amazon-kinesis-client
 amazon-kinesis-client copied to clipboard
amazon-kinesis-client copied to clipboard
Kinesis Shard IteratorAge weirdness and lingering frozen shard!
We have been using the KCL for the 9 months or more in our production and staging near-real time pipeline. We use a Ruby, Java, and Python KCL-based clients, so our Kinesis data pipeline is polyglot. In fact, we also use Node, but that is limited to our Kinesis-Lambda deployments and does not directly use the KCL.
Our Java, Ruby, and Python message processors all use the KCL to read from Kinesis. While our Java and Ruby deployments seems healthy, our Python has experience various issues. I will describe one issue below.
Firstly, here are the versions of some of the libs we use :
/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/amazon-kinesis-client-1.7.2.jar
/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-kinesis-1.11.14.jar
A larger list of JARs can be seen in the Multi-lang Daemon Java command line below :
deploy 5912 1.5 0.8 14144724 272320 ? Sl 00:09 1:06 /usr/bin/java -cp /usr/local/agari/ep-pipeline/config:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/jackson-annotations-2.6.0.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-kms-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/jackson-databind-2.6.6.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-dynamodb-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-core-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-s3-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/httpcore-4.4.4.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/joda-time-2.8.1.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/guava-18.0.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/protobuf-java-2.6.1.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-cloudwatch-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/commons-logging-1.1.3.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/commons-lang-2.6.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/aws-java-sdk-kinesis-1.11.14.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/jackson-dataformat-cbor-2.6.6.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/jackson-core-2.6.6.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/httpclient-4.5.2.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/amazon-kinesis-client-1.7.2.jar:/usr/local/lib/python2.7/dist-packages/amazon_kclpy/jars/commons-codec-1.9.jar:/ com.amazonaws.services.kinesis.multilang.MultiLangDaemon nrt_v2_scorer.properties
We have seen Kinesis stuck shards in the past. We worked around it by restarting KCL python clients every 2 hours. We are currently observing strange behavior with one of our shards.
As shown below, one of our shards keeps displaying a value of 24 hours (i.e. 83M millis) for the Max MillisBehindLatest metric in CloudWatch (e.g a kinesis shard-level metric). Why is the value not 7d, which is the value of the shard retention? Why is it 1d?

I suspect this Shard is not getting any data published to it because there are no KPL metrics for shard 165 - this is shown below:

Also, we noticed we have 33 active shards. We expect to have 32? Why is this shard sticking around and how do we clean it up to get to 32?
In the DynamoDB lease table, I see that this shard's leaseValue is still TRIM_HORIZON (7d). FYI, I have seen the lease get transferred to at least one new lease owner while I was debugging this issue.

Here is some metadata info on the shard:
sid-as-mbp:.aws siddharth$ aws kinesis describe-stream --stream-name agari-prod-ep-counter-output --limit 1 --exclusive-start-shard-id shardId-000000000164
{
"StreamDescription": {
"HasMoreShards": true,
"RetentionPeriodHours": 168,
"StreamName": "agari-prod-ep-counter-output",
"Shards": [
{
"ShardId": "shardId-000000000165",
"HashKeyRange": {
"EndingHashKey": "340282366920938463463374607431768211455",
"StartingHashKey": "340282366920938463463374607431768211454"
},
"ParentShardId": "shardId-000000000123",
"SequenceNumberRange": {
"StartingSequenceNumber": "49571828863472210120280672671408753529991900820959922770"
}
}
],
"StreamARN": "arn:aws:kinesis:us-west-2:xxxxxxxx:stream/agari-prod-ep-counter-output",
"EnhancedMonitoring": [
{
"ShardLevelMetrics": [
"IncomingBytes",
"OutgoingRecords",
"IteratorAgeMilliseconds",
"IncomingRecords",
"ReadProvisionedThroughputExceeded",
"WriteProvisionedThroughputExceeded",
"OutgoingBytes"
]
}
],
"StreamCreationTimestamp": 1481656142.0,
"StreamStatus": "ACTIVE"
}
}
So, I have various questions here:
- If this is an ACTIVE shard, then why is nothing publishing to it?
- Also, if TRIM_HORIZON is 7d, why is this reporting a 1d max MillisBehindLatest?
- We expect to have 32 shards, not 33, so why is this sticking around? How do we fix it and what is the fix?
- Can we request that CW metrics for KCL do not publish MillisBehindLatest until a shard has processed at least 1 record? It seems like a value of TRIM_HORIZON is bogus and unnecessarily triggers alarms
There is a bug that we're currently fixing which can make GetRecords.IteratorAgeMilliseconds appear to spike to 1 day when first reading from a shard with TRIM_HORIZON, or LATEST. This would also likely cause the MillisBehindLatest from the KCL to also spike.
The unusual shard you have was a shard with a size of 1, which made the chance of a record hitting unlikely.
I have 2 shard Streams monitored by Supervisor with Shard id's "shardId-000000000000" and "shardId-000000000001" only log of ShardId-000000000001 is giving output. Another one is not even logging anything into the log file.
@pfifer has this been fixed? I am currently experiencing the issue where GetRecords.IteratorAgeMilliseconds goes instantly from zero to 24 hours on my shards intermittently. we are using client version 1.6.1
+1. We are dealing with the same issue. Spikes in kinesis IteratorAgeMilliseconds from 0 to ~84M ms (roughly 24hours) back to 0 in a span of 10 minutes. The behavior is repetitive. We are using firehose as the consumer here
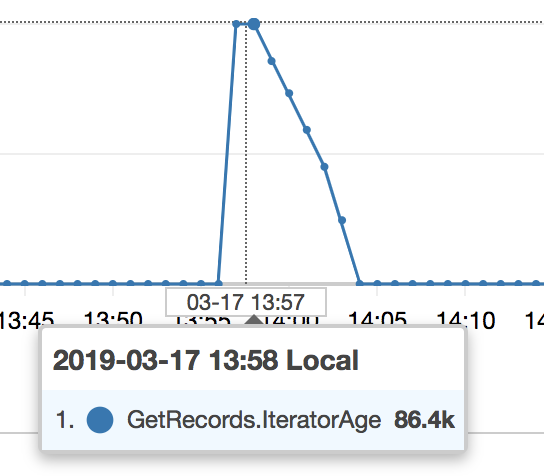
+1 Sadly we are experiencing the exact same behaviour as @pgilad and @rupesh92 . Random ~84M ms spikes on our kinesis streams iterator age.
How often do you checkpoint? This can occur if the lease is lost, and the checkpoint is more than a day old.
Well, in our case we are using Kinesis Analytics, and Lambda as consumers, so we don't really control the checkpointing ourself.
@smilykoch I would recommend opening a support case or opening a topic on the AWS Discussion Forums.
@pfifer Can you please confirm if this is fixed? We see the same issue and we are using KCL 2.2.11.
Same problem here (24h iterator age within a single hour), and we are not using KCL. Is this not a general KDS issue?
5 years it's been since this issue was opened.
Similar issue here. Our consumers all report iterator age <30K ms. Our stream has 4 shards which are all processing data, but the stream age spikes up to 300M at times. The issue came and disappeared seemingly without reason.
