torchmetrics
 torchmetrics copied to clipboard
torchmetrics copied to clipboard
FBeta binary average
🚀 Feature
Have fbeta binary metric following sklearn
Motivation
This is used and is the default in sklearn. It can be misleading if people use it without thinking.
Code example
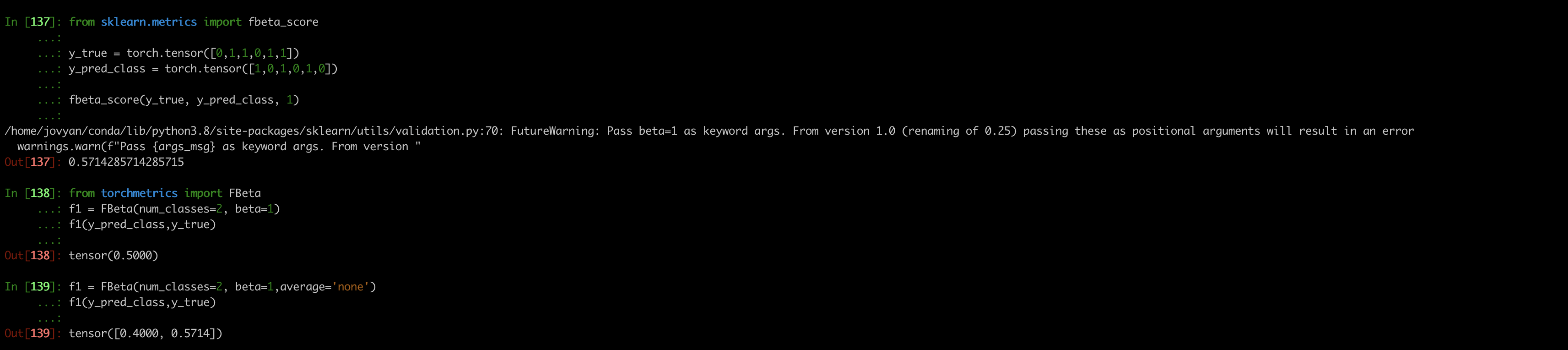
from sklearn.metrics import fbeta_score
y_true = torch.tensor([0,1,1,0,1,1])
y_pred_class = torch.tensor([1,0,1,0,1,0])
fbeta_score(y_true, y_pred_class, 1)
from torchmetrics import FBeta
f1 = FBeta(num_classes=2, beta=1)
f1(y_pred_class,y_true)
f1 = FBeta(num_classes=2, beta=1,average='none')
f1(y_pred_class,y_true)
You are right that the binary case of some of the classification metrics are not handle in a ideal way. Any suggestions what we could do to improve?
Well sklearn binary = FBeta(num_classes=2, beta,average='none')[1] So we could do a quick PR where we put the average by default to be binary the same way it is for sklearn and in the code just do average='none' and display only the positive one.
hi I can help with this issue
Sure, just let me know which you want to take first...
hi,
I did some changes
and my test code is
from torchmetrics import FBeta
from sklearn.metrics import fbeta_score
import torch
y_true = torch.tensor([0, 1, 1, 0, 1, 1])
y_pred_class = torch.tensor([1, 0, 1, 0, 1, 0])
print(fbeta_score(y_true, y_pred_class, 1))
f1 = FBeta(num_classes=2, beta=1)
print(f1(y_pred_class, y_true))
f1 = FBeta(num_classes=2, beta=1, average='micro')
print(f1(y_pred_class, y_true))
output
0.5714285714285715
tensor(0.5714)
tensor(0.5000)
I agree that this could be quite misleading for the default to diverge from sklearn (which I assume is most ppl are used to).
Issue will be fixed by classification refactor: see this issue https://github.com/Lightning-AI/metrics/issues/1001 and this PR https://github.com/Lightning-AI/metrics/pull/1195 for all changes
Small recap: This issue describe that metric FBeta metric is not the same as sklearn in the binary setting. The problem with the current implementation is that the metrics are calculated as average over the 0 and 1 class, which is wrong. After the refactor, using new the bineary_fbeta_score give the same result as sklearn:
from torchmetrics.functional import binary_fbeta_score
from sklearn.metrics import fbeta_score
import torch
preds = torch.rand(10)
target = torch.randint(0, 2, (10,))
print(binary_fbeta_score(preds, target, beta=2.0) == fbeta_score(target, preds.round(), beta=2.0)) # True
sorry for the confusion this has created. Issue will be closed when https://github.com/Lightning-AI/metrics/pull/1195 is merged.