rasa
 rasa copied to clipboard
rasa copied to clipboard
Update crf_entity_extractor.py
HI all! I think there's a small typo: probably it should call the method islower() instead of lower(). Thanks!
Proposed changes:
- call the method islower() instead of lower(), since it's extracting features (like isdigit(), isupper().. )
Status (please check what you already did):
- [ ] added some tests for the functionality
- [ ] updated the documentation
- [ ] updated the changelog (please check changelog for instructions)
- [ ] reformat files using
black(please check Readme for instructions)
Hi there! could you kindly tell me if there's anything wrong with my PR? it's a very simple fix, an 'islower()' instead of 'lower()'. If I have to change it (or if it's correct this way) please let me know. Thanks! Leo
@leonardofoderaro
I retracted the approval because although I agree with your initial assessment, it has knock-on consequences for users of the extractor.
Up until now, that .LOW feature was a string of lowercased characters. I'm not sure this was the intention, but that's how it's been behaving.
If it now becomes a boolean feature (islower), that could change extraction behaviour. I want to further check the history of the current implementation, to make sure it really is a typo, rather than by design.
melindaloubser1 thank you for the explanation! Looking at the other features I assumed it should have been a boolean. Please let me know if there's anything else I can do, I'm quite new to these internals and I'd like to understand them better. Thanks!
@leonardofoderaro I do think your analysis of this is correct and that you actually found a bug in the implementation of the extractor there, or, alternatively, we have a bug in the documentation; see this screenshot from https://rasa.com/docs/rasa/components#crfentityextractor:
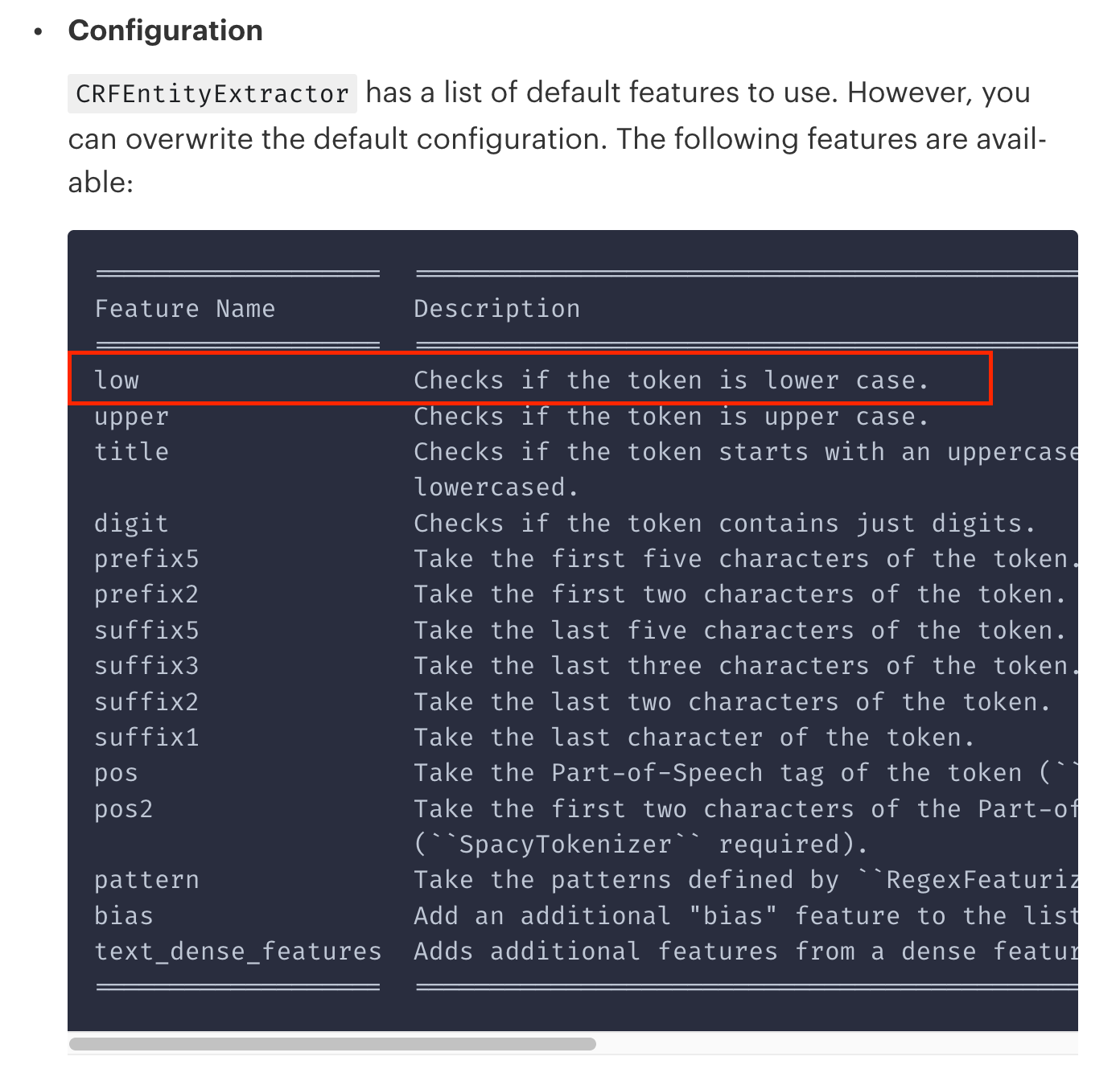
However, @melindaloubser1 has a point there that changes this may have consequences on running assistants. @amn41 can you chime in here about the risk of fixing this? 🙂
@twerkmeister so I can update the branch and resubmit the fix? or it's the documentation to be fixed? Thanks!
Actually, I was wrong. I did some more investigation and found:
- It's been like this since Rasa 1.6 (the oldest branch I could find)
- It's done like this in the
sklearn-crfsuitetutorial https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html , where they call that feature word identity - It wouldn't make much sense to use
.islower()looking at our default feature set for the previous and the next word. Having justis lower,is titleandis upperwouldn't give you a lot of information about those words. - Also
is titleandis upperalready give you pretty much the information foris lowergiven that capitalizations rarely happen within a word, which would be the only thing they wouldn't capture.
I think we should change the documentation instead.