hudi
 hudi copied to clipboard
hudi copied to clipboard
[HUDI-4561] Improve incremental query using the fileSlice adjacent to read.end-commit
when we incremental query a hudi table, if
// 1. there are files in metadata be deleted; // 2. read from earliest // 3. the start commit is archived // 4. the end commit is archived this query will turns to a fullTableScan. In this condition, the endInstant parameter in getInputSplits() will be the latest instance, cause to scan the latest fileSlice(which may be larger as time goes by) and then open it and filter the record using instantRange. Considering a query scenario, read.start-commit is archived and read.end-commit is in activeTimeLine, this is a fullTableScan. But we can set the endInstant parameter to read.end-commit, not the lastest instance, so as to read less data, more over, if there is an upsert between read.end-commit and the lastest instance, if we use lastest instance as endInstant, we will lose the insert data between read.start-commit and read.end-commit(the data is upserted, so the original data is missing in the lastest instance). Considering another query scenario, read.start-commit is archived and read.end-commit is also archived, this is a fullTableScan. if read.end-commit is long along and be cleaned, but there is savepoint after it, we can use this savepoint to incremental query the table, not care about the data inserted or upserted after the savepoint. The core idea is making the searching fileSlice adjacent to read.end-commit. ps. This PR is based on #6096
If the end commit is active and is used as the filtering instant for scan, shouldn't getLatestFileSliceBeforeOrOn work here ?
If the end commit is active and is used as the filtering instant for scan, shouldn't
getLatestFileSliceBeforeOrOnwork here ?
yes, it works, but it can't handle the condition when end commit is archived, if we use getLatestFileSliceBeforeOrOn, it may be a savepoint or just no fileSlice(be cleaned), thus not right, getLatestFileSliceAfterOrOn can hande it.
if the end commit is active, getLatestFileSliceAfterOrOn may get the right fileSlice or the next fileSlice.
if getLatestFileSliceAfterOrOn not found a fileSlice, we must then search before/reverse, as it may have a fileSlice before which is in the incremental query range(it must be the latest fileSlice in this fileGroup), we should judge if this fileSlice is before the read.start-commit, if it is, we skip this fileSlice, otherwise we use this fileSlice to search. so why getLatestFileSliceAfterOrOnThenBefore
If the end commit is active and is used as the filtering instant for scan, shouldn't
getLatestFileSliceBeforeOrOnwork here ?yes, it works, but it can't handle the condition when end commit is archived, if we use
getLatestFileSliceBeforeOrOn, it may be a savepoint or just no fileSlice(be cleaned), thus not right,getLatestFileSliceAfterOrOncan hande it.if the end commit is active,
getLatestFileSliceAfterOrOnmay get the right fileSlice or the next fileSlice.if
getLatestFileSliceAfterOrOnnot found a fileSlice, we must then search before/reverse, as it may have a fileSlice before which is in the incremental query range(it must be the latest fileSlice in this fileGroup), we should judge if this fileSlice is before the read.start-commit, if it is, we skip this fileSlice, otherwise we use this fileSlice to search. so whygetLatestFileSliceAfterOrOnThenBefore
In general, let's not make things complex here, the only right way for multi-versioning is the timeline instant, one instant has its counterpart fs view, we should not dig into file slices for different version for one snapshot query even though there is performance gain.
If start/end commit are both archived, very probably they are cleaned also, we have 2 choices here
- read the save point commit if there is with greater timestamp
- read the latest commit
If start commit is archived but end commit is active, there is also possibility that the active instants with smaller timestamp that end commit is cleaned, we should check that first before we use the end commit as the fs view version filtering condition, that makes the thing more complex too.
So, i would -1 if this is only an improvement not a bug fix.
If the end commit is active and is used as the filtering instant for scan, shouldn't
getLatestFileSliceBeforeOrOnwork here ?yes, it works, but it can't handle the condition when end commit is archived, if we use
getLatestFileSliceBeforeOrOn, it may be a savepoint or just no fileSlice(be cleaned), thus not right,getLatestFileSliceAfterOrOncan hande it. if the end commit is active,getLatestFileSliceAfterOrOnmay get the right fileSlice or the next fileSlice. ifgetLatestFileSliceAfterOrOnnot found a fileSlice, we must then search before/reverse, as it may have a fileSlice before which is in the incremental query range(it must be the latest fileSlice in this fileGroup), we should judge if this fileSlice is before the read.start-commit, if it is, we skip this fileSlice, otherwise we use this fileSlice to search. so whygetLatestFileSliceAfterOrOnThenBeforeIn general, let's not make things complex here, the only right way for multi-versioning is the timeline instant, one instant has its counterpart fs view, we should not dig into file slices for different version for one snapshot query even though there is performance gain.
If start/end commit are both archived, very probably they are cleaned also, we have 2 choices here
- read the save point commit if there is with greater timestamp
- read the latest commit
If start commit is archived but end commit is active, there is also possibility that the active instants with smaller timestamp that end commit is cleaned, we should check that first before we use the end commit as the fs view version filtering condition, that makes the thing more complex too.
So, i would -1 if this is only an improvement not a bug fix.
