TensorRT
 TensorRT copied to clipboard
TensorRT copied to clipboard
Inconsistent failures during conversion of QAT onnx model to TRT
Description
I used the pytorch_quantization toolkit to convert the Conv2d layers in a fully convolutional network (source model here) to int8 and was able to successfully export the model to ONNX. When I attempt to convert the model to a trt engine while leaving all quantized Conv2d layers enabled, I get the following error at layer basenet.slice1.10:
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [E] 10: [optimizer.cpp::computeCosts::3626] Error Code 10: Internal Error (Could not find any implementation for node basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46.)
[12/08/2022-21:54:08] [TRT] [E] 2: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
A longer snippet of the logs shows that it was able to successfully convert earlier quantized Conv2d layers (basenet.slice.1.7 shown here) before failing:
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(2359296,147456:4,288,1) -> Int8(4718592,147456:4,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CudaDepthwiseConvolution)
[12/08/2022-21:54:08] [TRT] [V] CudaDepthwiseConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (FusedConvActConvolution)
[12/08/2022-21:54:08] [TRT] [V] FusedConvActConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(2359296,147456:4,288,1) -> Int8(589824,147456:32,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(294912,147456:32,288,1) -> Int8(589824,147456:32,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CudaGroupConvolution)
[12/08/2022-21:54:08] [TRT] [V] CudaGroupConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CudaDepthwiseConvolution)
[12/08/2022-21:54:08] [TRT] [V] CudaDepthwiseConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (FusedConvActConvolution)
[12/08/2022-21:54:08] [TRT] [V] FusedConvActConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x128x64_stage1_warpsize4x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x0405e3a763219823
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x0405e3a763219823 Time: 0.311957
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x128x64_stage1_warpsize2x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x09727a53770225e8
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x09727a53770225e8 Time: 0.335883
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x32x64_stage1_warpsize2x1x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x13463e9bf9ae0d73
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x13463e9bf9ae0d73 Time: 0.557707
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x128x64_stage1_warpsize2x2x1_g1_tensor8x8x16 Tactic: 0x1d9b1bf0b28cc357
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x1d9b1bf0b28cc357 Time: 0.279893
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize32x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16 Tactic: 0x23cd610b930e6789
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x23cd610b930e6789 Time: 0.654432
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x128x64_stage1_warpsize2x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x3a7df5a005634aca
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x3a7df5a005634aca Time: 0.276848
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize32x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x3cda2ee55a7d0cc2
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x3cda2ee55a7d0cc2 Time: 0.655232
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x256x64_stage1_warpsize2x4x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x446f06d5a2e0bae3
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x446f06d5a2e0bae3 Time: 0.561131
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize32x32x64_stage1_warpsize2x1x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x4e4c4bf050b40a1b
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x4e4c4bf050b40a1b Time: 0.836875
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize32x32x64_stage1_warpsize2x1x1_g1_tensor8x8x16 Tactic: 0x58be15b6f024df52
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x58be15b6f024df52 Time: 0.847189
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x61d05b8ef3670baa
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x61d05b8ef3670baa Time: 0.450656
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16 Tactic: 0x81994a658cdf908d
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x81994a658cdf908d Time: 0.452651
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x128x64_stage1_warpsize4x2x1_g1_tensor8x8x16 Tactic: 0x85047b8e34ed27fa
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x85047b8e34ed27fa Time: 0.343371
