Paddle
 Paddle copied to clipboard
Paddle copied to clipboard
PaddlePaddle Hackathon 3 No.45 & 46】:为 Paddle cumsum和logcumsumexp 支持 float16 数据类型
PR types
Performance optimization
PR changes
OPs
Describe
为cumsum和logcumsumexp 新增float16 数据类型
测试设备:RTX 2070s
目前cumsum测试结果(仅仅前向):
| Case No. | input_shape | fp32(ms) | fp16(ms) | max_absolute_diff | max_relative_diff |
|---|---|---|---|---|---|
| 1 | [1700971, 1] | 0.214 | 0.1962 | 4.5 | 4.956e-03 |
| 2 | [1700971, 1100] | 18.543 | 12.1031 | 5.970e+02 | 2.915e-01 |
目前logcumsum测试结果(包括前向和后向):
| Case No. | input_shape | fp32(ms) | fp16(ms) | max_absolute_diff | max_relative_diff |
|---|---|---|---|---|---|
| 1 | [1700971, 1] | 9.0573 | 11.556 | 2.469e+00 | 1.703e-01 |
| 2 | [1700971, 1100] | 24.325 | 23.254 | 4.801e+00 | 6.632e-01 |
你的PR提交成功,感谢你对开源项目的贡献! 请关注后续CI自动化测试结果,详情请参考Paddle-CI手册。 Your PR has been submitted. Thanks for your contribution! Please wait for the result of CI firstly. See Paddle CI Manual for details.
@zhangting2020 目前性能未达到预期目标,特别是对于thrust和eigen的接口,用__half或phi::dtype::float16的时候出现明星的精度损失,特别是数据量大的时候更容易放大这部分误差,希望老师能够指导一下。
- 性能数据是如何统计得到的,是否可以贴一下运行的日志?
- 看相对误差还是比较大的,这2个算子的实现都用了eigen或者cub数学库,怀疑其中的sum运算是否并不是fp32精度呢?这块或许只能通过查询这些数学库的内部实现或者文档,因为fp16的累加会造成比较大的误差。
整体实现上建议参考性能优化方法中的介绍,看是否可以尝试使用Kernel Primitive API,其中有Reduce的使用案例。换成CUDA实现,比较好控制Kernel内部计算的一些精度问题,同时Kernel Primitive API或许可以解决目前性能差的问题。
性能数据是如何统计得到的,是否可以贴一下运行的日志?
- 看相对误差还是比较大的,这2个算子的实现都用了eigen或者cub数学库,怀疑其中的sum运算是否并不是fp32精度呢?这块或许只能通过查询这些数学库的内部实现或者文档,因为fp16的累加会造成比较大的误差。
整体实现上建议参考性能优化方法中的介绍,看是否可以尝试使用Kernel Primitive API,其中有Reduce的使用案例。换成CUDA实现,比较好控制Kernel内部计算的一些精度问题,同时Kernel Primitive API或许可以解决目前性能差的问题。
@zhangting2020 我是用paddle下benchmark的repo,测试的性能。我单独调试了thrust,发现了明显的精度差距,所以老师建议,这里用kps重新实现这部分算法?
我是用paddle下benchmark的repo,测试的性能。我单独调试了thrust,发现了明显的精度差距,所以老师建议,这里用kps重新实现这部分算法?
性能这块只要fp16明显好于fp32对于这个任务就可以接受,可以自己多设置一些shape测试,上传下你的测试日志。需要看看是否在大部分情况下都慢?另外我们也可以通过日志确认下统计的数据是不是存在问题。
精度方面的话,数学库由于无法看到内部实现,精度问题并不好查。小一点的shape会有这么大的误差吗?
我是用paddle下benchmark的repo,测试的性能。我单独调试了thrust,发现了明显的精度差距,所以老师建议,这里用kps重新实现这部分算法?
性能这块只要fp16明显好于fp32对于这个任务就可以接受,可以自己多设置一些shape测试,上传下你的测试日志。需要看看是否在大部分情况下都慢?另外我们也可以通过日志确认下统计的数据是不是存在问题。
精度方面的话,数学库由于无法看到内部实现,精度问题并不好查。小一点的shape会有这么大的误差吗?
