incubator-uniffle
 incubator-uniffle copied to clipboard
incubator-uniffle copied to clipboard
[Problem] RssUtils#transIndexDataToSegments should consider the length of the data file
Recently, we found that the following exception occurred occasionally in the production environment - Blocks read inconsistent: expectedxxxxxx. After investigation, we found that there seem to be some problems with the client's read hdfs.
The following is some information about cluster related configuration and troubleshooting:
Environment
- rss.client.read.buffer.size=14m
- storageType=MEMORY_HDFS
- io.file.buffer.size=65536(core-site.xml on ShuffleServer)
We investigate abnormal partition files to see what ShuffleServer/Client does at various points in time, The result is as follows.
- 2022-09-20 00:45:07 Partition data file creation on hdfs
- 2022-09-20 00:45:12 End flush the first batch of 1690 blocks and close outputstream, At this point the size of the data file is 63101342
- 2022-09-20 01:26:56 ShuffleServer append partition data file(second batch)
- 2022-09-20 01:27:12 ShuffleServer getInMemory returns a total of 310 blocks
- 2022-09-20 01:27:13 The following exceptions appear in sequence: Read index data under flow, read data file EOFException(with offset[58798659], length[4743511]), and Blocks read inconsistent, and the task retries four times within 10 seconds or fails, which eventually causes the app attempt to fail
- 2022-09-20 01:27:37 End flush the remaining 310 blocks and close outputstream
Read segments
- offset=0, length=14709036
- offset=14709036, length=14698098
- offset=29407134, length=14700350
- offset=44107484, length=14691175
- offset=58798659, length=4743511
The key point of the problem is that the data file has only 63101342 bytes, but at this time, it has to read 4743511 bytes from the 58798659 offset, which eventually leads to OEFException,And at this time, the block from offset 58798659 to offset 63101342 will be discarded, Eventually lead to block missing.
Another question is, why are there more blocks displayed in the index file than in the data file? This depends on the buffer of the hdfs client. If the data is currently being flushed, we cannot guarantee that the number of blocks in the index is the same as the number of blocks in the data.
Can you take a look at the problem I described. @jerqi @smallzhongfeng @zuston
If the data is currently being flushed, we cannot guarantee that the number of blocks in the index is the same as the number of blocks in the data.
@leixm Yes, you are right. Please refer to #204 . but this PR wont solve your problems you mentioned, it just make fail fast and log some exception for analysis.
Let revisit this problem, as I know, the reading sequence of client will from memory -> localfile to hdfs, that means the incomplete data reading won't affect the result.
For example, the partial memory shuffle data is being flushed to HDFS or in the flushing queue, it also will get from the read client side. Although the index file in HDFS is incomplete, the partial data has been accepted from memory. So this is not a problem due to block deduplication mechanism.
So the problems you mentioned make me confused, there should be no problem with the design of reading, there may be some bugs.
By the way, I have also encountered inconsistent block problems, but we are using the memory_localfile mode, which is caused by the instability of grpc service, refer to #198
Feel free to discuss more.
The key point of the problem is that the data file has only 63101342 bytes, but at this time, it has to read 4743511 bytes from the 58798659 offset, which eventually leads to OEFException,And at this time, the block from offset 58798659 to offset 63101342 will be discarded, Eventually lead to block missing. Any block after offset 63101342 will not cause block missing, and any block before offset 63101342 will cause block missing.
The last read segment contains two parts of blocks, [offset= 58798659, length=4302684] and [offset=63101343, length=440827], because the data in the second part triggers EOFException, causing the data in the first part to be discarded, Eventually lead to block missing.
org.apache.uniffle.storage.handler.impl.HdfsFileReader#read
public byte[] read(long offset, int length) {
try {
fsDataInputStream.seek(offset);
byte[] buf = new byte[length];
fsDataInputStream.readFully(buf);
return buf;
} catch (Exception e) {
LOG.warn("Can't read data for path:" + path + " with offset["
+ offset + "], length[" + length + "]", e);
}
return new byte[0];
}
org.apache.uniffle.storage.handler.impl.HdfsFileReader#read
public byte[] read(long offset, int length) { try { fsDataInputStream.seek(offset); byte[] buf = new byte[length]; fsDataInputStream.readFully(buf); return buf; } catch (Exception e) { LOG.warn("Can't read data for path:" + path + " with offset[" + offset + "], length[" + length + "]", e); } return new byte[0]; }
So we should process EOFException in this case.
