PaddleClas
 PaddleClas copied to clipboard
PaddleClas copied to clipboard
使用PaddleClas中的TripletLossV2报错
1.PaddleClas版本: PaddleClas v2.3.1
2.涉及的其他产品使用的版本号:无
3.训练环境信息: BML Codelab
a: 具体操作系统 Linux version 4.15.0-140-generic (buildd@lgw01-amd64-054) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04))
b. Python版本号: Python 3.7.4
c. CUDA/cuDNN版本,Cuda compilation tools, release 10.1, V10.1.243
4.完整的代码(相比于repo中代码,有改动的地方)、详细的错误信息及相关log
使用TripletLossV2报错,报错信息如下:
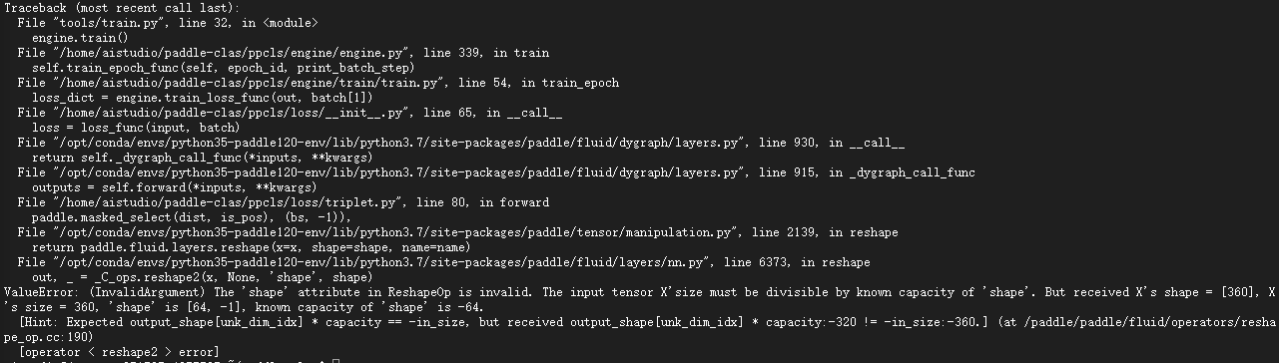 TripletLossV2相关代码:
https://github.com/PaddlePaddle/PaddleClas/blob/f677f61ea3b34281968d1059f4f8f13c1d787e67/ppcls/loss/triplet.py#L59-L68
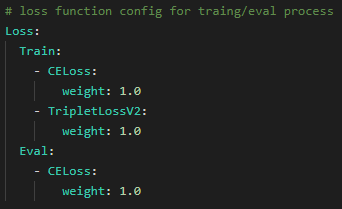
yaml配置文件中Loss相关配置如下:
TripletLossV2相关代码:
https://github.com/PaddlePaddle/PaddleClas/blob/f677f61ea3b34281968d1059f4f8f13c1d787e67/ppcls/loss/triplet.py#L59-L68
yaml配置文件中Loss相关配置如下:
 将代码中用paddle.masked_select函数的处理方式改成使用paddle.where处理之后报错消失,运行良好。
请问这样改可以吗?是否是我对TripletLossV2的使用方式不对?
将代码中用paddle.masked_select函数的处理方式改成使用paddle.where处理之后报错消失,运行良好。
请问这样改可以吗?是否是我对TripletLossV2的使用方式不对?
感谢您的解答,将sampler改成pk_sampler之后,训练确实可以正常运行了。 看了一下代码,根据我的理解,pk_sampler将同一个batch中的样本等分成不同的组,组内的样本label相同,因此保证了is_pos和is_neg矩阵中正负样本的数量均为batch size的整数倍,是这样吗?
感谢您的解答,将sampler改成pk_sampler之后,训练确实可以正常运行了。 看了一下代码,根据我的理解,pk_sampler将同一个batch中的样本等分成不同的组,组内的样本label相同,因此保证了is_pos和is_neg矩阵中正负样本的数量均为batch size的整数倍,是这样吗?
为什么我选pk_sampler,显示未定义