/sec 1.00 29.5±0.55µs ? ?/sec
run_criteria/yes/021_systems 1.07 40.7±2.27µs ? ?/sec 1.00 38.0±0.54µs ? ?/sec
run_criteria/yes/026_systems 1.17 50.8±2.24µs ? ?/sec 1.00 43.3±1.63µs ? ?/sec
run_criteria/yes/031_systems 1.17 59.0±2.92µs ? ?/sec 1.00 50.6±0.90µs ? ?/sec
run_criteria/yes/036_systems 1.15 66.7±3.06µs ? ?/sec 1.00 58.2±0.94µs ? ?/sec
run_criteria/yes/041_systems 1.12 74.9±3.89µs ? ?/sec 1.00 67.0±1.28µs ? ?/sec
run_criteria/yes/046_systems 1.13 82.0±3.32µs ? ?/sec 1.00 72.5±1.27µs ? ?/sec
run_criteria/yes/051_systems 1.14 94.2±4.02µs ? ?/sec 1.00 82.8±1.87µs ? ?/sec
run_criteria/yes/056_systems 1.21 106.1±4.89µs ? ?/sec 1.00 87.5±2.20µs ? ?/sec
run_criteria/yes/061_systems 1.20 114.0±5.26µs ? ?/sec 1.00 94.6±1.61µs ? ?/sec
run_criteria/yes/066_systems 1.18 122.7±5.40µs ? ?/sec 1.00 104.4±2.81µs ? ?/sec
run_criteria/yes/071_systems 1.23 134.0±6.71µs ? ?/sec 1.00 109.3±2.59µs ? ?/sec
run_criteria/yes/076_systems 1.17 140.3±7.02µs ? ?/sec 1.00 119.6±2.60µs ? ?/sec
run_criteria/yes/081_systems 1.19 152.9±6.78µs ? ?/sec 1.00 128.9±2.91µs ? ?/sec
run_criteria/yes/086_systems 1.14 155.4±7.44µs ? ?/sec 1.00 136.9±5.80µs ? ?/sec
run_criteria/yes/091_systems 1.15 162.2±7.64µs ? ?/sec 1.00 141.1±3.55µs ? ?/sec
run_criteria/yes/096_systems 1.18 175.2±6.41µs ? ?/sec 1.00 148.4±2.94µs ? ?/sec
run_criteria/yes/101_systems 1.18 188.4±9.71µs ? ?/sec 1.00 159.9±3.55µs ? ?/sec
run_criteria/yes_using_query/001_systems 1.00 6.8±0.71µs ? ?/sec 1.00 6.8±0.29µs ? ?/sec
run_criteria/yes_using_query/006_systems 1.00 15.6±0.42µs ? ?/sec 1.07 16.7±0.51µs ? ?/sec
run_criteria/yes_using_query/011_systems 1.00 24.3±0.35µs ? ?/sec 1.02 24.8±0.59µs ? ?/sec
run_criteria/yes_using_query/016_systems 1.00 33.0±0.64µs ? ?/sec 1.04 34.2±0.78µs ? ?/sec
run_criteria/yes_using_query/021_systems 1.00 40.7±0.86µs ? ?/sec 1.02 41.5±0.94µs ? ?/sec
run_criteria/yes_using_query/026_systems 1.00 50.4±1.16µs ? ?/sec 1.00 50.1±0.81µs ? ?/sec
run_criteria/yes_using_query/031_systems 1.00 58.1±1.72µs ? ?/sec 1.01 58.7±2.00µs ? ?/sec
run_criteria/yes_using_query/036_systems 1.00 67.8±2.37µs ? ?/sec 1.00 67.6±4.00µs ? ?/sec
run_criteria/yes_using_query/041_systems 1.02 77.2±3.36µs ? ?/sec 1.00 75.7±1.34µs ? ?/sec
run_criteria/yes_using_query/046_systems 1.01 85.0±3.60µs ? ?/sec 1.00 84.2±4.58µs ? ?/sec
run_criteria/yes_using_query/051_systems 1.02 94.9±4.43µs ? ?/sec 1.00 93.3±1.50µs ? ?/sec
run_criteria/yes_using_query/056_systems 1.00 101.5±3.96µs ? ?/sec 1.00 101.3±3.02µs ? ?/sec
run_criteria/yes_using_query/061_systems 1.00 111.1±6.10µs ? ?/sec 1.00 111.1±2.37µs ? ?/sec