 If we read the latest commit, then the upsert between read.end-commit and latest commit will shadow the insert
betweent read.start-commit and read.end-commit, thus incremental query lost the data, is this a bug or not?
If we read the latest commit, then the upsert between read.end-commit and latest commit will shadow the insert
betweent read.start-commit and read.end-commit, thus incremental query lost the data, is this a bug or not?
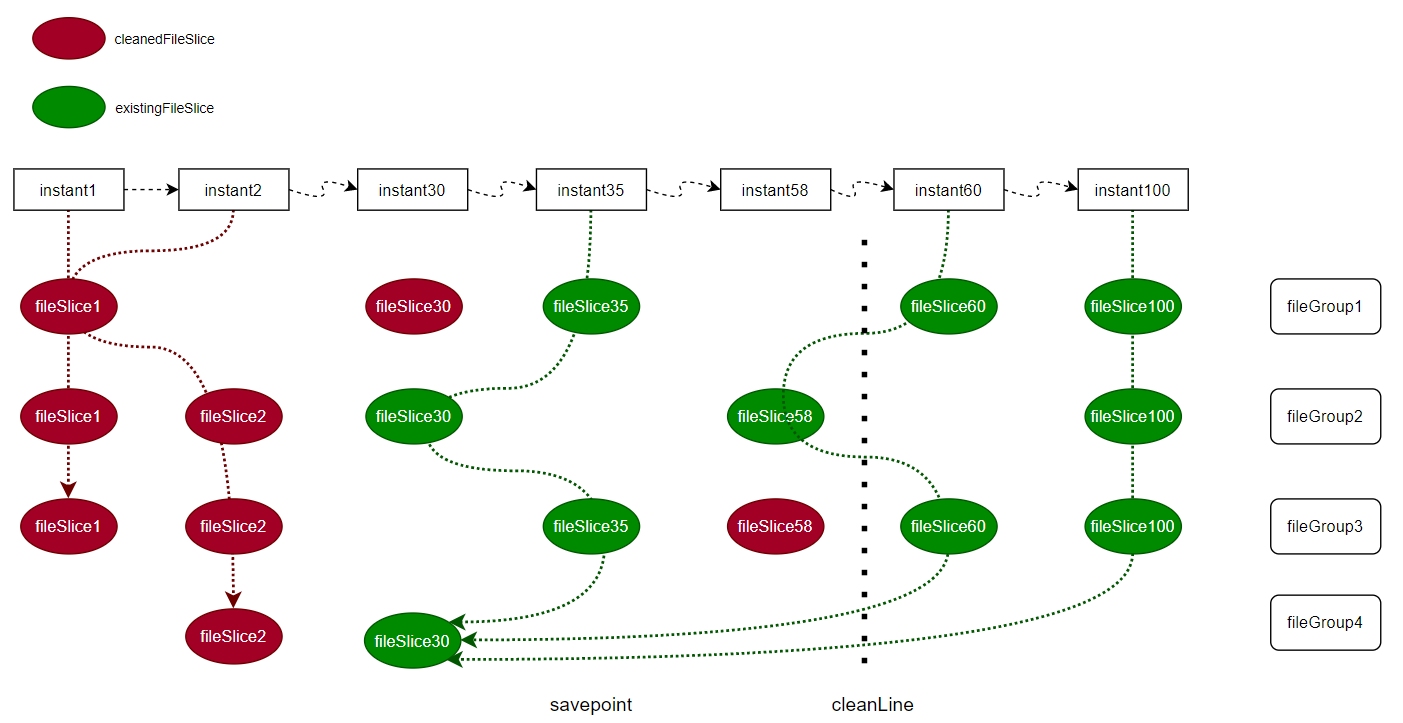
I draw a sketch above, suppose instant35 is a savepoint and we retain 40 commits for clean,above is the timeline
1)if read.end-commit <= instant30, we can use instant35(savepoint) to do incremental query
2)if instant30 < read.end-commit <= instant35, we use [slice35,slice58,slice35,slice30] to do query
3)if instant35 < read.end-commit <= instant58, we can use instant60(the earliest uncleaned instant) to do query
4)if instant58 < read.end-commit <= instant60, we use [slice60, slice61?, slice60, slice30] to do query
5)if read.end-commit > instant60, we use the original getLatestFileSliceBeforeOrOn logic
As you said "we should not dig into file slices for different version for one snapshot query", I understand it as we should use one instant's fs view(flieSlice combination), not recombine as 2) and 4)
Then consider another solution, get the savepoint instant or earliest uncleaned instant just after the read.end-commit, then use
this instant as the parameter of getLatestFileSliceBeforeOrOn, the problem is how we can easliy get the
earliest uncleaned instant just after the read.end-commit, as we don't have a timeline which is dataActive?
Can we just align the FirstNonSavepointActiveCommit to EarliestNonSavepointUncleanedCommit? Then will be simpler in many processing logic.
CI report:
- cb353b3c86d91866ff0493860f3d0e77349e9d98 Azure: FAILURE
Bot commands
@hudi-bot supports the following commands:@hudi-bot run azurere-run the last Azure build