spark
 spark copied to clipboard
spark copied to clipboard
[SPARK-38506][SQL] Push partial aggregation through join
What changes were proposed in this pull request?
-
Add a new optimizer rule(PushPartialAggregationThroughJoin) to push the partial aggregation through join. It supports the following cases:
- Push down partial sum, count, avg, min, max, first and last through inner join.
- Partial deduplicate the children of join if the aggregation itself is group only.
-
Add a new optimizer rule(DeduplicateRightSideOfLeftSemiAntiJoin) to partial deduplicate the right side of left semi/anti join.
-
Make partial aggregation adaptive to skip do partial aggregation if this step does not reduce the number of rows too much.
For example:
CREATE TABLE t1(a int, b int, c int) using parquet;
CREATE TABLE t2(x int, y int, z int) using parquet;
EXPLAIN EXTENDED SELECT b, SUM(c) FROM t1 INNER JOIN t2 ON t1.a = t2.x GROUP BY b;
== Optimized Logical Plan ==
Aggregate [b#1], [b#1, sum((_pushed_sum_c#12L * cnt#15L)) AS sum(c)#7L]
+- Project [_pushed_sum_c#12L, b#1, cnt#15L]
+- Join Inner, (a#0 = x#3)
:- PartialAggregate [a#0, b#1], [sum(c#2) AS _pushed_sum_c#12L, a#0, b#1]
: +- Project [b#1, c#2, a#0]
: +- Filter isnotnull(a#0)
: +- Relation default.t1[a#0,b#1,c#2] parquet
+- PartialAggregate [x#3], [count(1) AS cnt#15L, x#3]
+- Project [x#3]
+- Filter isnotnull(x#3)
+- Relation default.t2[x#3,y#4,z#5] parquet
EXPLAIN EXTENDED SELECT DISTINCT b, y FROM t1 INNER JOIN t2 ON t1.a = t2.x;
== Optimized Logical Plan ==
Aggregate [b#1, y#4], [b#1, y#4]
+- Project [b#1, y#4]
+- Join Inner, (a#0 = x#3)
:- PartialAggregate [a#0, b#1], [a#0, b#1]
: +- Project [a#0, b#1]
: +- Filter isnotnull(a#0)
: +- Relation default.t1[a#0,b#1,c#2] parquet
+- Project [x#3, y#4]
+- Filter isnotnull(x#3)
+- Relation default.t2[x#3,y#4,z#5] parquet
SET spark.sql.autoBroadcastJoinThreshold=-1;
EXPLAIN EXTENDED SELECT * FROM t1 WHERE t1.a IN (SELECT x FROM t2);
== Optimized Logical Plan ==
Join LeftSemi, (a#11 = x#14)
:- Relation default.t1[a#11,b#12,c#13] parquet
+- PartialAggregate [x#14], [x#14]
+- Project [x#14]
+- Relation default.t2[x#14,y#15,z#16] parquet
Why are the changes needed?
- Improve query performance
- Many databases have similar rules. For example: Teradata, Calcite, Hive, Trino's PushPartialAggregationThroughJoin, Trino's OptimizeDuplicateInsensitiveJoins and Presto.
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Unit test and benchmark test.