run_criteria/yes_using_query/066_systems 1.00 118.9±5.06µs ? ?/sec 1.01 120.4±2.45µs ? ?/sec
run_criteria/yes_using_query/071_systems 1.00 129.2±5.99µs ? ?/sec 1.00 128.6±2.25µs ? ?/sec
run_criteria/yes_using_query/076_systems 1.02 139.5±7.12µs ? ?/sec 1.00 136.8±2.56µs ? ?/sec
run_criteria/yes_using_query/081_systems 1.00 145.0±5.57µs ? ?/sec 1.00 144.8±2.55µs ? ?/sec
run_criteria/yes_using_query/086_systems 1.01 156.4±8.08µs ? ?/sec 1.00 155.5±2.91µs ? ?/sec
run_criteria/yes_using_query/091_systems 1.03 167.3±7.73µs ? ?/sec 1.00 162.3±3.20µs ? ?/sec
run_criteria/yes_using_query/096_systems 1.04 174.1±7.85µs ? ?/sec 1.00 166.8±5.62µs ? ?/sec
run_criteria/yes_using_query/101_systems 1.04 187.5±9.49µs ? ?/sec 1.00 180.9±3.65µs ? ?/sec
run_criteria/yes_using_resource/001_systems 1.01 6.6±0.73µs ? ?/sec 1.00 6.5±0.34µs ? ?/sec
run_criteria/yes_using_resource/006_systems 1.00 15.4±0.35µs ? ?/sec 1.06 16.4±0.39µs ? ?/sec
run_criteria/yes_using_resource/011_systems 1.00 24.1±0.50µs ? ?/sec 1.04 25.0±0.43µs ? ?/sec
run_criteria/yes_using_resource/016_systems 1.00 31.5±0.79µs ? ?/sec 1.08 33.9±0.75µs ? ?/sec
run_criteria/yes_using_resource/021_systems 1.00 40.3±1.09µs ? ?/sec 1.03 41.6±0.91µs ? ?/sec
run_criteria/yes_using_resource/026_systems 1.00 48.7±1.95µs ? ?/sec 1.04 50.5±1.13µs ? ?/sec
run_criteria/yes_using_resource/031_systems 1.00 57.7±1.70µs ? ?/sec 1.05 60.6±3.99µs ? ?/sec
run_criteria/yes_using_resource/036_systems 1.01 66.4±2.59µs ? ?/sec 1.00 65.5±3.69µs ? ?/sec
run_criteria/yes_using_resource/041_systems 1.02 76.8±3.58µs ? ?/sec 1.00 75.7±2.31µs ? ?/sec
run_criteria/yes_using_resource/046_systems 1.03 85.9±3.87µs ? ?/sec 1.00 83.3±1.79µs ? ?/sec
run_criteria/yes_using_resource/051_systems 1.03 97.0±4.89µs ? ?/sec 1.00 94.5±4.02µs ? ?/sec
run_criteria/yes_using_resource/056_systems 1.03 106.4±5.77µs ? ?/sec 1.00 103.3±1.74µs ? ?/sec
run_criteria/yes_using_resource/061_systems 1.00 112.4±4.92µs ? ?/sec 1.00 112.2±2.15µs ? ?/sec
run_criteria/yes_using_resource/066_systems 1.01 123.4±6.10µs ? ?/sec 1.00 122.7±2.69µs ? ?/sec
run_criteria/yes_using_resource/071_systems 1.04 132.4±7.28µs ? ?/sec 1.00 126.7±2.82µs ? ?/sec
run_criteria/yes_using_resource/076_systems 1.02 142.3±8.99µs ? ?/sec 1.00 140.0±3.24µs ? ?/sec
run_criteria/yes_using_resource/081_systems 1.06 155.7±16.49µs ? ?/sec 1.00 146.7±2.38µs ? ?/sec
run_criteria/yes_using_resource/086_systems 1.04 161.0±6.66µs ? ?/sec 1.00 154.9±3.21µs ? ?/sec
run_criteria/yes_using_resource/091_systems 1.03 171.3±7.45µs ? ?/sec 1.00 166.2±2.99µs ? ?/sec
