prql
 prql copied to clipboard
prql copied to clipboard
Transform row ordering guarantees
Just learned about this project from HN, it looks really great.
While playing with some of the examples, I noticed that the row ordering guarantees of transforms are unclear to me. In particular I don't understand which transforms (if any?) are guaranteed to leave the order of rows unchanged.
For example, does the query below guarantee that the output rows are ordered by salary?
from employees
sort salary
take 3
filter salary > 0
What about this one?
table x = (
from employees
sort salary
)
from x
From the generated SQL it appears that the answer is NO in both cases (selecting from a CTE has no ordering guarantees in theory). This implies that the following two queries may also produce different row ordering results:
from employees
sort salary
filter salary > 0
from employees
filter salary > 0
sort salary
Maybe that's reasonable, but it would certainly feel surprising. Either way, the exact ordering guarantees of transforms should be documented. Apologies if this is already the case and I missed it.
Standard definition of database relation specifies "a set of ordered tuples", which is what PRQL also uses.
So all of your queries should result in relations ordered by salary.
But, compiler (or rather me) doesn't know that selecting from a CTE has no ordering guarantees. It's another SQL thing I'd call bullshit and something that PRQL must to better. And regarding the compiler, this is a bug.
Thanks for pointing this out, this is why opensource works.
Can you find any resources talking about this? I cannot find any in postgres docs.
Also, does this apply to subqueries? Will this always produce an ordered relation:
SELECT * FROM (SELECT * FROM x ORDER BY a) t;
Standard definition of database relation specifies "a set of ordered tuples", which is what PRQL also uses.
Which standard are you referring to? SQL? AFAIK Relational algebra didn't have a concept of ordered tuples. Everything was a set or a set of sets with not inherent order. SQL tables by default also don't have an inherent ordering AFAIK.
Can you find any resources talking about this? I cannot find any in postgres docs.
The best quote I can give you is this part of PostgreSQL's SELECT documentation:
If the ORDER BY clause is specified, the returned rows are sorted in the specified order. If ORDER BY is not given, the rows are returned in whatever order the system finds fastest to produce. (See ORDER BY Clause below.)
IMO this applies to all SELECT statements, including those selecting from ordered sub-queries and CTEs. Technically this would allow the optimizer to take a query like this:
SELECT *
FROM (SELECT * FROM x ORDER BY y) q
And simplify it into:
SELECT * FROM x
In practice that's not happening in PostgreSQL, but arguably that should be the "order the system finds fastest to produce".
The closest the PostgreSQL documentation comes to admitting that sub-query order by clauses will sometimes be respected is in the Functions Aggregate docs:
Alternatively, supplying the input values from a sorted subquery will usually work. [...] Beware that this approach can fail if the outer query level contains additional processing, such as a join, because that might cause the subquery's output to be reordered before the aggregate is computed..
But it actually warns the user about the precarious nature of relying on sub query ordering.
I'm not aware of any official documentation talking specifically about CTEs. Historically all CTEs in PostgreSQL were materialized in memory during first execution, including any ORDER BY clauses. But even back then you could find PostgreSQL core devs warning against relying on this behavior (e.g. quote from Craig Ringer here).
My conclusion from the above is that PRQL should not rely on the ordering of sub queries or CTEs without re-applying the same order by clause to the outer query.
More importantly, PRQL should be very specific on which transform operations beyond sort might impact row ordering (e.g. JOIN). JOIN is actually where it gets very interesting because DBs will frequently reorder query results for JOINs depending on the JOIN strategy that's being used (e.g. hash joins).
It's another SQL thing I'd call bullshit and something that PRQL must to better.
❤️ Love it! SQL is indeed full of bullshit and I'm very excited about PRQL potentially being able to fix many inherent issues!
Yes, in mathematical definition of relational algebra, relations don't have ordering. But when talking about relations in context of databases, they do (at least wikipedia does).
Thanks for the resources.
I guess the compiler will now have to be extra smart about sorting. It shouldn't just apply sorting to all queries until the next sort, because as explained in the linked SO post, optimizer will not realize that the relation is already sorted and will run sorting multiple times. So correct way is to apply sorting only to the last (outer-most) SELECT.
So algorithm would be:
- iterate over pipeline and find the sorts and store current sorting,
- if group is encountered, clear the sorting,
- if take is encountered, emit an actual ORDER BY,
- at the end, emit an actual ORDER BY.