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x64x64_stage1_warpsize4x1x1_g1_tensor8x8x16_t1r3s3 Tactic: 0x8a60cb2150513f2e
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0x8a60cb2150513f2e Time: 0.340192
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16_t1r3s3 Tactic: 0xa792e2a2dcc5e78f
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xa792e2a2dcc5e78f Time: 0.367264
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize256x64x64_stage1_warpsize4x1x1_g1_tensor8x8x16 Tactic: 0xb81aeaba4cbc0d97
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xb81aeaba4cbc0d97 Time: 0.338603
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x128x64_stage1_warpsize2x2x1_g1_tensor8x8x16 Tactic: 0xdd517393a24bd0f4
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xdd517393a24bd0f4 Time: 0.381312
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x64x64_stage1_warpsize2x2x1_g1_tensor8x8x16 Tactic: 0xdfb027065697c23b
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xdfb027065697c23b Time: 0.392992
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize64x32x64_stage1_warpsize2x1x1_g1_tensor8x8x16 Tactic: 0xfaea3ed8eff52856
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xfaea3ed8eff52856 Time: 0.636875
[12/08/2022-21:54:08] [TRT] [V] basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 Set Tactic Name: sm75_xmma_fprop_implicit_gemm_interleaved_i8i8_i8i32_f32_nchw_vect_c_32kcrs_vect_c_32_nchw_vect_c_32_tilesize128x256x64_stage1_warpsize2x4x1_g1_tensor8x8x16 Tactic: 0xfb1f0c938b867bc9
[12/08/2022-21:54:08] [TRT] [V] Tactic: 0xfb1f0c938b867bc9 Time: 0.666251
[12/08/2022-21:54:08] [TRT] [V] Fastest Tactic: 0x3a7df5a005634aca Time: 0.276848
[12/08/2022-21:54:08] [TRT] [V] >>>>>>>>>>>>>>> Chose Runner Type: CaskConvolution Tactic: 0x3a7df5a005634aca
[12/08/2022-21:54:08] [TRT] [V] =============== Computing costs for
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(4718592,147456:4,288,1) -> Float(18874368,147456,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CudaDepthwiseConvolution)
[12/08/2022-21:54:08] [TRT] [V] CudaDepthwiseConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(589824,147456:32,288,1) -> Float(18874368,147456,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(589824,147456:32,288,1) -> Float(589824,147456:32,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [V] *************** Autotuning format combination: Int8(589824,147456:32,288,1) -> Half(589824,147456:32,288,1) ***************
[12/08/2022-21:54:08] [TRT] [V] --------------- Timing Runner: basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46 (CaskConvolution)
[12/08/2022-21:54:08] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:54:08] [TRT] [E] 10: [optimizer.cpp::computeCosts::3626] Error Code 10: Internal Error (Could not find any implementation for node basenet.slice1.10.weight + QuantizeLinear_44 + Conv_46.)
[12/08/2022-21:54:08] [TRT] [E] 2: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
When I disable the quantized Conv2d layer "basenet.slice1.10", however, the conversion still fails and instead can't find an implementation for the node "basenet.slice1.7" now. It also seems to explore less tacics:
[12/08/2022-21:51:58] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CudaDepthwiseConvolution)
[12/08/2022-21:51:58] [TRT] [V] CudaDepthwiseConvolution has no valid tactics for this config, skipping
[12/08/2022-21:51:58] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:51:58] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:51:58] [TRT] [V] *************** Autotuning format combination: Int8(294912,147456:32,288,1) -> Float(18874368,147456,288,1) ***************
[12/08/2022-21:51:58] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:51:58] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:51:58] [TRT] [V] *************** Autotuning format combination: Int8(294912,147456:32,288,1) -> Float(589824,147456:32,288,1) ***************
[12/08/2022-21:51:58] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:51:58] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:51:58] [TRT] [V] *************** Autotuning format combination: Int8(294912,147456:32,288,1) -> Half(589824,147456:32,288,1) ***************
[12/08/2022-21:51:58] [TRT] [V] --------------- Timing Runner: basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34 (CaskConvolution)
[12/08/2022-21:51:58] [TRT] [V] CaskConvolution has no valid tactics for this config, skipping
[12/08/2022-21:51:59] [TRT] [E] 10: [optimizer.cpp::computeCosts::3626] Error Code 10: Internal Error (Could not find any implementation for node basenet.slice1.7.weight + QuantizeLinear_32 + Conv_34.)
