hudi
 hudi copied to clipboard
hudi copied to clipboard
[SUPPORT] Metadata table not cleaned / compacted, log files growing rapidly
Describe the problem you faced We are running AWS Glue job to perform a daily compact+clean for our data set (3 tables in serial order). The Glue times out on a day, we started to observe a few things:
- compaction stopped: log files are growing for the affected tables.
- archived files stopped to be generated into archived folder.
- compaction timeline did not finished for that run (only .requested and .inflight present for particular run)
For example:
2023-04-02 02:53:59 0 20230402094244750.compaction.inflight
2023-04-02 02:53:57 961221 20230402094244750.compaction.requested
The large number of files is eating up our S3 connections and slowing down our job dramatically.
To Reproduce
Steps to reproduce the behavior:
- Start Glue job which runs
hoodieCompactor.compact(...)on a Hudi table. - Glue job timesout before the compact finishes.
Expected behavior The failed compaction should be rolled back automatically, next compaction run should be able to compact and reduce the log file count.
Environment Description
-
Glue version: Glue 4.0
-
Hudi version : 0.13.0
-
Spark version : 3.3
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : no
Additional context
Compactor and Cleaner configs
compactorCfg.sparkMemory = 10G
compactorCfg.runningMode = HoodieCompactor.SCHEDULE_AND_EXECUTE
compactorCfg.retry = 1
Cleaner config:
cleanerCfg.configs.add(s"hoodie.cleaner.commits.retained=10")
Stacktrace
We did not see exception print.
Below is the screenshot of the Spark history server timeline.
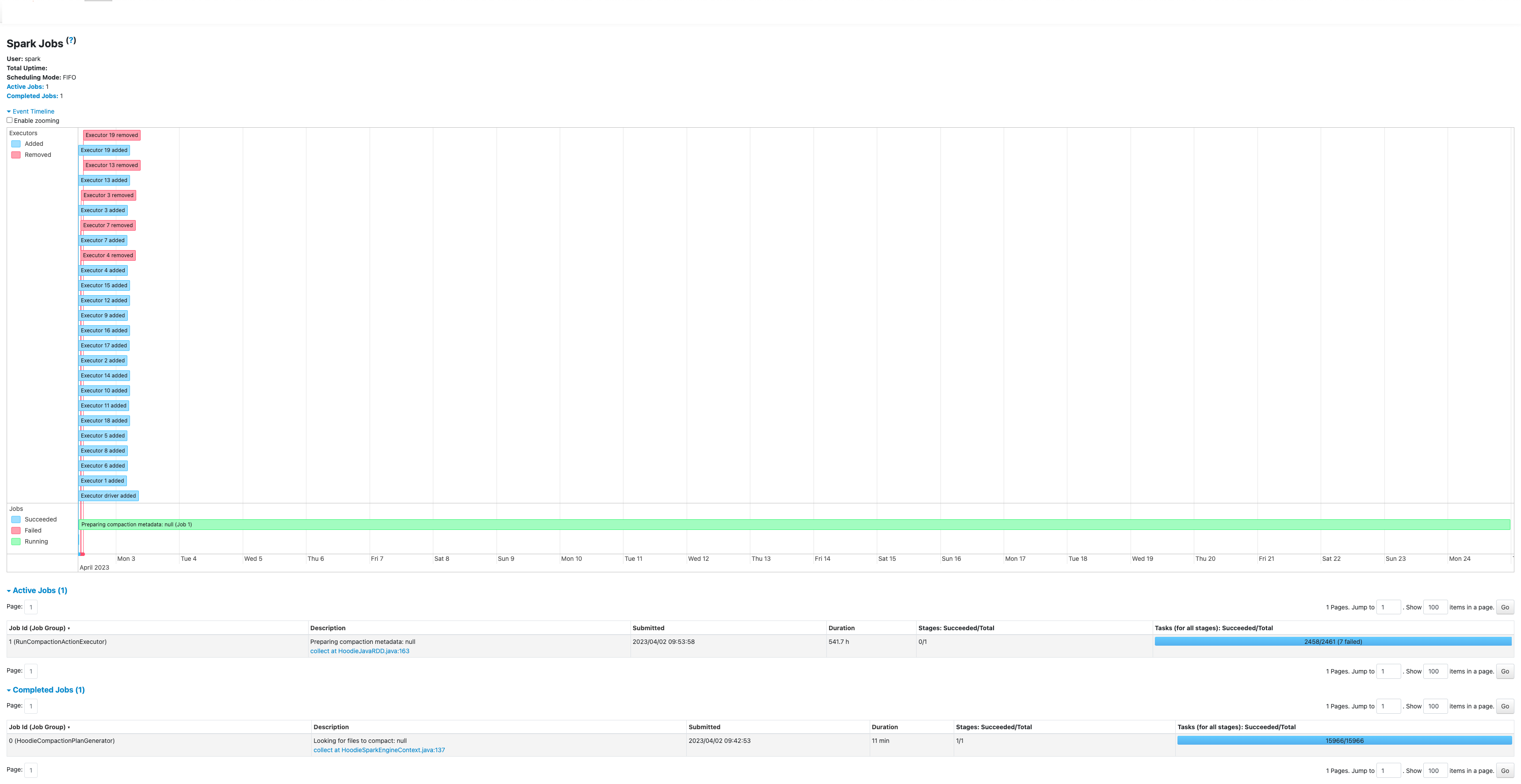
if you have any pending/inflight in data table timeline, metadata table compaction will stalled until that gets to completion. may be there is some lingering pending operation (clustering or something) which we need to chase and fix them if its just left hanging. can you post the contents of ".hoodie". please do sort the out out based on last mod time.
Hi @nsivabalan, yes, I check the timeline of our table. there's a compaction that's pending. we only realized this a recently and it's been running for some time. So there's a long list of files. I added it to this gist: https://gist.github.com/haoranzz/85639ac07d701af755a59b81d16da453 The gist contains up to Apr 20.
I believe the one that has trouble is 20230301064201867
I also run into this issue with 0.14.0. Can we have fsck/repair for those cases? - I finally corrupt this table:)
There might be no good solutions for 0..x release, recently we have merged a PR that address this issue on master branch: https://github.com/apache/hudi/pull/10874, it would be involved in 1.0.0 GA release.
if you have any pending/inflight in data table timeline, metadata table compaction will stalled until that gets to completion. may be there is some lingering pending operation (clustering or something) which we need to chase and fix them if its just left hanging. can you post the contents of ".hoodie". please do sort the out out based on last mod time.
Yes - checking .hoodie folder, we find pending .hoodie/20240412125709660.commit.requested. As a result, spark streaming ingestion process can not write new incoming data into table. Is it safe to remove this pending commit to fix this issue? Thanks.
2a0969c9972ef746d377dbddd278ef13bf3d299d
For mor table, it should be fine if it is the upsert semantics.