incubator-hugegraph
 incubator-hugegraph copied to clipboard
incubator-hugegraph copied to clipboard
[Bug] mysql 后端导入数据可能出现数据覆盖 (base64编码后)
Bug Type (问题类型)
logic (逻辑设计问题)
Before submit
Environment (环境信息)
- Server Version: v0.11.x
Expected & Actual behavior (期望与实际表现)
使用mysql作为存储后端的时候插入数据的时候应该所有顶点插入。
目前出现问题会少顶点。
下图是新建顶点的时候,提交的数据id日志。customId 是自定义的long类型id。 storeId是hugegraph往数据库中插入数据时通过IdGenerator转换出来的base64值。在提交的时候一共插入了49个顶点
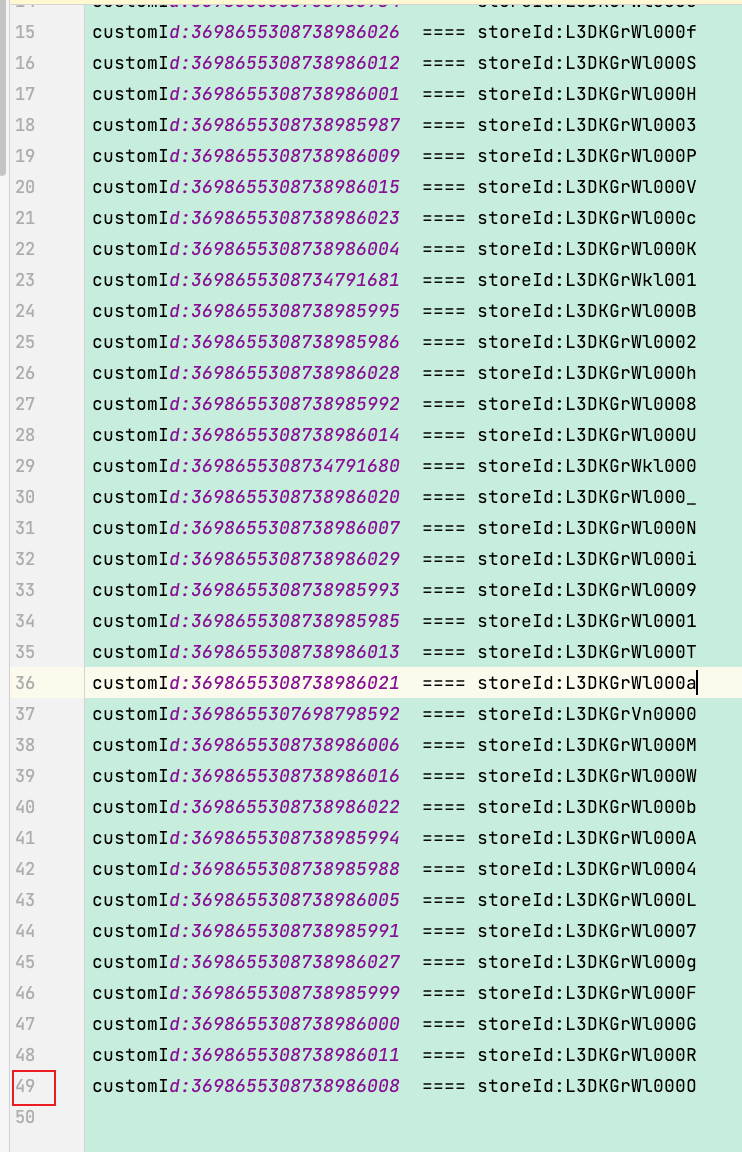
数据库中查看插入的id,一共只有41个

问题说明:
通过IdGenerator转换id的base64值时,会出现最后以为字符只有大小写不一样的情况:
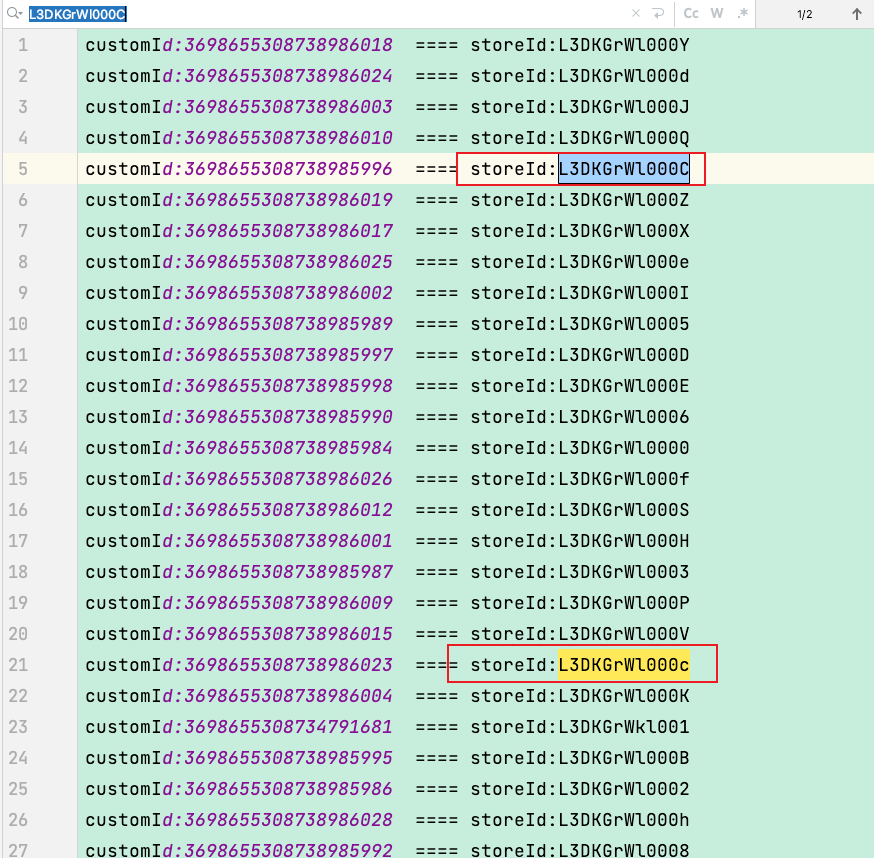 在mysql作为存储后端的时候,使用的语句是replace into,而mysql中是不区分大小写的,所以在插入的时候会出现更新覆盖id和propertis情况,导致插入的顶点丢失