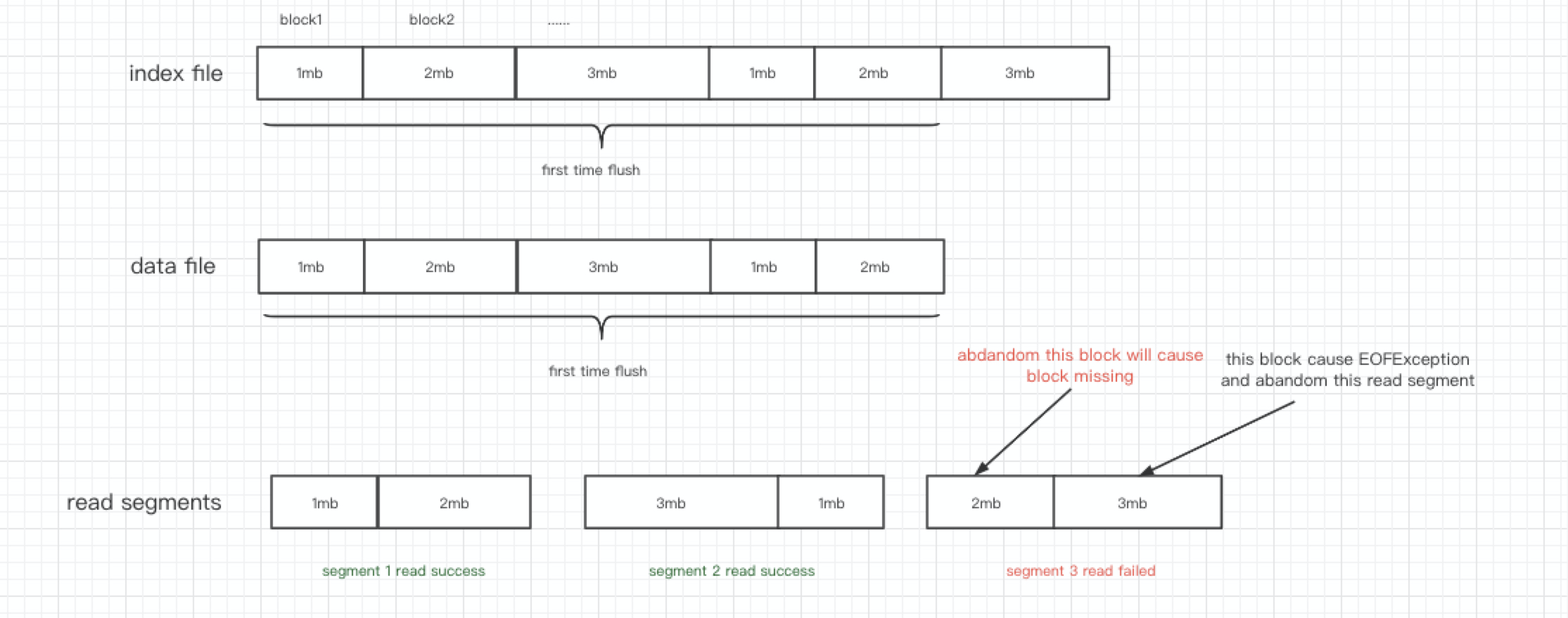
We can get the length of the data file before transIndexDataToSegments and pass it to the transIndexDataToSegments method. When transIndexDataToSegments divides the read segment, Total length cannot exceed the actual length of the data file, so that no OEFException will be generated.
@leixm Thanks for your explanation, got your thought.
Could we directly get the expected data in HdfsFileReader.read() by analyzing the file size and required length from index.file ?
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read is currently obtained by parsing the index file , I think the actual amount of data that can be read needs to be considered in the process of parsing the index file, so as to avoid EOFException. Just like the last block in the picture above, when parsing the index file, it is found that there is no such block according to the length of the data file, and this block should not be added to the segment at this time.
@leixm Thanks for your explanation, got your thought.
Could we directly get the expected data in
HdfsFileReader.read()by analyzing the file size and required length from index.file ?
@zuston The HdfsFileReader.read method seems to be used to read the file content of the specified offset and length, which is not considered here Sophisticated read logic could be better
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read is currently obtained by parsing the index file , I think the actual amount of data that can be read needs to be considered in the process of parsing the index file, so as to avoid EOFException. Just like the last block in the picture above, when parsing the index file, it is found that there is no such block according to the length of the data file, and this block should not be added to the segment at this time.
Could we catch the EOFException and return the data directly?
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read is currently obtained by parsing the index file , I think the actual amount of data that can be read needs to be considered in the process of parsing the index file, so as to avoid EOFException. Just like the last block in the picture above, when parsing the index file, it is found that there is no such block according to the length of the data file, and this block should not be added to the segment at this time.
Could we catch the EOFException and return the data directly?
I will try to test whether the read data is placed in buf after fsDataInputStream.readFully throws an EOFException. If there is data in buf at this time, we can return directly.
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read is currently obtained by parsing the index file , I think the actual amount of data that can be read needs to be considered in the process of parsing the index file, so as to avoid EOFException. Just like the last block in the picture above, when parsing the index file, it is found that there is no such block according to the length of the data file, and this block should not be added to the segment at this time.
Could we catch the EOFException and return the data directly?
It doesn't seem feasible, because we also need to get the correct bufferSegments, if an EOFEXception is thrown, we don't know which bufferSegments are complete.
You are right, we need to know how much data can be read before HdfsFileReader#read, and then read the corresponding data through HdfsFileReader#read, but how much data can be read is currently obtained by parsing the index file , I think the actual amount of data that can be read needs to be considered in the process of parsing the index file, so as to avoid EOFException. Just like the last block in the picture above, when parsing the index file, it is found that there is no such block according to the length of the data file, and this block should not be added to the segment at this time.
Could we catch the EOFException and return the data directly?
It doesn't seem feasible, because we also need to get the correct bufferSegments, if an EOFEXception is thrown, we don't know which bufferSegments are complete.
I can't get your point. Why don't we know which bufferSegments are complete?
When we encounter EOFException, we have read some index data, we can return the data that we have read.
When we encounter EOFException, we have read some index data, we can return the data that we have read.
DataSkippableReadHandler#readShuffleData return ShuffleDataResult, ShuffleDataResult includes two properties, data and bufferSegments, so we will return the block of bufferSegments to be larger than data.
When we encounter EOFException, we have read some index data, we can return the data that we have read.
DataSkippableReadHandler#readShuffleData return ShuffleDataResult, ShuffleDataResult includes two properties, data and bufferSegments, so we will return the block of bufferSegments to be larger than data.
ok