[12/08/2022-21:51:59] [TRT] [E] 2: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
What I've tried to do:
- I validated that the model can be successfully converted from pytorch->ONNX->TRT without quantized layers
- I attempted to replicate the conversion process on an ampere A10 GPU, increased workspace size, and reduced height and width dimensions of inputs per suggestions in https://github.com/NVIDIA/TensorRT/issues/1768
- Tried to convert within the docker container nvcr.io/nvidia/tensorrt:22.07-py3 per the suggestion in https://github.com/NVIDIA/TensorRT/issues/2240
- Tried to build the engine without "OBEY_PRECISION_CONSTRAINTS" or "PREFER_PRECISION_CONSTRAINTS" builder flags
I see the same errors with despite these modifications. I can also successfully perform inference with my quantized model, though there is some performance difference compared to the quantized pytorch model, not sure if that could be related. Is there something obvious I'm missing in the logs, or a known way to remedy this issue?
Environment
TensorRT Version: 8.4.2.1 NVIDIA GPU: T4 NVIDIA Driver Version: 510.47.03 CUDA Version: 11.5 CUDNN Version: 8.4 Operating System: ubuntu 20.04 Python Version (if applicable): 3.9 Tensorflow Version (if applicable): PyTorch Version (if applicable): 1.11.0 Baremetal or Container (if so, version):
Relevant Files
A zip file with the quantized onnx model I'm attempting to convert can be downloaded here: https://drive.google.com/file/d/1PfO7JWONrX4JHMxCCjxmr6-f4tNbUW5g/view
I originally attempted to convert the ONNX model to TRT using the python API which failed consistently, however I was able to successfully convert the engine using trtexec in the docker container using the command below:
trtexec \
--onnx=craft_int8.onnx \
--saveEngine=/workspace/craft_int8.plan \
--fp16 \
--int8 \
--workspace=8589934592 \
--minShapes=\'input\':1x3x1280x736 \
--optShapes=\'input\':1x3x1280x736 \
--maxShapes=\'input\':1x3x1280x736 \
--verbose \
--profilingVerbosity=detailed \
--useCudaGraph \
--precisionConstraints="prefer"
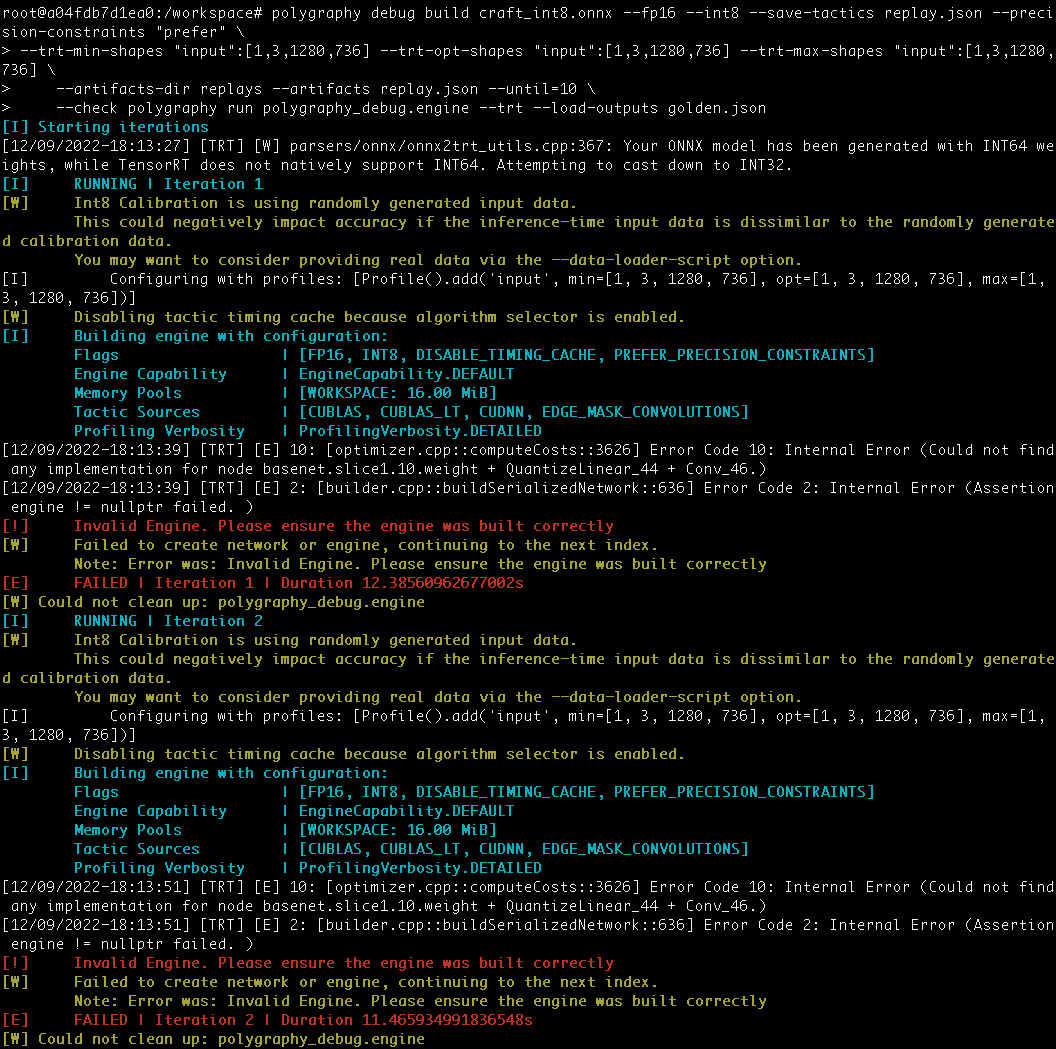
I checked the performance of the resulting engine and it had significantly degraded compared to the original quantized model. I attempted to use polygraphy (within the container I built the engine) to debug which tactics caused the performance drops and it was unable to build the engine at each iteration, showing the same error I reported above:
Very good bug description! Thanks!
