YOLOv4-pytorch
 YOLOv4-pytorch copied to clipboard
YOLOv4-pytorch copied to clipboard
使用mobilenetv3-Pytorch训练和只使用voc2007,最后再检查mAp,发现mAp只有0.178%
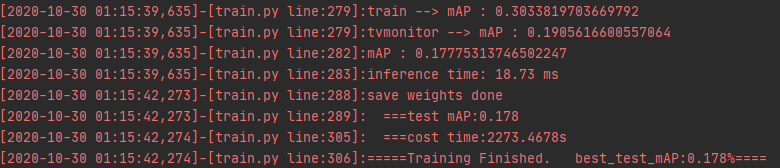 使用mobilenetv3-Pytorch训练和只使用voc2007数据集,中途不检查mAp,训练了120次后,最后检查mAp,发现mAp只有0.178%是哪个步骤出错了吗?
使用mobilenetv3-Pytorch训练和只使用voc2007数据集,中途不检查mAp,训练了120次后,最后检查mAp,发现mAp只有0.178%是哪个步骤出错了吗?
[2020-10-30 00:40:02,215]-[train.py line:212]: === Epoch:[119/120],step:[310/312],img_size:[416],total_loss:20.4310|loss_ciou:4.3372|loss_conf:7.3171|loss_cls:8.7767|lr:0.0001 这是最后一个epoch的loss值
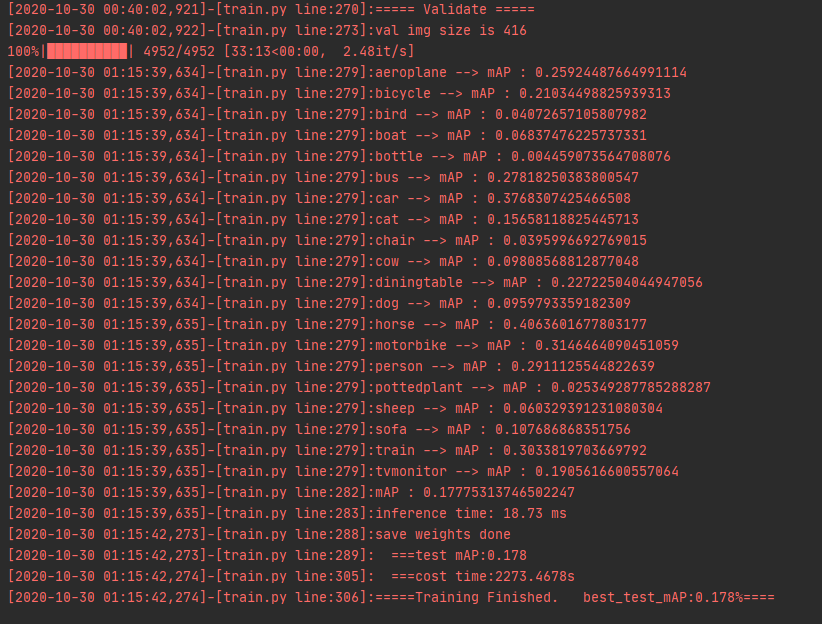 可以看到所有的mAp都是偏低
可以看到所有的mAp都是偏低
我也感觉训练有点问题,貌似loss难以降低. 可以试一下这个: https://github.com/Okery/YOLOv5-PyTorch
请问你的训练集和验证集是怎么划分的
请问你的训练集和验证集是怎么划分的
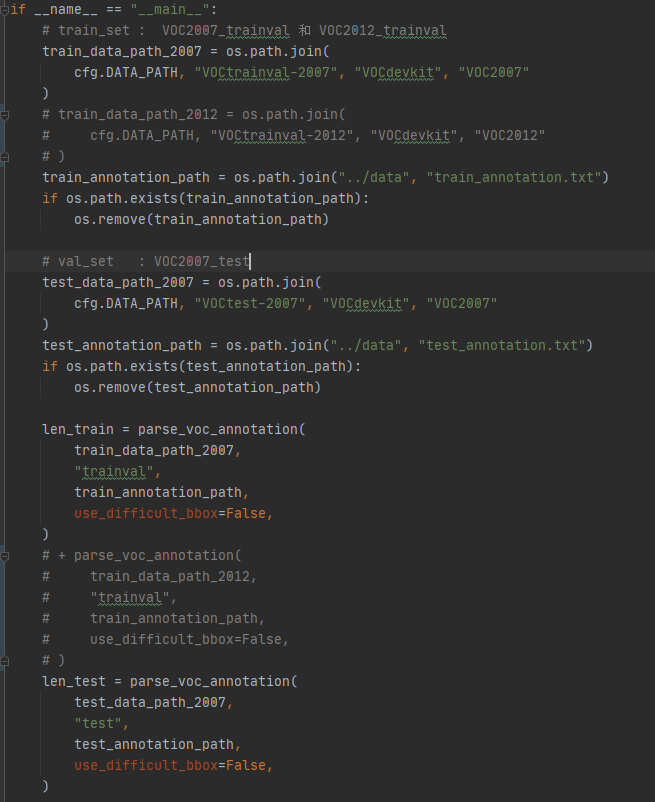 划分是使用你的,我直接注释掉VOC2012的部分
划分是使用你的,我直接注释掉VOC2012的部分
这个loss正常吗:
[2020-10-30 07:43:01,600]-[train2.py line:157]:Epoch:[13/200]
[2020-10-30 07:43:03,312]-[train2.py line:224]:Epoch:[ 13/200], step:[ 0/3344], img_size:[512], total_loss:9.8996| loss_ciou:4.6078| loss_conf:2.1304| loss_cls:3.1615| lr:0.0005
[2020-10-30 07:57:32,060]-[train2.py line:224]:Epoch:[ 13/200], step:[500/3344], img_size:[512], total_loss:8.3806| loss_ciou:3.8154| loss_conf:2.3640| loss_cls:2.2011| lr:0.0006
[2020-10-30 08:11:56,913]-[train2.py line:224]:Epoch:[ 13/200], step:[1000/3344], img_size:[512], total_loss:8.3307| loss_ciou:3.8113| loss_conf:2.3452| loss_cls:2.1741| lr:0.0007
[2020-10-30 08:26:17,785]-[train2.py line:224]:Epoch:[ 13/200], step:[1500/3344], img_size:[512], total_loss:8.3637| loss_ciou:3.8127| loss_conf:2.3485| loss_cls:2.2025| lr:0.0008
[2020-10-30 08:40:33,755]-[train2.py line:224]:Epoch:[ 13/200], step:[2000/3344], img_size:[512], total_loss:8.3697| loss_ciou:3.8181| loss_conf:2.3529| loss_cls:2.1987| lr:0.0008
[2020-10-30 08:54:58,081]-[train2.py line:224]:Epoch:[ 13/200], step:[2500/3344], img_size:[512], total_loss:8.3974| loss_ciou:3.8283| loss_conf:2.3657| loss_cls:2.2034| lr:0.0009
[2020-10-30 09:09:19,850]-[train2.py line:224]:Epoch:[ 13/200], step:[3000/3344], img_size:[512], total_loss:8.4339| loss_ciou:3.8393| loss_conf:2.3793| loss_cls:2.2153| lr:0.0010
