dolphinscheduler
 dolphinscheduler copied to clipboard
dolphinscheduler copied to clipboard
[Feature][Executor] Add K8S Executor for task dispatching
Search before asking
- [X] I had searched in the issues and found no similar feature requirement.
Description
- Still WIP.
- Discussions are more than welcome.
Why we need it?
- Higher resource utilization - The core idea is
one task per pod. With the help of K8S metrics server, users could clearly get the resource consumption data for each task (both CPU and Memory) so that they could adjust and allocate suitable amount of resources based on the data to each specific task pod and achieve global minimum resource consumption. In the future, we might even useK8S VPAto automatically adjust the resource allocation. - Better monitoring (pod level, cloud native, K8S metrics server)
- Easier fault tolerance
- Faster iteration, for updating task plugin, there is no need to upgrade all workers.
How to design it?
Compatibility
- Do some decoupling and abstraction work before adding a K8S executor. Make executor configurable. If users choose not to use
K8S Executor, he will be able to use the current way - one worker per pod.
Fault Tolerance
- Make DS worker stateless in K8S environment (one task per pod)
- DS worker does not need to rely on ZK. We could start a thread in K8S executor to interact with K8S watcher to subscribe to the state change event of worker pod. Since one task per pod, there is no need to decide which pod to resume the task execution if worker crashes, just start a new one.