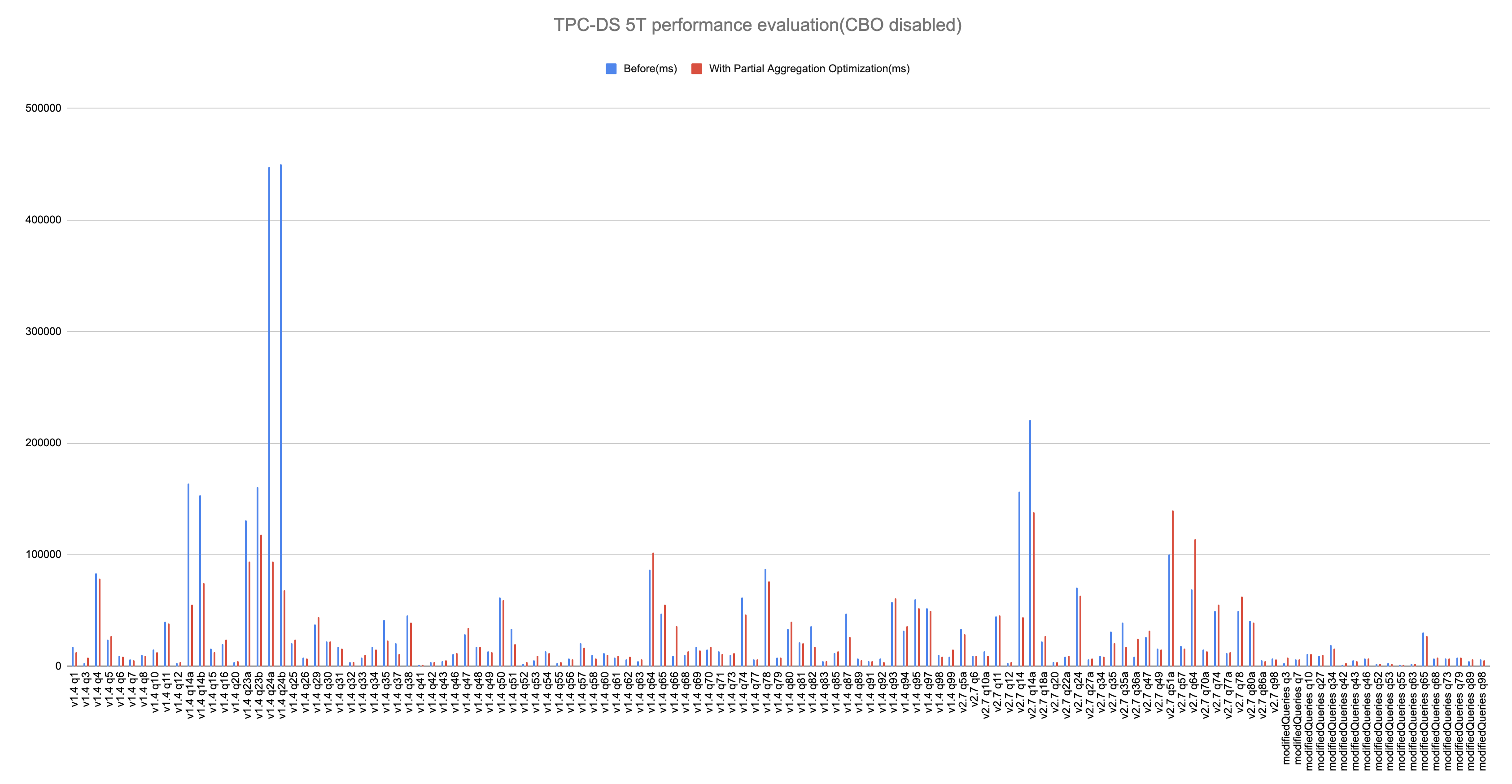
- CBO enabled: spark.sql.cbo.enabled=true, spark.sql.cbo.joinReorder.enabled=true
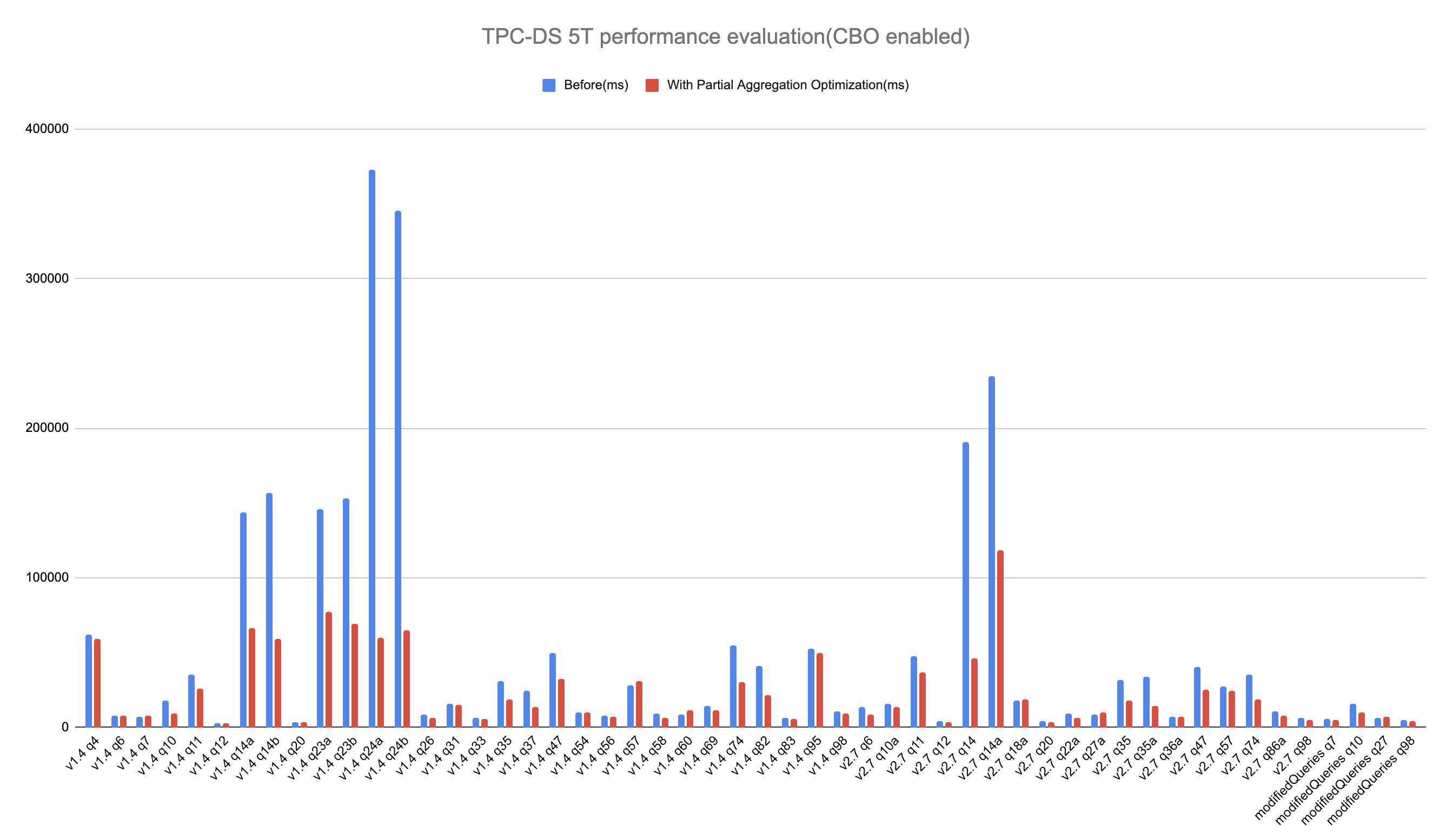
- CBO disabled: