NextFace
 NextFace copied to clipboard
NextFace copied to clipboard
I tried DeepNextFace myself, but landmark loss decreases slowly.
Hey there, thanks for your impressive work! I tried Nextface first and now implemented DeepNextFace by myself, using default resnet152 in pytorch(pretrained on ImageNet), but during step 1, landmark loss decreased in a quite slow way(landmark loss is the same as NextFace), ended up with about 3000. I think it may related to slow fitting of focal and camera position params. Dosen't find more details about the training strategy in your paper including appendix, can you please help?
Hi, are u using only the landmark loss for training? what are ur learning rates? does the loss converges? can u show some intermediate output? please provide more details to see how i could help. 3000 as a loss looks weird to me.
Thanks a lot for your reply, I'll write as much details as I can think of.
Dataset I use is celebA 256x256, 30000 images in total.
landmarks are computed by face_lignment mediapipe, outputs of Resnet152 are:
shape_coeff = output_p[:, :80]
exp_coeff = output_p[:, 80:155]
albedo_coeff = output_p[:, 155:235]
sh_coeffs = output_p[:, 235:478].reshape(-1, self.cfg.SH_bands * self.cfg.SH_bands, 3)
# camera coeff
focals = output_p[:, 478]
rotation = output_p[:, 479:482]
translation = output_p[:, 482:485]
At first stage(I'm wonder if there is any pre-training stage), I trained with regStatModel(of expression, shape and albedo), landmark loss and photo loss, weights of them are the same as your paper said:

landmarkloss = landmarkLoss(self.BFM.landmarksAssociation, cam_vertices, landmarks, focals, self.cam_center)
reg = self.cfg.wi * (regStatModel(shape_coeff, self.BFM.shape_pca_var) + \
regStatModel(exp_coeff, self.BFM.expression_pca_var)) + \
self.cfg.wc * regStatModel(albedo_coeff, self.BFM.diffuse_albedo_pca_var)
ptloss = 1000 * photoLoss(smoothedImage, torch.pow(x.permute(0, 2, 3, 1), 2.2), mask)
loss = landmarkloss + reg + ptloss
learning rate decays per iteration from 1e-4(cosine decay)
when running like this, I can't get any output from rendering, all black(camera can't see the object at all), landmark loss ends up with 3000+. Thus, I added two L1 loss for translation, rotation of network and that of function initCameraPos, goes like this:
1000*ad_loss1(rotation, rots) + ad_loss2(translation, trans)
trans and rots are used for transVertices, not updated during back propagation,
after training 35 epoch with batch_size 8, landmark loss ends up with 10~15, 1000*photo loss ends up with 120~140, L1 losses end up with 9~15, reg ends up with 0.3
If giving shape reg a large penalty, 1000*wi for example, network will ends up with a mean face.
(our lab does not allow us to upload anything from server or PC, so I can't show u the intermediate image, shape of which is far from the input image, having a long chin)
Hey, u should take note that in the paper we were using basel 2009 where here u are using basel 2017. ur Regularizations terms need to be revisited and adjusted. i suggest working on small dataset of hundred or thousands of images to do the hyper parameters tuning.
Plz also increase the landmarks reg weight to be equal to the photo loss. In the paper the photo loss was normalized. Also the landmarks loss term is important especially at the beginning of the training to avoid trivial solution where the face is pushed too far so that the photo loss is equal to zero (u can relax the landmarks weight after few epoches). I suggest starting with large landmarks weights and progressively relax it. Also can u verify on ur side that the gradients are there for the rotation and translation part? i think there is a bug in NextFace that clear the gradients on rotation and translation and i need to fix it in a future push. So plz verify ur gradients
Ulso u dont need to regularize the translation the rotation, increasing the weights of the landmarks loss will indirectly force the network to find the right trans/pos.
I hope that this help u. dont hesitate to ask if u need more help.
Hi, thanks for your patience and help, I'll try small dataset and large landmark loss weight with deleting regularization of translation and rotation.