在mysql作为存储后端的时候,使用的语句是replace into,而mysql中是不区分大小写的,所以在插入的时候会出现更新覆盖id和propertis情况,导致插入的顶点丢失
目前看了0.12版本的代码,逻辑都没有变化,应该也会出现这个问题
Vertex/Edge example (问题点 / 边数据举例)
No response
Schema [VertexLabel, EdgeLabel, IndexLabel] (元数据结构)
No response
在mysql作为存储后端的时候,使用的语句是replace into,而mysql中是不区分大小写的,所以在插入的时候会出现更新覆盖id和propertis情况,导致插入的顶点丢失
看起来两个简单的解决方案:
- 换一个原本就不区分大小写的 id 字符生成方式
- 让 mysql 导入的时候能区分大小写?
有意愿可以尝试 PR fix 下
@javeme base64 编码是什么考虑呢, 它长度还不固定(占用空间也大)
在mysql作为存储后端的时候,使用的语句是replace into,而mysql中是不区分大小写的,所以在插入的时候会出现更新覆盖id和propertis情况,导致插入的顶点丢失
看起来两个解决方案:
- 换一个原本就不区分大小写的 id 字符生成方式
- 让 mysql 导入的时候能区分大小写?
似乎优先考虑第二个合力点? 有意愿可以尝试 PR fix 下
这里比较好奇为什么需要在数据库里面存一个Base64的值,如果是为了加密 那使用一个对称加密的方式生成id也可以避免这种情况的。
而且这里似乎会出现的问题具有普遍性,只要是不区分大小写的后端存储 都会有这个风险。最好是能唯一确定入库时的id