run_criteria/yes_using_resource/096_systems 1.07 183.2±9.14µs ? ?/sec 1.00 170.7±3.10µs ? ?/sec
run_criteria/yes_using_resource/101_systems 1.06 192.0±7.87µs ? ?/sec 1.00 181.5±4.02µs ? ?/sec
run_criteria/yes_with_labels/001_systems 1.12 7.0±0.67µs ? ?/sec 1.00 6.3±0.30µs ? ?/sec
run_criteria/yes_with_labels/006_systems 1.00 15.0±0.38µs ? ?/sec 1.03 15.4±0.36µs ? ?/sec
run_criteria/yes_with_labels/011_systems 1.06 23.9±0.30µs ? ?/sec 1.00 22.5±0.51µs ? ?/sec
run_criteria/yes_with_labels/016_systems 1.04 31.4±1.18µs ? ?/sec 1.00 30.1±0.49µs ? ?/sec
run_criteria/yes_with_labels/021_systems 1.07 39.3±0.87µs ? ?/sec 1.00 36.9±0.86µs ? ?/sec
run_criteria/yes_with_labels/026_systems 1.13 48.9±1.47µs ? ?/sec 1.00 43.3±0.79µs ? ?/sec
run_criteria/yes_with_labels/031_systems 1.13 57.1±2.15µs ? ?/sec 1.00 50.8±1.29µs ? ?/sec
run_criteria/yes_with_labels/036_systems 1.13 65.1±2.53µs ? ?/sec 1.00 57.7±1.03µs ? ?/sec
run_criteria/yes_with_labels/041_systems 1.14 73.2±2.55µs ? ?/sec 1.00 64.4±1.31µs ? ?/sec
run_criteria/yes_with_labels/046_systems 1.16 83.5±2.89µs ? ?/sec 1.00 72.0±1.96µs ? ?/sec
run_criteria/yes_with_labels/051_systems 1.16 92.1±3.45µs ? ?/sec 1.00 79.2±1.58µs ? ?/sec
run_criteria/yes_with_labels/056_systems 1.15 101.9±4.15µs ? ?/sec 1.00 88.3±2.58µs ? ?/sec
run_criteria/yes_with_labels/061_systems 1.14 107.7±3.53µs ? ?/sec 1.00 94.5±2.97µs ? ?/sec
run_criteria/yes_with_labels/066_systems 1.18 119.5±5.34µs ? ?/sec 1.00 101.2±2.83µs ? ?/sec
run_criteria/yes_with_labels/071_systems 1.17 125.1±6.10µs ? ?/sec 1.00 106.5±2.46µs ? ?/sec
run_criteria/yes_with_labels/076_systems 1.18 134.6±4.56µs ? ?/sec 1.00 114.3±2.00µs ? ?/sec
run_criteria/yes_with_labels/081_systems 1.15 143.2±4.85µs ? ?/sec 1.00 124.5±5.13µs ? ?/sec
run_criteria/yes_with_labels/086_systems 1.19 154.8±6.85µs ? ?/sec 1.00 130.6±2.79µs ? ?/sec
run_criteria/yes_with_labels/091_systems 1.19 164.7±6.88µs ? ?/sec 1.00 138.1±3.59µs ? ?/sec
run_criteria/yes_with_labels/096_systems 1.20 175.5±6.57µs ? ?/sec 1.00 146.0±5.09µs ? ?/sec
run_criteria/yes_with_labels/101_systems 1.21 183.2±7.39µs ? ?/sec 1.00 151.4±3.46µs ? ?/sec
schedule/base 1.00 57.0±5.43µs ? ?/sec 1.00 57.2±7.20µs ? ?/sec
simple_insert/base 1.00 750.9±184.67µs ? ?/sec 1.04 783.1±173.44µs ? ?/sec
simple_insert/unbatched 1.00 1703.4±128.95µs ? ?/sec 1.10 1871.8±179.38µs ? ?/sec
simple_iter/base 1.00 17.7±1.62µs ? ?/sec 1.03 18.2±1.11µs ? ?/sec
simple_iter/foreach 1.00 13.2±0.72µs ? ?/sec 1.03 13.7±1.04µs ? ?/sec
simple_iter/sparse 1.39 93.2±12.79µs ? ?/sec 1.00 67.0±5.91µs ? ?/sec
simple_iter/sparse_foreach 1.00 63.2±3.10µs ? ?/sec 1.02 64.2±2.73µs ? ?/sec