This implies that the following two queries may also produce different row ordering results:
from employees sort salary filter salary > 0from employees filter salary > 0 sort salary
I very much agree these should be equivalent. Currently they generate exactly the same SQL:
SELECT
*
FROM
employees
WHERE
salary > 0
ORDER BY
salary
Is there an example where queries which should be equivalent don't generate the same SQL? Given the discussion from @aljazerzen , it sounds like those exist.
And then so we can prioritize this — are there examples where the SQL produces different results? Or is this just a theoretical concern, that the SQL could produce different results given the SQL spec?
Or is this just a theoretical concern, that the SQL could produce different results given the SQL spec?
This bug means we can have PRQL query that should return an ordered relation, but result in unordered relation when compiled to SQL and executed by an RDMS.
because as explained in the linked SO post, optimizer will not realize that the relation is already sorted and will run sorting multiple times. So correct way is to apply sorting only to the last (outer-most) SELECT.
Some of the information in the SO post is outdated. Whether or not a PostgreSQL CTE is materialized or not depends on whether its referenced multiple times. It can also be explicitly controlled. See PostgreSQL: Documentation: 15: 7.8. WITH Queries (Common Table Expressions)
Or is this just a theoretical concern, that the SQL could produce different results given the SQL spec?
In most cases it's a theoretical concern for PostgreSQL. But perhaps one day the optimizer will become more aggressive and then it will become a practical concern. Personally I prefer my SQL queries to be unambiguous with regards to the spec/docs and to not have their correctness depend on database implementation details.
That being said, I can come up with practical examples using JOINs. For example, would you consider the following query to maintain the sort (-users.id) transform after applying the join?
from users
sort (-users.id)
take 3
join posts side:left [users.id == posts.user_id]
select users.id
Right now the SQL produced by PRQL does not guarantee any ordering. For example if you create the two tables like this in PostgreSQL 15:
CREATE TABLE users AS SELECT g AS id FROM generate_series(1, 10) g;
CREATE TABLE posts AS SELECT g AS id, (g-1) % 10+1 AS user_id FROM generate_series(1, 1000) g;
The output will be:
8
9
10
8
9
10
...
But if you then run:
CREATE INDEX ON posts (user_id);
VACUUM ANALYZE;
You will get the expected DESC ordering:
10
10
...
9
9
...
8
8
...
So clearly the join transform might reorder the rows from a previous transforms. Perhaps this is reasonable, but I think it needs to be documented.
Otherwise PRQL is more ambiguous than SQL itself when it comes to the ordering of the produced rows.
This bug means we can have PRQL query that should return an ordered relation, but result in unordered relation when compiled to SQL and executed by an RDMS.
I get the theoretical concern — my question is whether this actually happens in practice.
Not saying it's zero-weight if we can't find an example right now — just some difference in priority. Does that make sense? (or if you think implementing the algo you describe above is reasonable, then great, no need to discuss prioritization :) )
I think the join example is good. My guess is people who are used to SQL wouldn't expect that to be ordered, but new users might.
I'll add a paragraph to the sort docs for that
Would filter / WHERE cause inconsistent ordering if separated by a CTE? e.g.
from users
sort (-users.id)
take 10
filter id > 100
I think the join example is good. My guess is people who are used to SQL wouldn't expect that to be ordered, but new users might.
I'll add a paragraph to the
sortdocs for that
This is not limited to join. Grouping has the same issue. Would you expect this query to produce results ordered by user_id?
from posts
sort user_id
take 3
group [user_id] ( aggregate [count])
Looking at the resulting SQL it seems like the answer is right now is: no. In fact the SQL actually seems to be very wrong, the sort user_id transform is completely ignored. That's probably a separate bug:
WITH table_1 AS (
SELECT
user_id
FROM
posts
LIMIT
3
)
SELECT
user_id,
COUNT(*)
FROM
table_1
GROUP BY
user_id
Would
filter/WHEREcause inconsistent ordering if separated by a CTE? e.g.from users sort (-users.id) take 10 filter id > 100
The generated SQL is ambiguous and does not guarantee any ordering in PostgreSQL, the DB is free to execute this query in whatever way is fastest. In practice PostgreSQL 15 will produce ordered results. But future versions of PostgreSQL or other SQL databases may not. My preference would be to change the generated SQL for this case to reapply the sort clause on the outer query. PostgreSQL 15 is smart enough to generate the same plan in both cases, so there is no performance penalty for doing this.