[2020-10-30 09:19:17,599]-[train2.py line:311]: ===cost time:5776.0013s
[2020-10-30 09:19:17,601]-[train2.py line:157]:Epoch:[14/200]
[2020-10-30 09:19:19,478]-[train2.py line:224]:Epoch:[ 14/200], step:[ 0/3344], img_size:[512], total_loss:8.8854| loss_ciou:3.9804| loss_conf:1.9609| loss_cls:2.9440| lr:0.0006
[2020-10-30 09:34:02,894]-[train2.py line:224]:Epoch:[ 14/200], step:[500/3344], img_size:[512], total_loss:8.3053| loss_ciou:3.7755| loss_conf:2.3334| loss_cls:2.1964| lr:0.0007
[2020-10-30 09:48:52,440]-[train2.py line:224]:Epoch:[ 14/200], step:[1000/3344], img_size:[512], total_loss:8.2389| loss_ciou:3.7612| loss_conf:2.3259| loss_cls:2.1518| lr:0.0007
[2020-10-30 10:03:54,301]-[train2.py line:224]:Epoch:[ 14/200], step:[1500/3344], img_size:[512], total_loss:8.2227| loss_ciou:3.7715| loss_conf:2.3070| loss_cls:2.1442| lr:0.0008
^O[2020-10-30 10:18:40,982]-[train2.py line:224]:Epoch:[ 14/200], step:[2000/3344], img_size:[512], total_loss:8.2348| loss_ciou:3.7832| loss_conf:2.3104| loss_cls:2.1412| lr:0.0009
[2020-10-30 10:33:27,866]-[train2.py line:224]:Epoch:[ 14/200], step:[2500/3344], img_size:[512], total_loss:8.2688| loss_ciou:3.7978| loss_conf:2.3160| loss_cls:2.1550| lr:0.0010
[2020-10-30 10:48:21,903]-[train2.py line:224]:Epoch:[ 14/200], step:[3000/3344], img_size:[512], total_loss:8.3111| loss_ciou:3.8166| loss_conf:2.3402| loss_cls:2.1543| lr:0.0010
[2020-10-30 10:58:37,756]-[train2.py line:311]: ===cost time:5960.1558s
[2020-10-30 10:58:37,758]-[train2.py line:157]:Epoch:[15/200]
[2020-10-30 10:58:39,682]-[train2.py line:224]:Epoch:[ 15/200], step:[ 0/3344], img_size:[512], total_loss:6.5087| loss_ciou:3.2144| loss_conf:1.8193| loss_cls:1.4749| lr:0.0006
[2020-10-30 11:13:49,444]-[train2.py line:224]:Epoch:[ 15/200], step:[500/3344], img_size:[512], total_loss:8.1104| loss_ciou:3.7311| loss_conf:2.2966| loss_cls:2.0827| lr:0.0007
[2020-10-30 11:28:56,572]-[train2.py line:224]:Epoch:[ 15/200], step:[1000/3344], img_size:[512], total_loss:8.0970| loss_ciou:3.7350| loss_conf:2.2934| loss_cls:2.0685| lr:0.0008