simple_iter/system 1.00 17.5±0.63µs ? ?/sec 1.02 17.9±0.72µs ? ?/sec
sized_commands_0_bytes/2000_commands 1.00 7.6±0.13µs ? ?/sec 1.08 8.3±0.29µs ? ?/sec
sized_commands_0_bytes/4000_commands 1.00 15.3±0.42µs ? ?/sec 1.08 16.4±0.21µs ? ?/sec
sized_commands_0_bytes/6000_commands 1.00 22.9±0.62µs ? ?/sec 1.08 24.8±0.30µs ? ?/sec
sized_commands_0_bytes/8000_commands 1.00 31.7±0.95µs ? ?/sec 1.05 33.2±1.24µs ? ?/sec
sized_commands_12_bytes/2000_commands 1.06 10.0±0.30µs ? ?/sec 1.00 9.4±0.24µs ? ?/sec
sized_commands_12_bytes/4000_commands 1.07 20.3±1.99µs ? ?/sec 1.00 18.9±1.32µs ? ?/sec
sized_commands_12_bytes/6000_commands 1.06 29.6±0.67µs ? ?/sec 1.00 27.9±0.69µs ? ?/sec
sized_commands_12_bytes/8000_commands 1.06 39.4±1.03µs ? ?/sec 1.00 37.3±1.48µs ? ?/sec
sized_commands_512_bytes/2000_commands 1.00 161.0±10.03µs ? ?/sec 1.06 170.2±22.18µs ? ?/sec
sized_commands_512_bytes/4000_commands 1.00 339.2±55.10µs ? ?/sec 1.01 341.8±45.00µs ? ?/sec
sized_commands_512_bytes/6000_commands 1.00 516.1±102.00µs ? ?/sec 1.02 524.9±77.74µs ? ?/sec
sized_commands_512_bytes/8000_commands 1.00 686.5±98.16µs ? ?/sec 1.00 687.7±92.92µs ? ?/sec
sparse_fragmented_iter/base 1.00 15.8±0.88ns ? ?/sec 1.02 16.0±0.97ns ? ?/sec
sparse_fragmented_iter/foreach 1.03 15.1±1.87ns ? ?/sec 1.00 14.6±1.03ns ? ?/sec
spawn_commands/2000_entities 1.00 322.4±22.19µs ? ?/sec 1.06 341.5±32.73µs ? ?/sec
spawn_commands/4000_entities 1.00 620.7±24.47µs ? ?/sec 1.04 648.4±44.70µs ? ?/sec
spawn_commands/6000_entities 1.00 904.9±81.96µs ? ?/sec 1.01 918.2±56.19µs ? ?/sec
spawn_commands/8000_entities 1.00 1172.8±71.17µs ? ?/sec 1.05 1235.8±90.34µs ? ?/sec
world_entity/50000_entities 1.00 533.6±8.46µs ? ?/sec 1.01 539.6±7.41µs ? ?/sec
world_get/50000_entities_sparse 1.00 618.5±16.06µs ? ?/sec 1.10 677.8±44.73µs ? ?/sec
world_get/50000_entities_table 1.00 952.9±18.07µs ? ?/sec 1.08 1028.9±21.62µs ? ?/sec
world_query_for_each/50000_entities_sparse 1.00 106.7±5.87µs ? ?/sec 1.04 110.8±12.45µs ? ?/sec
world_query_for_each/50000_entities_table 1.00 31.1±1.85µs ? ?/sec 1.07 33.4±3.96µs ? ?/sec
world_query_get/50000_entities_sparse 1.00 477.2±20.22µs ? ?/sec 1.01 481.2±23.97µs ? ?/sec
world_query_get/50000_entities_table 1.00 359.9±18.21µs ? ?/sec 1.02 367.7±20.83µs ? ?/sec
world_query_iter/50000_entities_sparse 1.00 115.4±7.08µs ? ?/sec 1.04 119.7±10.07µs ? ?/sec
world_query_iter/50000_entities_table 1.00 43.7±1.60µs ? ?/sec 1.00 43.8±0.77µs ? ?/sec
Also ran many_cubes and saw a small improvement. Probably due to the increased thread usage. Yellow is this PR. Red is main.