To be sure I understand your suggestion:
Regularizations terms need to be revisited and adjusted, meaning in DeepNextFace paper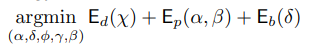 only included shape and albedo reg, but I should change relugarizations term to the same as they are in NextFace Code
only included shape and albedo reg, but I should change relugarizations term to the same as they are in NextFace Code runstep 2, since using BFM2017.increase the landmarks reg weight to be equal to the photo loss, meaning set penalty of landmark loss equal to photoloss? 1000 for example?- learning rate of mine is okay to train encoder and don't need to train as
runstep1in NextFace at the beginning(just using landmark loss, reg and photoloss togther when training encoder is fine) - yes, I'm sure rotation and translation from network
requires_grad=True, and are updating during traning, while rots and trans frominitCameraPosrequires_grad=False. I also found the bug as you said in NextFace, and I think swap the position of self.enableGrad() and self.initCameraPos() in optimizer.py(line 136, 137) should help to make graients be there for them, results of which are slightly better than that of your original code. So I think rots and trans ofiniCameraPosare already good enough to give a proper render result in NextFace.
One more thing, is it possible for you to give me some reference results after first starge training (training only encoder)?
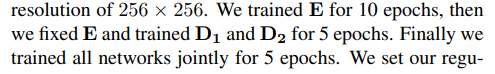 like value of landmarkloss, photoloss, exp reg, shape reg and albedo reg.
like value of landmarkloss, photoloss, exp reg, shape reg and albedo reg.
I tried resnet152 and loss as:
lmloss = landmarkLoss(self.BFM.landmarksAssociation, cam_vertices, landmarks, focals, self.cam_center)
# same reg as NextFace code runstep2
reg = 0.0001 * sh_coeffs.pow(2).mean()
+ 0.001 * regStatModel(albedo_coeffs, self.BFM.diffuse_albedo_pca_var)
+ 0.001 * regStatModel(shape_coeffs, self.BFM.shape_pca,_var)
+ 0.001 * regStatModel(exp_coeffs, self.BFM.expression_pca_var)
photoloss = photoLoss(smoothedImage, torch.pow(x.permute(0, 2, 3, 1),2.2), mask)
loss = lmloss + reg + photoloss
plus focals, rotations and translations are from network, deleting initCameraPos, but this time, focal is always negative, lmloss keeps around 6,000. Model can't converge.
Is there anything I missed during training.....would you plz tell me about ur training strategy(are they same as that in your DeepNextFace Paper's appendix? especially learning rate and loss...)
sorry for asking so many questions, best regards.
Ok joining back this discussion :) Here some suggestions that i hope will help:
- Please use celeba cropped and aligned images (img_align_celeba_png.7z)
- enfore landmarks to be of the same order of magnitude of the photo loss (u can relax it later in the training).
- use a separate fully connected layer for each part of the semantic attribute vector. initialize each fully connected layer properly. For instance initiliaze the fully connected layer for the focal to a positive number. do the same for other attributes (translation, rotation, identity to zero, exp to zero, light to ambiant (first band only)) this should give a good starting point
- U dont need to regularize the cam position and rotation, neither the initCameraPos. I noticed (and u as well) that there is a bug in next face which prvents the gradients from flowing through rotation./translation. plz check ur gradients.
- The regularization terms needs to be adjusted as we are working on basel 2017 here and not 2009 as in the paper.
as a sanity check. U should be able to overfit on few images. if u cant overfit u need to check ur architecture and code.
thanks soooo much!
one small question, dose 3. initiliaze the fully connected layer for the focal to a positive number meaning to set the weight of FC to positive or pretrain FC to set its output to positive?
before you reply, I'll try both :)
just a simple initialization of the layer (set weights to 0 and bias to a constant is enough)
appreciate for your patience.
in Encoder class:
from torchvision.models import resnet152, ResNet152_Weights
self.encoder = resnet152(weights=ResNet152_Weights.DEFAULT)
self.shapeFC = nn.Linear(1000, 80)
self.expFC = nn.Linear(1000, 75)
self.albedoFC = nn.Linear(1000, 80)
......
nn.init.zeros_(self.focalFC.weight)
nn.init.ones_(self.focalFC.bias)
......
