Zygo
Zygo
Sounds good. Here's what I'm thinking: - There's no significant startup performance gain from the lazy fetching capability--we can just read the entire hash table in the BeesHashTable constructor before...
It seems we will need to support incompatible hash table format changes (see https://github.com/Zygo/bees/issues/33#issuecomment-425136474). Changes to hash table bucket size (assuming the same hash algorithm) can be achieved the same...
The bees hash table consists of Cells, Buckets, and Extents. A Cell is a single {hash, address} entry which points to a location in the filesystem where data with a...
Here's a graph for hash table sizes vs dedupe rates: 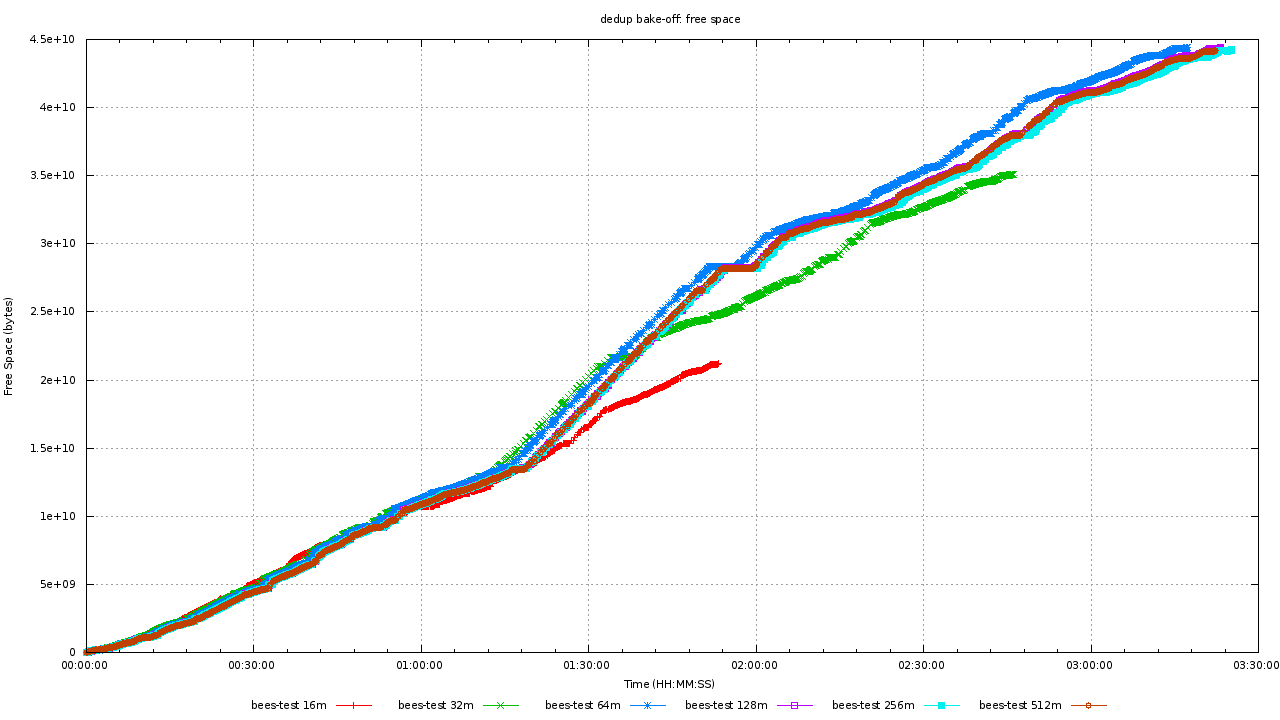 This is a filesystem starting with 104GB of data, 63GB of which is unique. The theoretical maximum hash table...
The individual hash table cells don't change, only their positions in the file (unless at some point in the future there's an option to change the hash length, in which...
It's simpler to do "one pass" then "until done", but one pass is not a complete dedupe. Normally, bees reads each subvol from transid N1 to transid N2, in parallel...
Is it an empty filesystem? It might be a duplicate of #93
Is there any new information on this?
Were there any snapshot deletes just before this? It looks like it might be trying to walk over the subvols to get transids, but fails because there's no path for...
We're going to need to see more log data. All you have pasted there says that bees isn't doing anything, and we already know that. Start from the beginning up...