I'll add a paragraph to the sort docs for that
94995bc33bdf19ada56c0cc9a015e7ec7b4a7803 is definitely an improvement. I'd suggest to call out group in addition of join as well.
PostgreSQL 15 is smart enough to generate the same plan in both cases, so there is no performance penalty for doing this.
Are you sure? The linked SO post contains this quote:
Unfortunately IIRC it’s also not smart enough to recognise that the rows are ordered correctly if you add another ORDER BY in the outer query. (Haven’t tested, but pretty sure). So it’s not necessarily free to do it the “right” way.
It seems that the "correct" way would be to push ORDER BY down the pipeline into the last query (or just before take/LIMIT).
But regarding PRQL semantics:
- I strongly believe that relations should have ordering,
- I also believe that transforms should not change this ordering, with exceptions of:
sort- obviouslygroup- because it makes sense, I'll explain belowwindow- for the same reasons as group.
The consequences are:
from x # is not ordered
from x | sort a | take 10 # is ordered
from x | sort a | take 10 | filter a > 3 # is ordered
from x | sort a | group b () # is not ordered
Note that join preserves order, but only of the left side. It is stationary, while the right side is joined in and may get shuffled in the process.
I think that group should remove/reset ordering because in my mind, group is implemented by first partitioning the table into groups (throwing each of the rows into one of the group buckets) and then doing something with those buckets. Even if you don't do anything with the buckets and just return them, the original order was lost.
I'd suggest to call out
groupin addition ofjoinas well.
Done
from x | sort a | group b () # is not ordered
Right, an advanced approach could even strip out the sort given we know it won't affect results. Or lint it.
FWIW I could imagine someone making the case for group having ordering; e.g. groupby in python's standard library maintains order. But I agree people familiar with SQL wouldn't expect it
PostgreSQL 15 is smart enough to generate the same plan in both cases, so there is no performance penalty for doing this.
Are you sure? The linked SO post contains this quote:
Yes, I've tested it. This quote is from 2016. CTEs can be inlined since PostgreSQL 12 was released in late 2019 (see release notes).
Note that join preserves order, but only of the left side. It is stationary, while the right side is joined in and may get shuffled in the process.
That's not true. I already gave a counter-example for it above. If the DB decides to use a hash or merge join (rather than nested loop), the ordering can be lost, even for left joins.
FWIW I could imagine someone making the case for group having ordering; e.g. groupby in python's standard library maintains order. But I agree people familiar with SQL wouldn't expect it
I'm -1 on that. Or at least being able to opt out of it. It could become a performance issue for some queries.
PostgreSQL 15 is smart enough to generate the same plan in both cases, so there is no performance penalty for doing this.
Are you sure? The linked SO post contains this quote:
Yes, I've tested it. This quote is from 2016. CTEs can be inlined since PostgreSQL 12 was released in late 2019 (see release notes).
I'm sure about that too, but I'm asking if Postgres will sort the table twice in this case:
SELECT * FROM (SELECT * FROM x ORDER BY a) t ORDER BY a
Because if it will, PRQL compile should not emit this ORDER BY twice, but just in the outer query.
Note that join preserves order, but only of the left side. It is stationary, while the right side is joined in and may get shuffled in the process.
That's not true. I already gave a counter-example for it above. If the DB decides to use a hash or merge join (rather than nested loop), the ordering can be lost, even for left joins.
I'm talking about PRQL semantics here - what I think join in PRQL should be doing. We can implement that differently in SQL.
FWIW I could imagine someone making the case for group having ordering; e.g. groupby in python's standard library maintains order. But I agree people familiar with SQL wouldn't expect it
@max-sixty Are you talking about preserving the order within the group or order of all rows in the table? If it's the latter, I agree with @felixge - this is very unintuitive and would have bad performance implications.
And Python's itertools.groupby returns consecutive keys and groups. This means that 1 1 1 2 2 1 would group [1, 1, 1], [2, 2], [1], which is quite different from SQL's group which would put all 1 together.
Tbc, I think we agree!
@max-sixty Are you talking about preserving the order within the group or order of all rows in the table? If it's the latter, I agree with @felixge - this is very unintuitive and would have bad performance implications.
i.e. if the groups are all ordered, are they still ordered after the grouping? I wouldn't expect it, but it wouldn't be Wrong to expect it
And Python's
itertools.groupbyreturns consecutive keys and groups. This means that1 1 1 2 2 1would group[1, 1, 1], [2, 2], [1], which is quite different from SQL's group which would put all 1 together.