# other full connected layers are similar
in train:
img = img.cuda().pow(2.2)
latents, trans, rots, focals, shapecoeff, expresscoeff, albedocoeff, shcoeff = self.Encoder(img)
focals = focals.view(-1)
shcoeff = shcoeff.view(-1, 81, 3)
vertices, diff_albedo, spec_albedo = self.BFM.computeShapeAlbedo(shapecoeff, expresscoeff, albedocoeff)
cam_vertices = self.Cam.transformVertices(vertices, trans, rots)
lmLoss = landmarkLoss(self.BFM, cam_vertices, landmarks, focals, self.center)
regLoss = 0.0001 * shcoeff.pow(2).mean()+self.config.weightAlbedoReg * self.regStatModel(albedocoeff, self.BFM.diffuseAlbedoPcaVar)+ self.config.weightShapeReg * self.regStatModel(shapecoeff, self.BFM.shapePcaVar)+ self.config.weightExpressionReg * self.regStatModel(expresscoeff, self.BFM.expressionPcaVar)
.......
photoLoss = mask * (smoothedImage - render_img).abs()
loss = lmLoss + regLoss + photoLoss
landmarks are detected by mediapipe, BFM is created by class in morphablemodel.py, Cam is create by class in camera.py, landmarkLoss is the same as in pipeline.
我没有复现这个项目,我这边是想把depth加进来和color一起优化。目前来看,需要一个好的rt作为初始值,pnp在我这边有时的解出来的rt有时候有问题,导致网络优化其它参数出现问题。
---Original--- From: @.> Date: Thu, Oct 13, 2022 12:58 PM To: @.>; Cc: @.@.>; Subject: Re: [abdallahdib/NextFace] I tried DeepNextFace myself, but landmarkloss decreases slowly. (Issue #37)
您好,请问您现在复现得怎么样了?-------- 原始邮件 --------发件人: rlczddl @.>日期: 2022年9月27日周二 晚上9:11收件人: abdallahdib/NextFace @.>抄送: 一口酥 @.>, Mention @.>主 题: Re: [abdallahdib/NextFace] I tried DeepNextFace myself, but landmark loss decreases slowly. (Issue #37) 没看到 你加我吧微信:caitong94
---Original---
From: @.***>
Date: Tue, Sep 27, 2022 20:57 PM
To: @.***>;
Cc: @.@.>;
Subject: Re: [abdallahdib/NextFace] I tried DeepNextFace myself, but landmarkloss decreases slowly. (Issue #37)
这是我的邮箱-------- 原始邮件 --------发件人: rlczddl @.>日期: 2022年9月27日周二 晚上8:16收件人: abdallahdib/NextFace @.>抄送: 一口酥 @.>, Mention @.>主 题: Re: [abdallahdib/NextFace] I tried DeepNextFace myself, but landmark loss decreases slowly. (Issue #37)
@anewusername77 I have encountered problems like yours recently.(如果可以的话,可以留个联系方式讨论下)
—Reply to this email directly, view it on GitHub, or unsubscribe.You are receiving this because you were mentioned.Message ID: @.***>
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you commented.Message ID: @.***>
—Reply to this email directly, view it on GitHub, or unsubscribe.You are receiving this because you were mentioned.Message ID: @.> — Reply to this email directly, view it on GitHub, or unsubscribe. You are receiving this because you commented.Message ID: @.>
ur training code looks fine to me. Just initialize ur fully connected layers properly. Fr instance init the focal layer with a good values (3000). same for other semantic params. what is the order of magnitude of lmLoss compared to photoLoss?
do you mean weight of them? they are multiplied with the same weight as 1 : loss = lmLoss + regLoss + photoLoss
Good news is with your instruction, my model managed to converge. Great thanks! Now I'll try decoder part!
hey there, I got a new question while trying decoder. It converges, but diffuse texture loss is much less than spec texture loss. For instance, at the very beginning of training decoder: diff_txl:261, spec_txl:171031. It seems to be the problem of wm=0.5 in specular texureloss.
btw, texture loss function I use is the same as Nextface, regularizers of which are the same as that in your paper:

sorry to bother you again. landmark loss kept around 60 on celeba_align(2.4k imgs), even when i deleted rendering codes, meaning training with landmark loss only.