[2020-10-30 11:44:08,594]-[train2.py line:224]:Epoch:[ 15/200], step:[1500/3344], img_size:[512], total_loss:8.1330| loss_ciou:3.7526| loss_conf:2.2928| loss_cls:2.0876| lr:0.0008
[2020-10-30 11:59:19,673]-[train2.py line:224]:Epoch:[ 15/200], step:[2000/3344], img_size:[512], total_loss:8.1400| loss_ciou:3.7539| loss_conf:2.3002| loss_cls:2.0858| lr:0.0009
[2020-10-30 12:15:06,364]-[train2.py line:224]:Epoch:[ 15/200], step:[2500/3344], img_size:[512], total_loss:8.1493| loss_ciou:3.7642| loss_conf:2.2987| loss_cls:2.0864| lr:0.0010
[2020-10-30 12:30:46,938]-[train2.py line:224]:Epoch:[ 15/200], step:[3000/3344], img_size:[512], total_loss:8.1422| loss_ciou:3.7637| loss_conf:2.2921| loss_cls:2.0864| lr:0.0010
[2020-10-30 12:42:34,129]-[train2.py line:266]:save weights at epoch: 15
[2020-10-30 12:42:34,137]-[train2.py line:311]: ===cost time:6236.3807s
[2020-10-30 12:42:34,141]-[train2.py line:157]:Epoch:[16/200]
[2020-10-30 12:42:36,340]-[train2.py line:224]:Epoch:[ 16/200], step:[ 0/3344], img_size:[512], total_loss:5.5250| loss_ciou:2.6019| loss_conf:2.0322| loss_cls:0.8908| lr:0.0007
[2020-10-30 12:58:23,771]-[train2.py line:224]:Epoch:[ 16/200], step:[500/3344], img_size:[512], total_loss:7.9447| loss_ciou:3.7216| loss_conf:2.1789| loss_cls:2.0442| lr:0.0007
[2020-10-30 13:13:45,817]-[train2.py line:224]:Epoch:[ 16/200], step:[1000/3344], img_size:[512], total_loss:7.9117| loss_ciou:3.7107| loss_conf:2.1891| loss_cls:2.0119| lr:0.0008
[2020-10-30 13:30:33,045]-[train2.py line:224]:Epoch:[ 16/200], step:[1500/3344], img_size:[512], total_loss:7.9548| loss_ciou:3.7103| loss_conf:2.2103| loss_cls:2.0342| lr:0.0009
[2020-10-30 13:46:31,986]-[train2.py line:224]:Epoch:[ 16/200], step:[2000/3344], img_size:[512], total_loss:7.9530| loss_ciou:3.7097| loss_conf:2.2121| loss_cls:2.0313| lr:0.0010
[2020-10-30 14:02:13,910]-[train2.py line:224]:Epoch:[ 16/200], step:[2500/3344], img_size:[512], total_loss:7.9853| loss_ciou:3.7145| loss_conf:2.2225| loss_cls:2.0484| lr:0.0010

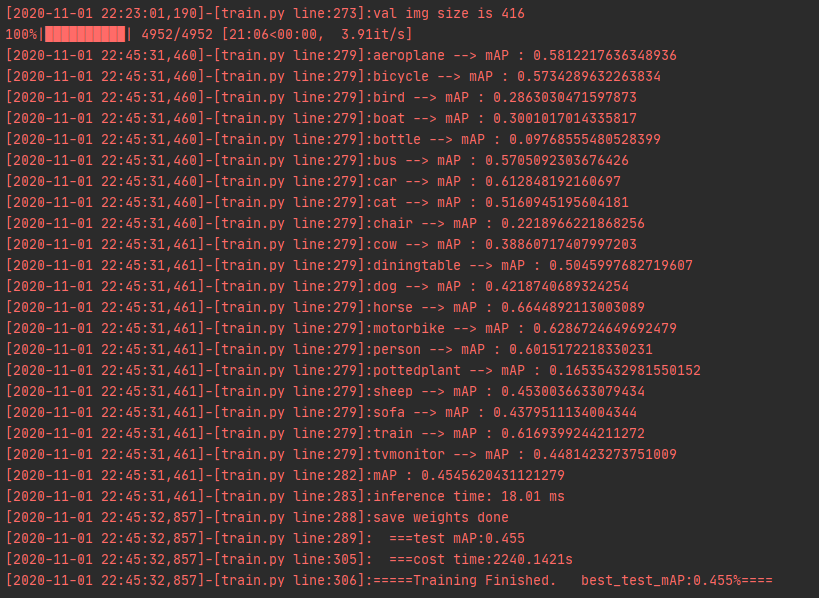 这次使用了voc2012+voc2007的训练集,用yolov4-mobilenet训练了200次,结果依然是非常差,没改任何训练代码。究竟问题出在哪?