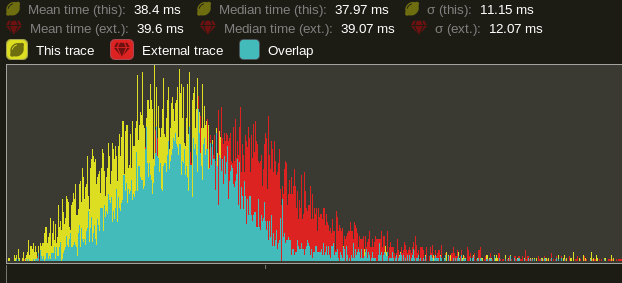
The extra overhead is likely because we're currently using tick over run, which has additional initialization costs that are persisted inside run. We likely cannot address that, at least not within the scope of this PR, and not without ripping open/forking async_executor itself.
As discussed on Discord, the performance overhead is likely coming from the fact that executor.tick and executor.run are using different queuing methods, and using executor.run in a chain results in poor results as it internally does 200 checks in a loop before yielding, adding extra overhead when polled. To fix this, we'd need to embed async_executor's code in bevy_tasks and patch it ourselves, or try to upstream the change (probably unlikely at this point). However ,this is ~800 LoC, which would add quite a bit to an already mid-to-large sized PR, and requires more extensive performance testing to validate. It's probably best to defer this to a followup PR, as the increase in thread utilization still nets us a win here.
As a second followup, we should definitely test integrating in CPU affinity assignments, as mentioned in #4803, for the threads spawned on platforms that support it (Windows / Linux), as this might ensure that we're utilizing all of the hardware
However ,this is ~800 LoC, which would add quite a bit to an already mid-to-large sized PR, and requires more extensive performance testing to validate. It's probably best to defer this to a followup PR, as the increase in thread utilization still nets us a win here.
I think if we can prove that we can regain performance for per-system overhead, I'd be more cool with merging this as-is. Otherwise I'd be a bit worried about backing ourselves into a corner. The wins here definitely exist for simple apps, but for apps with many systems im worried this would be a regression.
How hard would it be to locally "hack in" the changes you have in mind with a forked async_executor crate (ex: maybe reducing the number of checks)? I agree that we shouldn't throw those into this PR, but it would be good to know if we're on the right track.
@james7132 I was poking at this PR and I noticed that main seemed to be distributing the tasks better now. I think it might have been the extra task pool in the render subapp that might have been interfering. I tried reverting the change to the scope executor on this PR and it seemed to be better too. Could you try reverting the change and merging in the current main and see if it's better for you too?
If it is better, I think we should move the change for the scope executor out of this PR and potentially into it's own. I think it's still a valuable change as it reduces cpu usage, but should be considered on it's own.
The thread distribution definitely looks to be fixed. This does make it much more pressing that we make these pools global if it's this simple to disrupt the task distribution. Here are my median stage timings for 3d_scene with this change.
| main | pr | |
|---|---|---|
| First | 637.25us | 637.16us |
| LoadAssets | 288.87us | 282.71us |
| PreUpdate | 149.25us | 147.9us |
| Update | 55.2.us | 61.5us |
| PostUpdate | 419.us | 437.us |
| AssetEvents | 248.71us | 246.18us |
| Last | 36.09us | 36.65us |
| Extract | 498.76us | 488.01.us |
| Prepare | 337.93us | 332.58us |
| Queue | 207.61us | 206.12us |
| Sort | 114.99us | 117.5us |
| Render | 3.4ms | 3.39ms |
| Cleanup | 60.68us | 60.42us |
| full frame | 6.72ms | 6.73ms |
What isn't shown in these immediate numbers is a shift in distribution. For example, while it looks like Update regressed here, it does seem like the PR is causing the stage to be more well behaved in terms of runtime: the timings are no longer heavily bimodal (yellow is main, red is PR).