Agree!
PostgreSQL 15 is smart enough to generate the same plan in both cases, so there is no performance penalty for doing this.
Are you sure? The linked SO post contains this quote:
Yes, I've tested it. This quote is from 2016. CTEs can be inlined since PostgreSQL 12 was released in late 2019 (see release notes).
I'm sure about that too, but I'm asking if Postgres will sort the table twice in this case:
SELECT * FROM (SELECT * FROM x ORDER BY a) t ORDER BY aBecause if it will, PRQL compile should not emit this ORDER BY twice, but just in the outer query.
PostgreSQL will not sort the table twice.
EXPLAIN SELECT * FROM (SELECT * FROM posts ORDER BY id) t;
Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: posts.id
-> Seq Scan on posts (cost=0.00..15.00 rows=1000 width=8)
EXPLAIN SELECT * FROM (SELECT * FROM posts ORDER BY id) t ORDER BY id;
Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: posts.id
-> Seq Scan on posts (cost=0.00..15.00 rows=1000 width=8)
The same is true for CTEs that are referenced only once:
EXPLAIN WITH posts_cte AS (SELECT * FROM posts ORDER BY id LIMIT 3)
SELECT * FROM posts_cte;
Limit (cost=27.92..27.93 rows=3 width=8)
-> Sort (cost=27.92..30.42 rows=1000 width=8)
Sort Key: posts.id
-> Seq Scan on posts (cost=0.00..15.00 rows=1000 width=8)
EXPLAIN WITH posts_cte AS (SELECT * FROM posts ORDER BY id LIMIT 3)
SELECT * FROM posts_cte ORDER BY id;
Limit (cost=27.92..27.93 rows=3 width=8)
-> Sort (cost=27.92..30.42 rows=1000 width=8)
Sort Key: posts.id
-> Seq Scan on posts (cost=0.00..15.00 rows=1000 width=8)
Generally speaking I'd prefer PRQL to emit this ORDER BY twice for correctness. It's the query planners job to recognize and optimize this away. If this causes performance issues for some DBs or rare cases, maybe there could be a way to opt out of this. But the default SQL should optimize for correctness over performance IMO.
Note that join preserves order, but only of the left side. It is stationary, while the right side is joined in and may get shuffled in the process.
That's not true. I already gave a counter-example for it above. If the DB decides to use a hash or merge join (rather than nested loop), the ordering can be lost, even for left joins.
I'm talking about PRQL semantics here - what I think join in PRQL should be doing. We can implement that differently in SQL.
Specifying that PRQL left joins must behave like nested loop JOINs would require any join operation to be followed by an implicit ORDER BY. I'm worried about the performance of this, but I'm also not sure why it should be acceptable for group and window transforms to produce rows in unspecified ordering, but for join an order should be guaranteed?
Generally speaking I'd prefer PRQL to emit this ORDER BY twice for correctness
I'd argue that ORDER BY in the inner SELECT is unnecessary for correctness. Most transforms associate with sort (i.e. filter, take), which means that sort can be "pushed down" in the pipeline to a later stage, without affecting the result.
would require any join operation to be followed by an implicit ORDER BY
Any join operation on a sorted relation.
I'm worried about the performance of this
This is true - having an early sort in a pipeline, followed by a join could cause completely unneeded sorting, because the relation would be sorted by first ORDER BY, then shuffled by a hash JOIN and then sorted again by the implicit ORDER BY.
If we go for "pushing the sort down the pipeline" solution this will not be a problem though - there would be no first ORDER BY.
not sure why it should be acceptable for group and window transforms to produce rows in unspecified ordering, but for join an order should be guaranteed?
This is just how I think when composing pipelines. I'm +0.5 for joins to preserve ordering and -1 for groups.
Generally speaking I'd prefer PRQL to emit this ORDER BY twice for correctness
I'd argue that ORDER BY in the inner SELECT is unnecessary for correctness. Most transforms associate with sort (i.e. filter, take), which means that sort can be "pushed down" in the pipeline to a later stage, without affecting the result.