这次使用了voc2012+voc2007的训练集,用yolov4-mobilenet训练了200次,结果依然是非常差,没改任何训练代码。究竟问题出在哪?
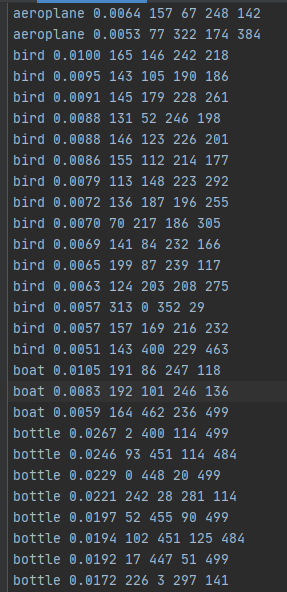 val的时候,物体置信度都非常低,但是都识别都大于0.005的置信度,iou计算也是起作用,但是识别出来的数量太多了,这就可能导致mAp非常低的原因。我训练了200次VOC2012+VOC2007,batch为8,loss到达了12左右,究竟置信度和loss值到达多少才正常。
val的时候,物体置信度都非常低,但是都识别都大于0.005的置信度,iou计算也是起作用,但是识别出来的数量太多了,这就可能导致mAp非常低的原因。我训练了200次VOC2012+VOC2007,batch为8,loss到达了12左右,究竟置信度和loss值到达多少才正常。
请问您eval的时候fps能达到多少呀
@zhanghongsir eval_voc很慢,是因为他在这个时候没有使用gpu计算,你想fps快,需要改进yolo框、backbone网络 fpn层
@zhanghongsir eval_voc很慢,是因为他在这个时候没有使用gpu计算,你想fps快,需要改进yolo框、backbone网络 fpn层
好的,谢谢你
@cangwang [2020-11-04 14:57:50,803]-[train.py line:223]: === Epoch:[ 49/50],step:[4100/4137],img_size:[416],total_loss:11.5218|loss_ciou:3.0263|loss_conf:4.0571|loss_cls:4.4384|lr:0.0001 [2020-11-04 14:57:54,256]-[train.py line:223]: === Epoch:[ 49/50],step:[4110/4137],img_size:[416],total_loss:11.5248|loss_ciou:3.0265|loss_conf:4.0576|loss_cls:4.4407|lr:0.0001 [2020-11-04 14:57:57,691]-[train.py line:223]: === Epoch:[ 49/50],step:[4120/4137],img_size:[416],total_loss:11.5239|loss_ciou:3.0266|loss_conf:4.0570|loss_cls:4.4403|lr:0.0001 [2020-11-04 14:58:01,152]-[train.py line:223]: === Epoch:[ 49/50],step:[4130/4137],img_size:[416],total_loss:11.5168|loss_ciou:3.0245|loss_conf:4.0537|loss_cls:4.4386|lr:0.0001 total_loss在第29个epoch就下降的很慢了,那时候total_loss有14.0左右
@Imagery007 问题来了,我和你的loss查不多,但是我map只有0.47%。想问一下你那边如果用yolo4-mobilenetv3去训练会出现一样的问题吗?
@Imagery007 我看到有问题说,他这个框架的yolo4大概要训练250~320个epoch才能mAp才到最高,方便加个微信或者QQ讨论一下?我QQ284699931
 loss训练到10后,很难再训练下去,lr是1e-5,mAp值是0.473%,blog主是否能提示怎么优化训练?
loss训练到10后,很难再训练下去,lr是1e-5,mAp值是0.473%,blog主是否能提示怎么优化训练?
我没有用mobilenet的backbone而是大模型在预训练的基础上训练的,数据集2007+2012,目前大概20个epoch左右,mAP在62.4%左右,训练的loss在13左右,现在开始loss下降的速度比较缓慢,整体情况和@Imagery007 比较类似