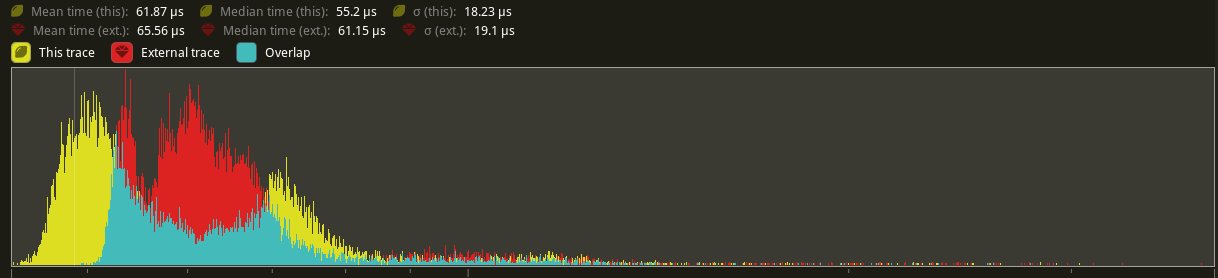
Overall it does seem like reverting the change to the scope does seem to fix a lot of the overhead mentioned above, though 3d_scene definitely does not push my computer hard enough to use all of the threads in the TaskPool. @cart can you check if this fixes the additional overhead?
One thing I did realize is that if we're just trying to understand differences in the executors, we should be allocating all the threads to compute when testing main. i.e.
.insert_resource(DefaultTaskPoolOptions {
max_total_threads: 12,
io: TaskPoolThreadAssignmentPolicy {
min_threads: 0,
max_threads: 0,
percent: 0.0,
},
async_compute: TaskPoolThreadAssignmentPolicy {
min_threads: 0,
max_threads: 0,
percent: 0.0,
},
..default()
})
}
My numbers with this change on 3d_scene:
| main | pr | |
|---|---|---|
| First | 991.82us | 988.69us |
| LoadAssets | 471.41us | 468.11us |
| PreUpdate | 247.79us | 242.27us |
| Update | 106.69us | 104.89us |
| PostUpdate | 741.28us | 722.67us |
| AssetEvents | 445.03us | 441.86us |
| Last | 44.68us | 44.15us |
| Extract | 878us | 919.98us |
| Prepare | 577.4us | 556.43us |
| Queue | 363.28us | 356.1us |
| Sort | 206.28us | 217.78us |
| Render | 913.87us | 894.09us |
| Cleanup | 82.77us | 82.14us |
| full frame | 6.72ms | 6.63ms |
If this is the case, is this overhead just the result of higher contention due to increased thread count inside the executor itself? If that's the case, I don't think there's much we can do there. At that point it gets into the realm of lock-free or wait-free communication without atomics, which is extremely hard to get right and even harder to make generally performant.
I definitely think that contention is part of the story, but there's a lot of moving parts and it's hard to quantify exactly how much of the story it is. We also have switching from run to tick in the thread executors and extra complexity for the executor in the i/o and async compute threads. Also the OS giving and taking away time to our threads causing context switching is part of the story too.
We see some contention in prepare_systems. Below is the histogram comparing main (red) with this pr (yellow) when it was still using tick. My guess here is that using run in the executor causes more contention on the global task pool than tick does, so calling spawn is slightly slower.
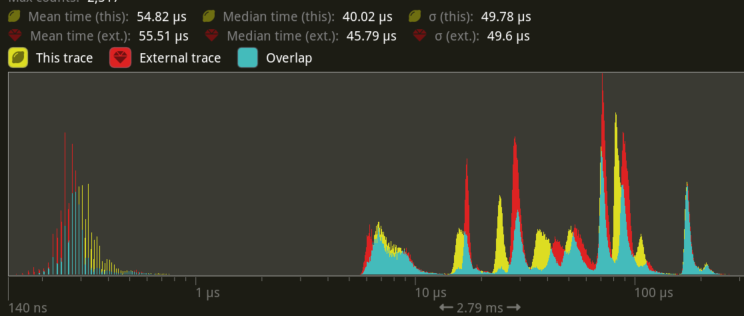
I also made this table, but haven't figured out anything too meaningful from it yet. It uses the older version of this PR that uses tick instead of try_tick in the scope executor. I allocated all threads to compute in both branches on this table.

It does make it clear there is some overhead on the tick design that is not related to the number of threads. The lower system count stages are slower by a value that doesn't vary with the number of threads.