Have you tried the latest TensorRT Release? should be 8.5.1.7. or 8.5.2. Can you try it first? if it still now work then should be a TRT bug. I will help create an internal bug to track this. Thanks!
Hey @zerollzeng, I updated to 8.5.1.7 and am now getting a new error when running both the python API and executing trtexec within the most recent docker container:
[12/12/2022-05:44:30] [TRT] [E] 2: [optimizer.cpp::filterQDQFormats::4422] Error Code 2: Internal Error (Assertion !n->candidateRequirements.empty() failed. All of the candidates were removed, which points to the node being incorrectly marked as an int8 node.)
I'm attaching a full print out of the logs here: fail_logs_python_8517.txt. It looks like the QDQ nodes are being fused differently than before, but then it fails before testing different tactics because some of the nodes are removed (if I'm reading it correctly).
The model converts successfully if I change the precision constraint flag from "obey" to "prefer", but that seems to throw out some of the quantization? I need to reattempt additional probing with polygraphy to better understand how much. Is this expected behavior in the most recent release for quantized conv2d -> BN -> ReLU layers?
@zerollzeng as a sanity check, I converted the full precision model again using tensorrt 8.5.1.7 while keeping the TRT engine in FP32, and the performance degrades quite a bit now. The performance was nearly identical when using tensorrt 8.4.2.1. I checked the release notes and didn't see anything obvious that would contribute to the change, do you have an idea of what would cause this in the new release?
I feel like there is some incorrect QDQ nodes in you model, but I'm not an expert about it. @ttyio can you help here? thanks!
@c-schumacher what's the full command you are using in the fail_logs_python_8517.txt?
@zerollzeng I used the "build_engine" convenience function from the transformer deploy repo (see here for reference) to convert from onnx since it has worked well for converting other models including the full precision CRAFT model. I experimented with a few tweaks to it as well, doing things like adjusting tactic sources, changing the precision constraints flag from "obey" to "prefer" (which seems to work inside the docker container), etc. But it has consistently failed with the quantized CRAFT model despite that, which is why I'm wondering if there is something slightly off in my environment.
