JuliaSyntax.jl
 JuliaSyntax.jl copied to clipboard
JuliaSyntax.jl copied to clipboard
Prime parsing issues
Bunch of nasty edge cases related to symbols followed by primes:
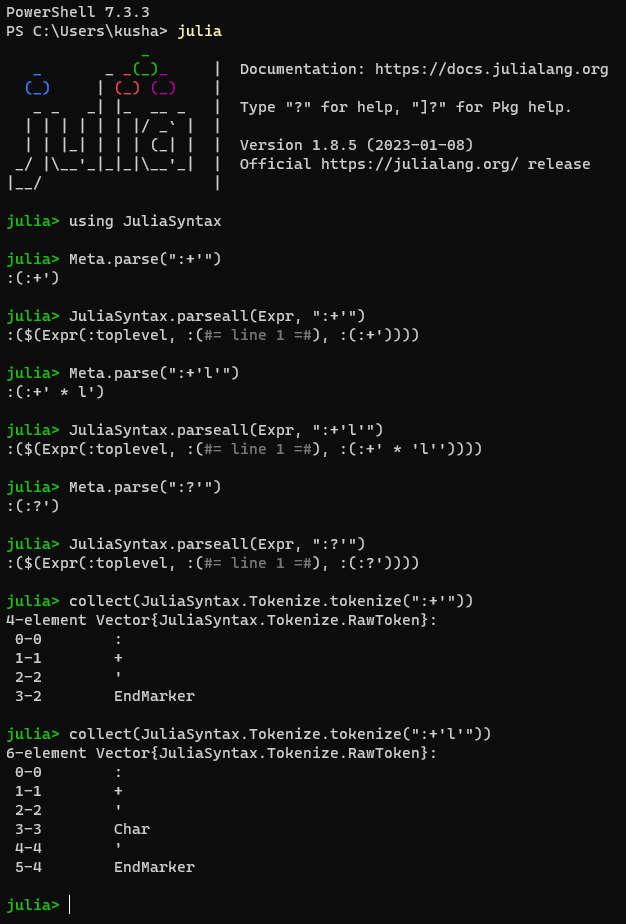
julia> Meta.parse(":+'")
:(:+')
julia> JuliaSyntax.parseall(Expr, ":+'")
ERROR: ParseError:
Error: extra tokens after end of expression
@ line 1:3
:+'
julia> Meta.parse(":+'l'")
:(:+' * l')
julia> JuliaSyntax.parseall(Expr, ":+'l'")
ERROR: ParseError:
Error: extra tokens after end of expression
@ line 1:3
:+'l'
julia> Meta.parse(":?'")
:(:?')
julia> JuliaSyntax.parseall(Expr, ":?'")
ERROR: ParseError:
Error: extra tokens after end of expression
@ line 1:3
:?'
Tokenization of postfix ' is context-dependent so I bet this is a tokenization error. Let's see...
julia> collect(JuliaSyntax.Tokenize.tokenize(":+'"))
4-element Vector{JuliaSyntax.Tokenize.Tokens.Token}:
0-0 OP
1-1 OP
2-2 ERROR
3-2 ENDMARKER
julia> collect(JuliaSyntax.Tokenize.tokenize(":+'l'"))
4-element Vector{JuliaSyntax.Tokenize.Tokens.Token}:
0-0 OP
1-1 OP
2-4 CHAR
5-4 ENDMARKER
Yeah that's it — the tokens are incorrect here. It looks like the disambiguation rule used in Tokenize.jl isn't sufficient for this case.
And no wonder, these examples are very clever (/horrifying/entertaining) edge cases. Thanks for the bug report!!
Good to see that the more straightforward cases here have been solved somewhere along the way. (A couple of tests for that would be a nice PR ;-) )
However, the second case isn't resolved:
julia> JuliaSyntax.fl_parse(Expr, ":+'y'")
:(:+' * y')
julia> JuliaSyntax.parsex(Expr, ":+'y'")
:(:+' * 'y'')
The problem there is that tokenization is context-dependent in the Julia reference parser.
In practice this is a behavior that no package in the General registry depends on, that I'm aware of. So it hasn't been a high priority to fix.
To be honest I'd been kind of wondering whether we even needed to fix it. Context-dependent tokenization is extremely awkward and "should not be encouraged" haha. We'd either need to add more state to the Lexer, or add some flags to next_token() to be provided by the parser. Probably the latter is a better option in, but it invalidates the token read-ahead cache so that's annoying.