I think my next step is to try and add a bunch of spans in bevy_tasks and see if I can see things taking longer on contention issues.
staring at this just now, I did realize that the 5us diff on the cleanup is probably due to the increased chance of running the one system it has on the main thread vs some other thread.
@hymm @cart I've successfully forked async_executor and augmented it to internally keep track of different priority task queues This likely has even better utilization (and potentially lower overhead) as it moves the prioritization into Future::poll instead of relying of future::or. It also utilizes Executor::run's capacity to work-steal from the local queues from other threads.
One potential downside is that this workstealing can cause tasks to get "trapped" in lower priority threads, but due to the way that work stealing is done (capping at twice the current length of any queue), this total time spent "trapped" is strictly bounded.
Noticed we could strip out all of the RwLocks in the implementation if we provided the executor full information about the thread distribution at initialization: something we can easily do. The core loop should be (mostly) lock free now beyond the sleepers.
made this link to see the changes on executor.rs https://github.com/james7132/bevy/compare/b5fc0d2..93134c8#diff-53706c54663db4196f68585fe74cdcb56266f542731b56dfc9610035aea5502fR3. I'll try to keep the commit hash up to date as other changes are made.
Another thought I'll try out tonight: removing the locks on the local queues makes directly assigning to them "free". We can afford to skip the global queue entirely when scheduling tasks and directly write to the local queues by randomly selecting a start and then scanning for an available local queue. This could reduce the spawning contention by removing the single queue for scheduling and uses the bounded queues which have better cache locality.
Added a number of optimizations:
- Removed the local queue Arcs, and replaced them with a lifetimed borrow. Should avoid pointer chasing while workstealing and spawning tasks.
- Split Sleepers into priority groups to ensure that a thread that can consume a newly scheduled task is awoken instead of some random one that may not be able to run it.
- Embedded the fastrand RNG into the Runner to avoid a thread local lookup. Saves the initialization and atomic check there.
- Attempt to directly enqueue a task into a local queue before falling back to the global queue.
- Changed the assert while workstealing to a debug_assert to avoid the overhead when workstealing.
For additional consideration, if we make the TaskPools global, Drop will never be called. We can then remove the active slab from the state entirely, which should remove locking entirely from spawning tasks.
Taking a look now. Excited to see what you've been cooking up :)
Added a number of optimizations:
How certain are you that each of these changes are wins (or more importantly, not losses)? Have you been benchmarking as you go?
Taking a look now. Excited to see what you've been cooking up :)
Added a number of optimizations:
How certain are you that each of these changes are wins (or more importantly, not losses)? Have you been benchmarking as you go?
Pretty much all of these explicitly do less work. The only exceptions are probably the splitting of the sleepers and the direct enqueing. I'll test that soon.
Finished a first pass. The changes generally make sense to me / look pretty good. I'll give it one more pass soon. Very curious to see how this performs!
How do you want to handle this relative to #2250 in terms of merge order? Should we merge that first, incorporate the changes here and close out #2250, or close #2250 merge this PR and follow up with "globalization"?
IMO we should merge #2250 first. This particular change is pretty heavily involved, and while the merge conflicts are going to be bad in either direction, going #2250 first then this one is probably better given that the conflicts are mostly "external" to bevy_tasks.
I think these sound like great improvements and welcome them.
At the same time, I still feel like we’re limiting performance artificially based on an assumption of thread contention and operating systems being incapable of handling thread scheduling in sensible ways.
We are by default limiting io and async compute to 25% each of the logical threads and compute to the remaining threads, and in this PR in addition only allowing compute to schedule on the other threads, and io to schedule on async compute thus limiting it to only ever run on 50% of logical threads max, and async compute only ever being able to run on 25% logical threads max.
In my mind, all workloads should be able to be scheduled across all logical CPU threads and if some work is higher priority than others then we could try to use thread priorities to support operating system schedulers to do their job. Then all work types could expand to use all available resources if they are not used for something higher priority.
I think we should at least try this approach and try to break OS CPU schedulers before imposing artificial limits or assuming the infrastructure offered by operating systems does not meet our needs. Otherwise I feel we’re leaving performance on the table or adding complexity into bevy by implementing scheduling strategies that kernels already implement better.
What do you think?