Communication With Master
- Is it possible to use a simpler way instead of
Nettyfor communication between worker and master in K8S environment? Such as a message queue? Since there is one task per pod andK8S Executorcould kill the pod through K8S API server, looks like not necessary to useNettyserver and client in worker in K8S environment. For logging, we could use PV or remote logging. Maybe we could find a simpler way for K8S Executor to passTaskExecutionContextinto worker.
Combined With DS Hadoop Executor
- For difference, we temporarily call current executor as DS HadoopExecutor.
- There is no perfect solution, only trade-off. Pros and cons?
- detach(async) vs attach(sync) - sync task, resource usage hard to estimate -> use Hadoop Executor (one worker per pod); async task, resource usage easy to estimate -> use K8S Executor (one task per pod)
- Two queues for two executors:
HadoopTaskPriorityQueueandK8STaskPriorityQueue - For Hadoop Executor (one worker one pod), we could add worker pod elasticity feature, also mentioned in #9337 One possible solution is to use
K8S HPAandKEDAwith the number of queued and running tasks as the metric.
General Design (Not Detailed)
K8S Executor
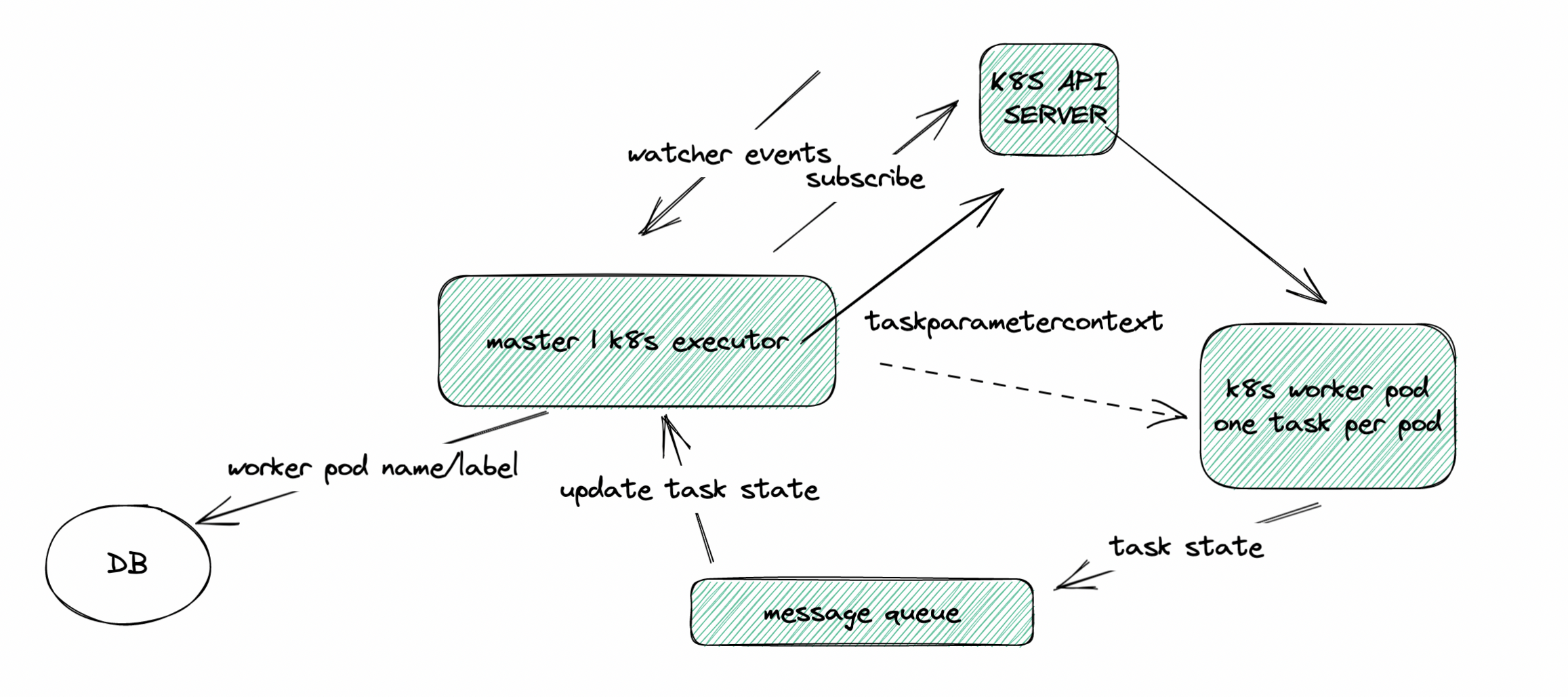
-
With VPA: WIP
-
DS K8S Worker: WIP
-
Pros & Cons
Compound Solution (K8S Executor + Hadoop Executor)
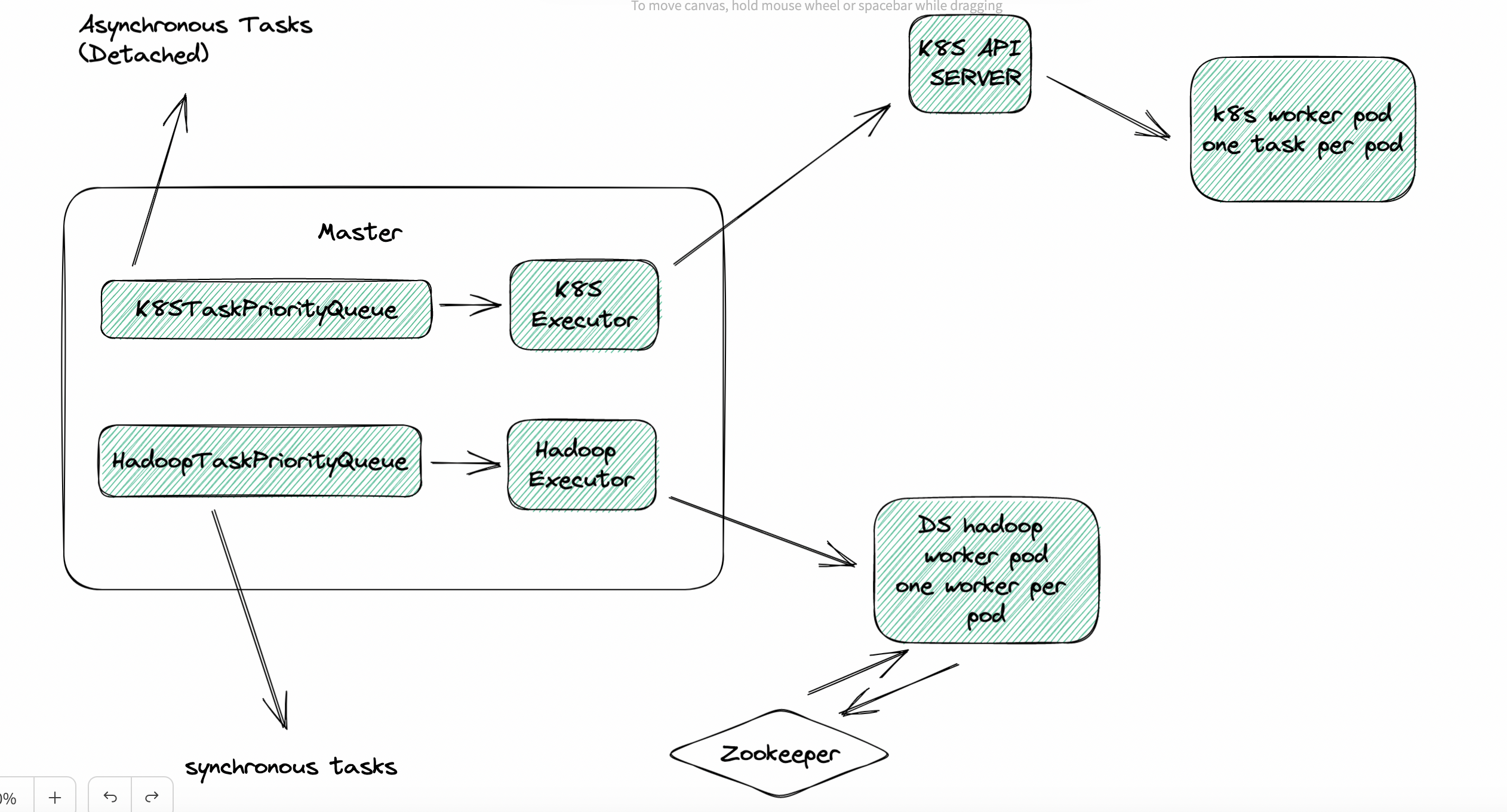
Asynchronous Tasks (Detach)
Synchronous Tasks (Attach)
Maximum Resource Utilization Rate
Elastic Worker

RoadMap & Milestones
Sub-Tasks
Are you willing to submit a PR?