If you're talking about queries where the ORDER BY is truly redundant like this one, I agree:
SELECT * FROM (SELECT * FROM x ORDER BY a) t ORDER BY a
I was mostly thinking about queries like the ones I gave in the original issue description, e.g.:
from posts
sort user_id
take 3
filter user_id > 0
Right now this produces:
WITH table_1 AS (
SELECT
*
FROM
posts
ORDER BY
user_id
LIMIT
3
)
SELECT
*
FROM
table_1
WHERE
user_id > 0
But I think it should produce:
WITH table_1 AS (
SELECT
*
FROM
posts
ORDER BY
user_id
LIMIT
3
)
SELECT
*
FROM
table_1
WHERE
user_id > 0
ORDER BY user_id
PostgreSQL 15 will use the same query plan for both queries, but the latter query is technically correct, which is the best kind of correct 🙃.
Ah, great example @felixge , this is resonating with me now.
(I'm not sure what the correct answer is — I can see people saying "I didn't want to do another sort" — though my initial inclination is to agree with you.)
It seems that in some cases, Postgres 15 will perform unnecessary work if we feed it too much ORDER BYs:
EXPLAIN
SELECT *, ROW_NUMBER() OVER (ORDER BY invoice_date) as rn
FROM (
SELECT * FROM invoice ORDER BY total
) t ORDER BY total;
Sort (cost=76.16..77.19 rows=412 width=74)
Sort Key: t.total
-> WindowAgg (cost=51.06..58.27 rows=412 width=74)
-> Sort (cost=51.06..52.09 rows=412 width=66)
Sort Key: t.invoice_date
-> Subquery Scan on t (cost=28.01..33.16 rows=412 width=66)
-> Sort (cost=28.01..29.04 rows=412 width=66)
Sort Key: invoice.total
-> Seq Scan on invoice (cost=0.00..10.12 rows=412 width=66)
I think we can implement minimal amount of sorts given the semantics I described. During anchoring, sorts should be pushed down the pipeline until: a) group, window or another sort transform. If one is encountered, original sort has no effect. b) take transform. When encountered, ORDER BY is emitted and original sort is pushed further down the pipeline c) the end of the pipeline, where the ORDER BY is emitted.
This is what I was writing about in this comment: https://github.com/PRQL/prql/issues/1363#issuecomment-1368070461
If we go back to the semantics, what do you two think about join and window preserving order?
It seems that in some cases, Postgres 15 will perform unnecessary work if we feed it too much ORDER BYs:
Yeah. Ideally PRQL would already be able to emit the simpler SQL for it that produces the same results:
EXPLAIN
SELECT *, ROW_NUMBER() OVER (ORDER BY invoice_date) as rn
FROM invoice
ORDER BY total;
Anyway, I like the semantics you're proposing for handling take transforms. I think it will produce the behavior most people would expect.
If we go back to the semantics, what do you two think about join and window preserving order?
If the "Why PRQL?" can be seen as a north star for the project, then I think it has two things to say about this:
- "PRQL is simple, and easy to understand, with a small number of powerful concepts"
- Performance is not mentioned
So it seems that more intuitive sort guarantees should take precedence here. But it would still feel a bit inconsistent that join, window and take keep sorting intact, but group breaks it. It should probably be either all or nothing?
My personal preference would probably be to just document that sort, window, group and take might break previous sort operations. If people complain about it, it's probably easier to add stricter sort guarantees in the future than it is to take them away again. An opt-in/opt-out mechanism also feels clunky.
But yeah take is definitely the one I struggle with. It feels tough to say that take removes sorting guarantees. I guess what's special about take is that it would only break sorting if another transform follows it. join, window and group can break sorting even if they are the last transform.
So maybe only take gets special treatment, and join, group, window get documented as sort-breaking transforms?
I'm a bit torn, but I think the last idea would get my vote tonight 🙃
But it would still feel a bit inconsistent that join, window and take keep sorting intact, but group breaks it. It should probably be either all or nothing?
I feel that it's quite reasonable to expect take to preserve the order and group to break it. That's because of how I think about what these transforms, as I would be doing them on paper:
- take cuts out a range of rows which can remain intact, just as they were before,
- group does that bucketing thing I described, during which the ordering is lost.
might break previous sort operations
I really don't want the semantics to be unpredictable.
So maybe only
takegets special treatment
I'd add join to the "special treatment". What you have a sorted relation and pass it though join to add a column, I would expect ordering to remain intact.
We should strive for transforms to be orthogonal - their effects should be as limited as possible, so they compose nicely. Just like derive and filter should not affect the row order, so shouldn't join. Group and window are different here because their core task is to pull the rows apart and then compose them back together.