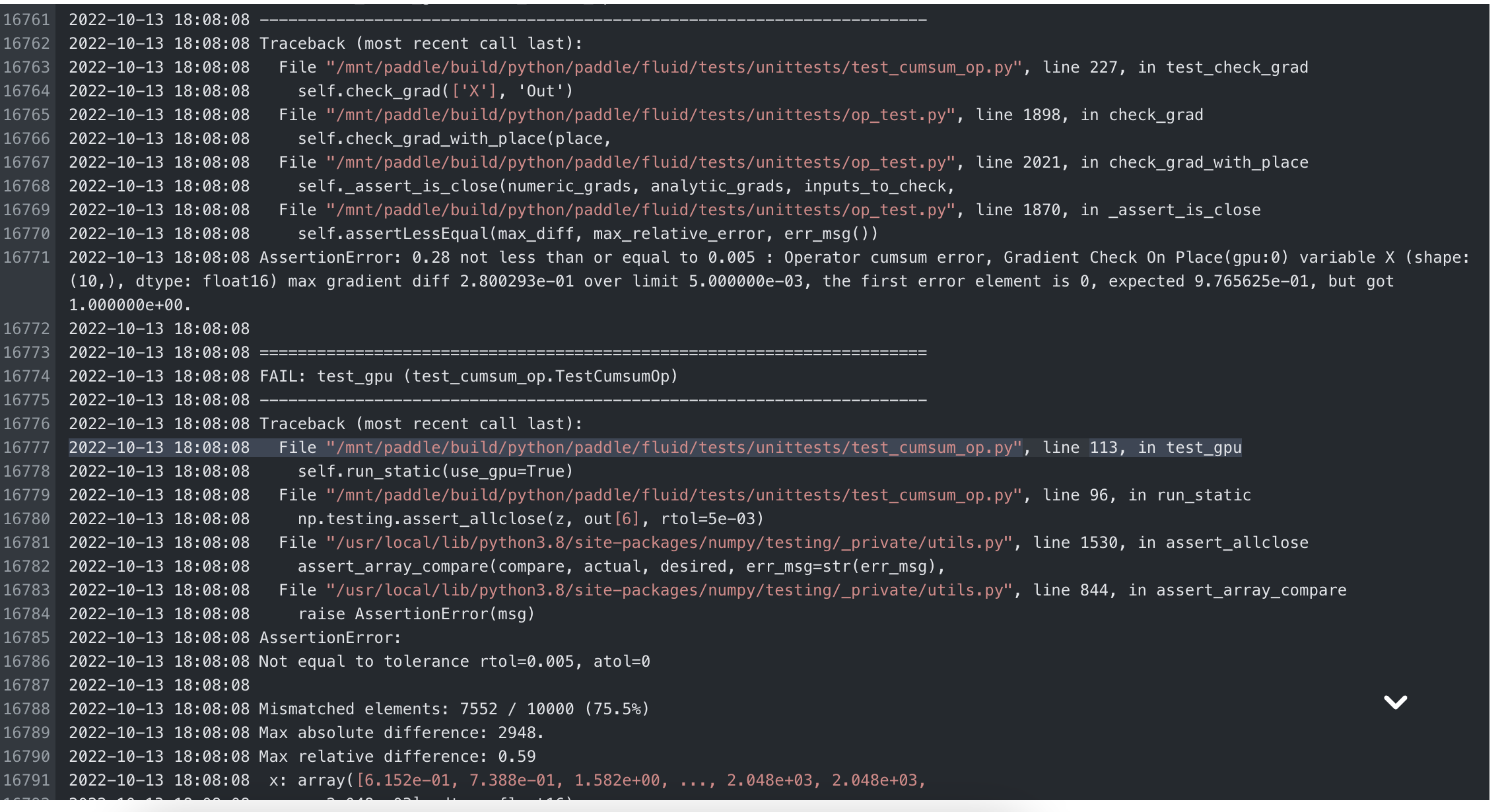
@zhangting2020 对小shape进行了测试,误差会好一些。做了很多尝试,特别是logcumsumexp,发现__half会有明显精度损失, 使用std::log和std::exp速度明显要比cuda内置函数慢很多,但是cuda内置函数可能精度上会掉一点。logcumsumexp中小shape时定位到类型转换时的性能消耗更明显,所以会比fp32还慢。附件是测试日志。
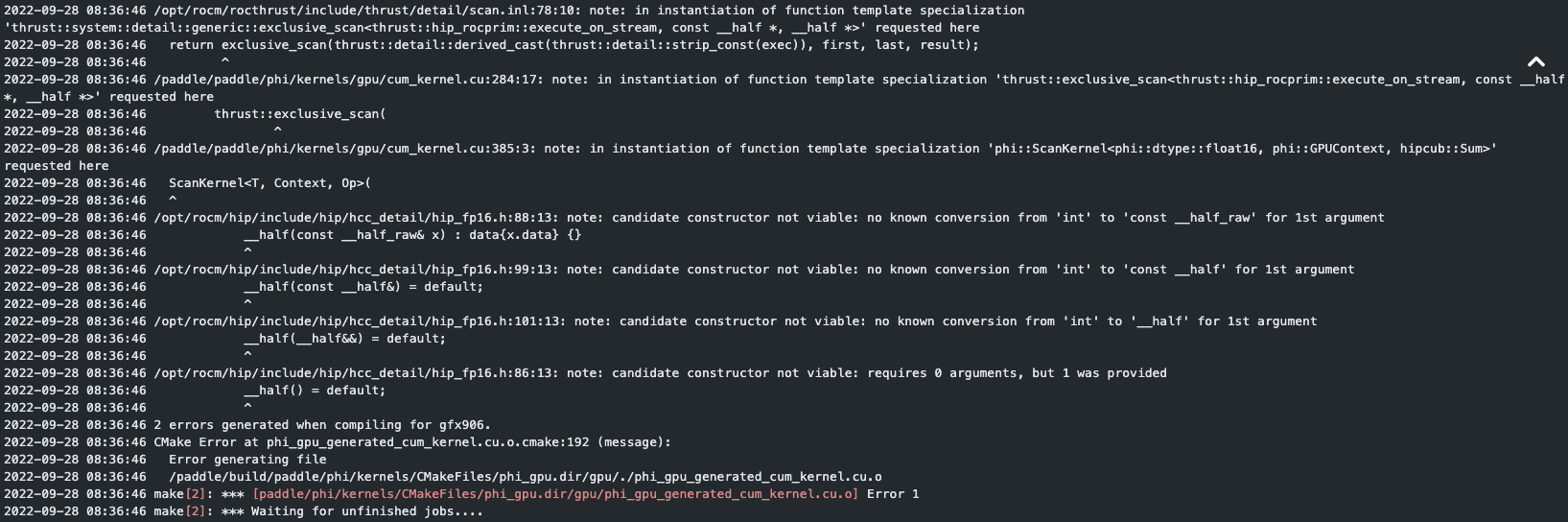
rocm上编译出错,可使用PADDLE_WITH_HIP只为CUDA注册float16。

覆盖率CI显示CPU代码覆盖率不过,实际上我们不要求为CPU注册float16,因为CPU float16没有硬件支持,无法加速。
rocm上编译出错,可使用
PADDLE_WITH_HIP只为CUDA注册float16。
覆盖率CI显示CPU代码覆盖率不过,实际上我们不要求为CPU注册float16,因为CPU float16没有硬件支持,无法加速。
@Xreki 是在注册kernel的时候添加宏定义判断PADDLE_WITH_HIP吗?辛苦老师看下,是否应该是这样写的。
LGTM for docs 随后提个pr把中文文档也改了吧 @Ligoml 中文文档PR已提交 https://github.com/PaddlePaddle/docs/pull/5373