spark.sql.cbo.enabled=false, spark.sql.optimizer.partialAggregationOptimization.benefitRatio=1.0
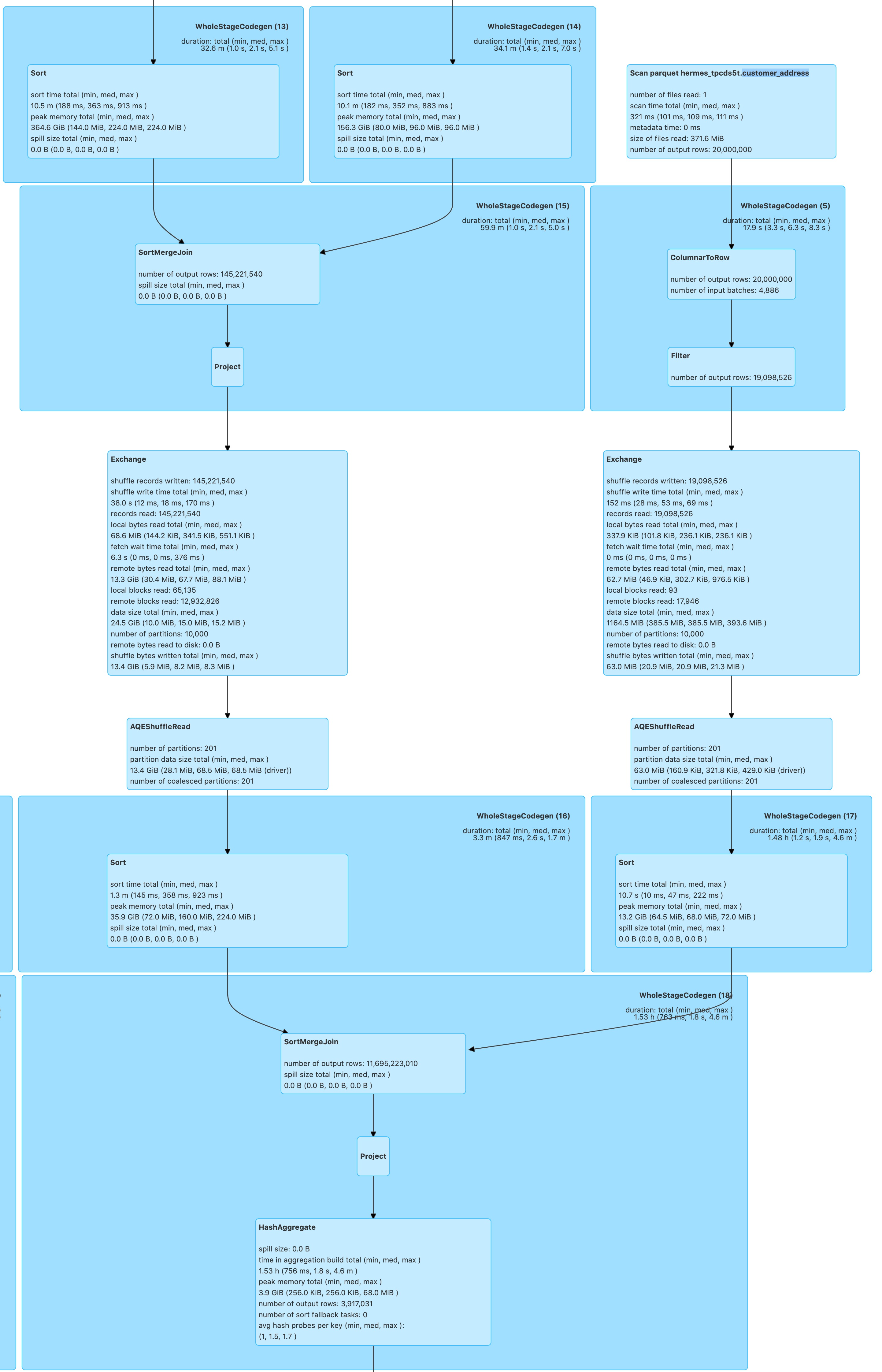
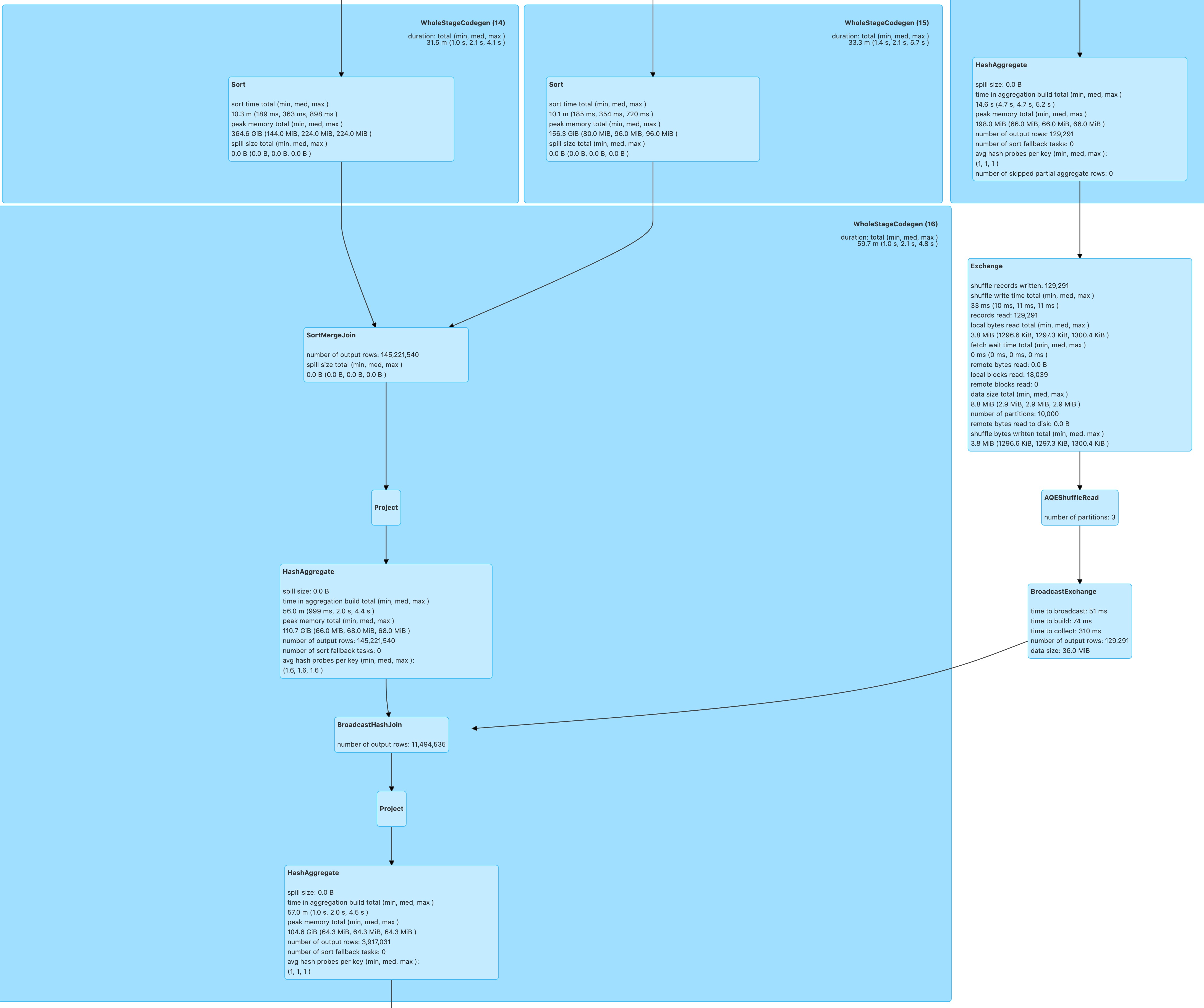
Hi @wangyum according to the paper Eager Aggregation and Lazy Aggregation (pdf), there are several approaches for partial pre-aggregation, including eager group-by, eager count, and double eager (see Figure 2). Which one are you implementing? I guess CBO should iterate these alternatives and make a decision.
@wangyum Hi, I'm not able to find you via the Wechat ID yumwang666. Could you add my Wechat cwang9208?
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!