I have similar problem with TensorRT 8.6.2
$ trtexec --onnx=best.onnx --verbose
...............
02/08/2024-12:48:09] [V] [TRT] *************** Autotuning format combination: Float(), Float(1) -> Float(1) ***************
[02/08/2024-12:48:09] [V] [TRT] --------------- Timing Runner: /0/model.33/Range (Fill[0x80000026])
[02/08/2024-12:48:09] [V] [TRT] Skipping tactic 0x0000000000000000 due to exception cudaEventElapsedTime
[02/08/2024-12:48:09] [V] [TRT] /0/model.33/Range (Fill[0x80000026]) profiling completed in 0.0026857 seconds. Fastest Tactic: 0xd15ea5edd15ea5ed Time: inf
[02/08/2024-12:48:09] [V] [TRT] Deleting timing cache: 342 entries, served 1108 hits since creation.
[02/08/2024-12:48:10] [E] Error[10]: Could not find any implementation for node /0/model.33/Range.
[02/08/2024-12:48:10] [E] Error[10]: [optimizer.cpp::computeCosts::3869] Error Code 10: Internal Error (Could not find any implementation for node /0/model.33/Range.)
[02/08/2024-12:48:10] [E] Engine could not be created from network
[02/08/2024-12:48:10] [E] Building engine failed
[02/08/2024-12:48:10] [E] Failed to create engine from model or file.
[02/08/2024-12:48:10] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8602] # trtexec --onnx=best.onnx --verbose
I have this problem with Docker image nvcr.io/nvidia/deepstream:6.4-triton-multiarch on Jetson (generating model on the same image, but on x86 machine works well)
@zerollzeng Do you have any advices?
I have full reproduction steps (in Docker on Jetson) described here: https://github.com/marcoslucianops/DeepStream-Yolo/issues/511
Could you please try TRT 9.2/9.3 on x86? Since we don't have such release for jetson. I want to know whether it's a fixed issue.
Could you please try TRT 9.2/9.3 on x86? Since we don't have such release for jetson. I want to know whether it's a fixed issue.
Hello, I can confirm this problem on our Jetson NX Orin 16 with Jetpack 6.0. We are currently using another Jetson of the same model with 5.1.3 and engine builds successfully, however with a newer TRT version we are facing the problem @pktiuk has mentioned. The onnx model in both cases was the same of course.
@zerollzeng
Please check my link to full reproduction steps. There is everything.
File internal bug 4536722 for this as I saw similar error on yolov8. @pktiuk could you please share your onnx model here? I tried to follow your reproduce but fails to export the onnx.
I think one WAR that worth to try is try to export without--dynamic. maybe it will eliminate the range op.
Hello @zerollzeng,
This is the .onnx file I got:
yolov5s_dynamic.zip
(result of command: python3 export_yoloV5.py -w yolov5s.pt --dynamic)
I tried to follow your reproduce but fails to export the onnx.
What is your configuration? Which jetson and jetpack did you use?
I think one WAR that worth to try is try to export without--dynamic. maybe it will eliminate the range op.
It did not help. :(
Looks like you hit another failed node, could you please try export the model with static shape and do a onnx-simplify on it(not sure whether it will work but worth a try since we are still checking this)
@zerollzeng
Used python3 export_yoloV5.py -w yolov5s.pt --simplify
And got:
WARNING: [TRT]: Tensor DataType is determined at build time for tensors not marked as input or output.
Building the TensorRT Engine
ERROR: [TRT]: 2: Impossible to reformat.
ERROR: [TRT]: 2: [optimizer.cpp::computeCosts::4194] Error Code 2: Internal Error (Impossible to reformat.)
Building engine failed
Failed to build CUDA engine
This is a cuda driver bug in Jetson and we fixed it in our latest internal code, should be come with the next release(probably GA ). closed this.
@zerollzeng
Could you let us know when a new release with this fix will be available?