I wanted to comment on this when the discussion first started but I was on vacation at the time. I actually got bitten by this the other day and got an unexpected result.
In my Normconf 2022 presentation I was demonstrating PRQL's composability by first finding the top 5 customers by total spend:
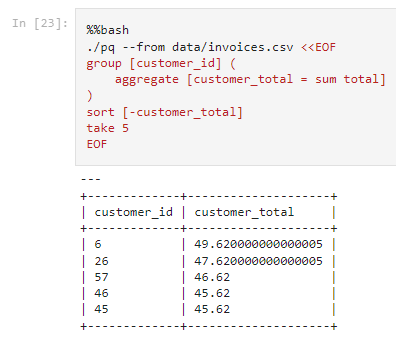
And then I showed how you can turn the customer_id's into names by adding two simple lines (including a join):
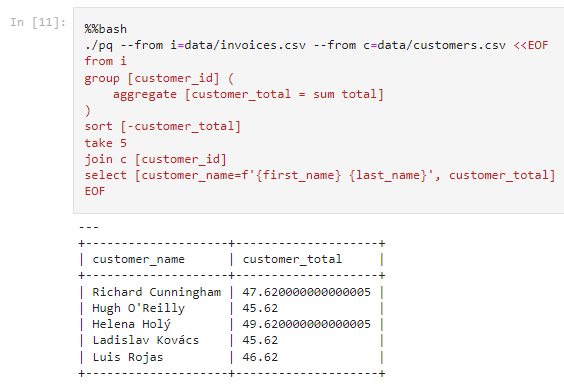
It was only some days later that I noticed that the result set was no longer sorted correctly. It hadn't occurred to me to check for this.
I'm not sure where I'd put my vote yet. Just putting this example here for now to add to the discussion.
Group and window are different here because their core task is to pull the rows apart and then compose them back together.
Totally agree on group but I'm not sure about window. It's quite late here so forgive me if I write nonsense. My understanding of window is that it applies local aggregations in the context of the current row. The ordering of the rows is quite key for that so you would expect that to be preserved.
That does seem to be the case in the current playground:

and

from s"select 5 n union select 2 union select 3 union select 1 union select 4"
sort n
window rolling:2 (
derive [rs = sum n]
)
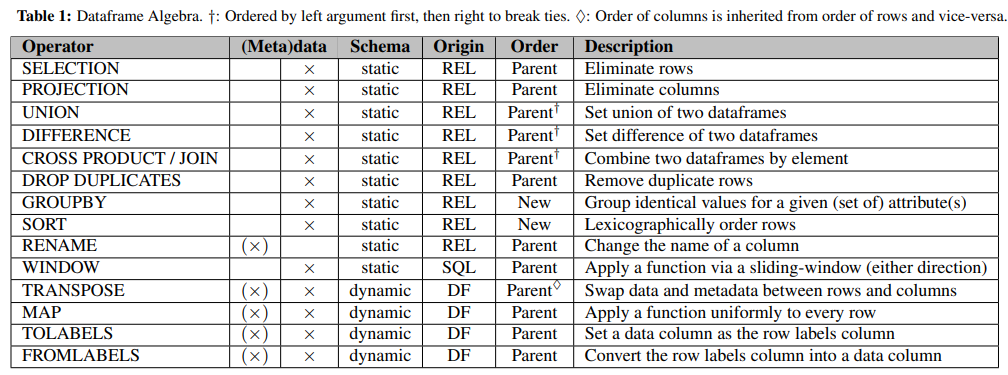
I just found this paper Towards Scalable Dataframe Systems by the Berkely databases group (who I think are also behind modin and ponder.io).
In my opinion the pipelined nature of PRQL makes it quite similar to the DataFrame APIs so we should pay attention to this.
@aljazerzen and @felixge have a look at section 5.2.1 Order is Central which has a good discussion of the challenges of translating dataframe operations to relational algebra due to the ordering implicit in the physical layout of the dataframe data.
Table 1 has a good summary:
As usual, DuckDB does some interesting things in this space:
See https://discord.com/channels/909674491309850675/1032659480539824208/1043293262393389108
By default DuckDB maintains insertion order and guarantees that LIMIT 5 returns the first 5 rows
and https://discord.com/channels/909674491309850675/1032659480539824208/1045440009416757368

They're also working on a SORTED Constraint Feature. When this feature lands it would be great if we could have specialisation in the DuckDB target that takes advantage of this.