- [X] Yes I am willing to submit a PR!
Code of Conduct
- [X] I agree to follow this project's Code of Conduct
Thank you for your feedback, we have received your issue, Please wait patiently for a reply.
- In order for us to understand your request as soon as possible, please provide detailed information、version or pictures.
- If you haven't received a reply for a long time, you can join our slack and send your question to channel
#troubleshooting
Is it possible to use a simpler way instead of Netty for communication between worker and master in K8S environment? Such as a message queue?
+1, I think if k8s watcher is in master, we can use event queue locally.
Just some drafts, will redraw later:
K8S Executor
Compound Solution - Hadoop + K8S Executor
For #9337 - KEDA + HPA for worker pod scaling (one worker one pod). PS: this is a solution for Hadoop Executor Elasticity, not for K8S Executor:
FYI: K8S HPA: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ K8S VPA: https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
Hi, @EricGao888 , I'm interested in this issue. If help is needed, I am willing to participate in it.
Hi, @EricGao888 , I'm interested in this issue. If help is needed, I am willing to participate in it.
@rickchengx Thanks for reaching out! Feel free to participate in the discussions and design : )
A brief roadmap with several milestones:
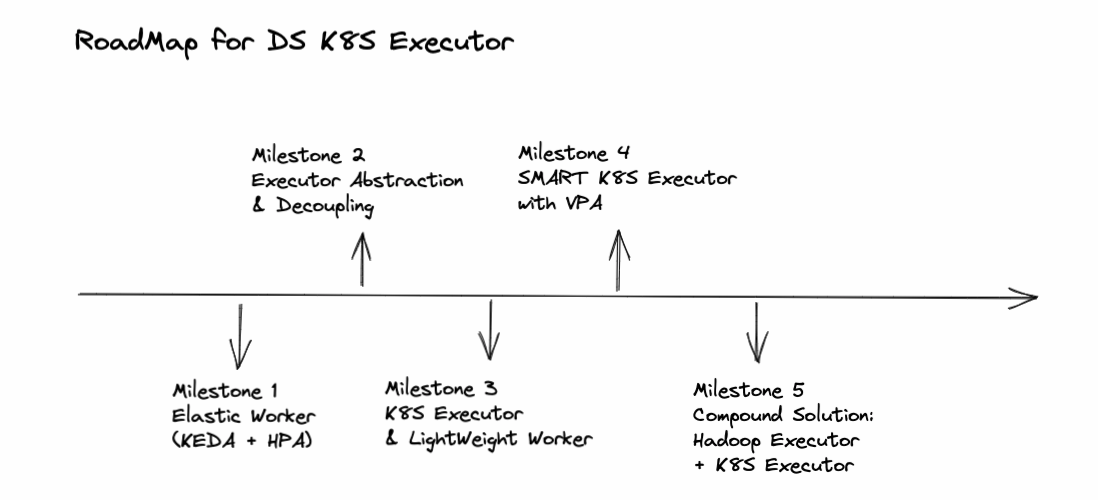
Later this week, I will send a proposal email to dev mailing list : )
Hi, @EricGao888 , it's a promising work! I'm willing to make more contribution to it.
There is no perfect solution, only trade-off.
+1, different users may have different targets of latency and resource utilization, some wish to maximize throughput under limited resources, and others may desire high resource utilization. When using k8s executor, because of stateless and one task per pod design, it can easily meet resource utilization target, however, some problems like cold start of container will affect latency. The problem will be exaggerated when task execution time is short, at this time, hadoop executor is better.
I have a question. In the scenario where each task has one pod, how to determine the resources of each pod?
I will focus on CI / security and have no time to follow up with this one this year. Therefore, I close it temporarily.
I think we can reopen this issue, anybody who'd like to implement it can leave a message
目前正在开发弹性资源组件,
原理,资源分两条线a线 现有资源,b线 待定资源
a) 4资源请求->5a 分配可用资源-> 6a 请求使用资源-> 7a 提供资源->8a 提交任务
b) 4资源请求->5b 分配待定资源-> 6b 请求新worker-> 7b 部署worker->8b 注册/报告资源
a线是分配现有资源;b线请求新资源,新资源注册后成为现有资源,变成a线资源,在a线分配
该组件时通用的弹性资源,准备接入组件,增加弹性能力,如,datax,xxl-job,eventbridge,dolphin-scheduler
下图是开发架构:
实现业务资源消费者和launcher,下图xxl-job集成设计
xxl-job的master负责实现业务资源消费者,分片后,分发器按分片(组)申请资源;申请资源后,发布指令,新建执行器