YOLOv3-model-pruning
 YOLOv3-model-pruning copied to clipboard
YOLOv3-model-pruning copied to clipboard
训练得到的mAP低
我按照博主的方法一步步操作,但是训练baseline_model时在训练迭代3,4个epoch时达到过0.73左右,但是在迭代100个epoch后,mAP只有0.69左右。请问您是怎么训练的,我为什么会出现这种情况?

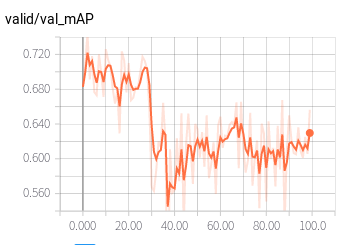
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
你是和自己的剪枝模型和训练的baseline对比了吗?感觉自己的剪了也没有变多快,设的0.48,弄不明白
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
你是和自己的剪枝模型和训练的baseline对比了吗?感觉自己的剪了也没有变多快,设的0.48,弄不明白
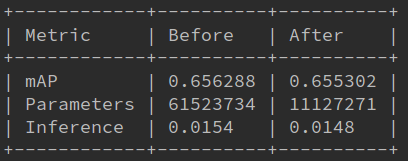
用的作者的代码 ratio=0.85 采用final模型 裁剪11369/13376 层 剪枝前后对比如下:
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
你是和自己的剪枝模型和训练的baseline对比了吗?感觉自己的剪了也没有变多快,设的0.48,弄不明白
用的作者的代码 ratio=0.85 采用final模型 裁剪11369/13376 层 剪枝前后对比如下:
差不多的情况,但是我没有稀疏化好,只能最大设成0.48,剪完精度就掉0了。你是怎么稀疏的呀,有没有修改什么参数呢,用了多少个epoch呀
| mAP | 0.743434 | 0.000000 | | Parameters | 61523734 | 35518315 | | Inference | 0.0104 | 0.0095 |
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
你是和自己的剪枝模型和训练的baseline对比了吗?感觉自己的剪了也没有变多快,设的0.48,弄不明白
用的作者的代码 ratio=0.85 采用final模型 裁剪11369/13376 层 剪枝前后对比如下:
差不多的情况,但是我没有稀疏化好,只能最大设成0.48,剪完精度就掉0了。你是怎么稀疏的呀,有没有修改什么参数呢,用了多少个epoch呀
| mAP | 0.743434 | 0.000000 | | Parameters | 61523734 | 35518315 | | Inference | 0.0104 | 0.0095 |
python train.py --model_def config/yolov3-hand.cfg -sr --s 0.01 什么参数都没改 用最后一个保存的模型测试的 稀疏化训练和裁剪都没问题 主要是模型精度 估计需要衰减学习率
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值)
请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊
对 我用的TitanXp 时间少的不多
你是和自己的剪枝模型和训练的baseline对比了吗?感觉自己的剪了也没有变多快,设的0.48,弄不明白
用的作者的代码 ratio=0.85 采用final模型 裁剪11369/13376 层 剪枝前后对比如下:
差不多的情况,但是我没有稀疏化好,只能最大设成0.48,剪完精度就掉0了。你是怎么稀疏的呀,有没有修改什么参数呢,用了多少个epoch呀
| mAP | 0.743434 | 0.000000 | | Parameters | 61523734 | 35518315 | | Inference | 0.0104 | 0.0095 |
你是在自己的数据集上做的剪枝麽,我percent最大只能设置到0.35,剪枝后也是0了,肿么破,请大佬赐教
代码里的默认超参可能不是最好的(mAP最高0.72),多调多试一下。
Detecting objects: 100%|██████████| 103/103 [00:18<00:00, 5.53it/s] Computing AP: 100%|██████████| 1/1 [00:00<00:00, 14.89it/s] Average Precisions:
- Class '0' (hand) - AP: 0.8698023980235626 mAP: 0.8698023980235626
ps:没有改动训练方式。
代码里的默认超参可能不是最好的(mAP最高0.72),多调多试一下。
Detecting objects: 100%|██████████| 103/103 [00:18<00:00, 5.53it/s] Computing AP: 100%|██████████| 1/1 [00:00<00:00, 14.89it/s] Average Precisions:
- Class '0' (hand) - AP: 0.8698023980235626 mAP: 0.8698023980235626
ps:没有改动训练方式。
请问是怎么调参的呢?