almanac.httparchive.org
 almanac.httparchive.org copied to clipboard
almanac.httparchive.org copied to clipboard
Compression 2022
Compression 2022
If you're interested in contributing to the Compression chapter of the 2022 Web Almanac, please reply to this issue and indicate which role or roles best fit your interest and availability: author, reviewer, analyst, and/or editor.
Content team
| Lead | Authors | Reviewers | Analysts | Editors | Coordinator |
|---|---|---|---|---|---|
| @eustas | @eustas @jyrkialakuijala | @mo271 | @paulcalvano | - | @paulcalvano |
Expand for more information about each role 👀
- The content team lead is the chapter owner and responsible for setting the scope of the chapter and managing contributors' day-to-day progress.
- Authors are subject matter experts and lead the content direction for each chapter. Chapters typically have one or two authors. Authors are responsible for planning the outline of the chapter, analyzing stats and trends, and writing the annual report.
- Reviewers are also subject matter experts and assist authors with technical reviews during the planning, analyzing, and writing phases.
- Analysts are responsible for researching the stats and trends used throughout the Almanac. Analysts work closely with authors and reviewers during the planning phase to give direction on the types of stats that are possible from the dataset, and during the analyzing/writing phases to ensure that the stats are used correctly.
- Editors are technical writers who have a penchant for both technical and non-technical content correctness. Editors have a mastery of the English language and work closely with authors to help wordsmith content and ensure that everything fits together as a cohesive unit.
- The section coordinator is the overall owner for all chapters within a section like "User Experience" or "Page Content" and helps to keep each chapter on schedule.
Note: The time commitment for each role varies by the chapter's scope and complexity as well as the number of contributors.
For an overview of how the roles work together at each phase of the project, see the Chapter Lifecycle doc.
Milestone checklist
0. Form the content team
- [x] May 1: The content team has at least one author, reviewer, and analyst
1. Plan content
- [x] May 15 The content team has completed the chapter outline in the draft doc
2. Gather data
- [x] June 1: Analysts have added all necessary custom metrics and drafted a PR (example) to track query progress
- June 1 - 15: HTTP Archive runs the June crawl
3. Validate results
- [x] August 1: Analysts have queried all metrics and saved the output to the results sheet
4. Draft content
- [ ] September 1: The content team has written, reviewed, and edited the chapter in the doc
5. Publication
- [ ] September 15: The completed chapter and all required metadata and figures are converted to markdown and submitted to GitHub
- September 26: Target launch date 🚀
Chapter resources
Refer to these 2022 Compression resources throughout the content creation process:
📄 Google Docs for outlining and drafting content 🔍 SQL files for committing the queries used during analysis 📊 Google Sheets for saving the results of queries 📝 Markdown file for publishing content and managing public metadata 💬 #web-almanac-compression on Slack for team coordination
Update: @eustas is interested in being the lead author for this chapter, with @jyrkialakuijala coauthoring.
Thanks @eustas @jyrkialakuijala @mo271! Great to have you all back for the Compression chapter this year!
We're still looking for an analyst and ideally we would have had a fully formed content team by yesterday to stay on schedule. @paulcalvano would you be interested to help with that again?
Meanwhile, you all should have edit access to the chapter planning doc. Please start outlining the contents for this year's chapter, starting with the 2021 outline as needed. The goal is to have the outline completed by May 15.
Thanks again and looking forward to seeing the content starting to come together!
@eustas @jyrkialakuijala @mo271 would any of you be interested in doing the analysis this year? Also as a reminder, please start adding topics to include in this year's chapter to the doc. What's new with compression, or what would be good to revisit from previous years? We're hoping to have the outline completed by May 15 to stay on schedule. Thanks for your help!
We're still looking for an analyst and ideally we would have had a fully formed content team by yesterday to stay on schedule. @paulcalvano would you be interested to help with that again?
Sorry - just saw this. If no-one else is interested doing the analysis, then I'm happy take this one again.
Hey all, can I raise a bug bear of mine?
These graphs have always annoyed me:
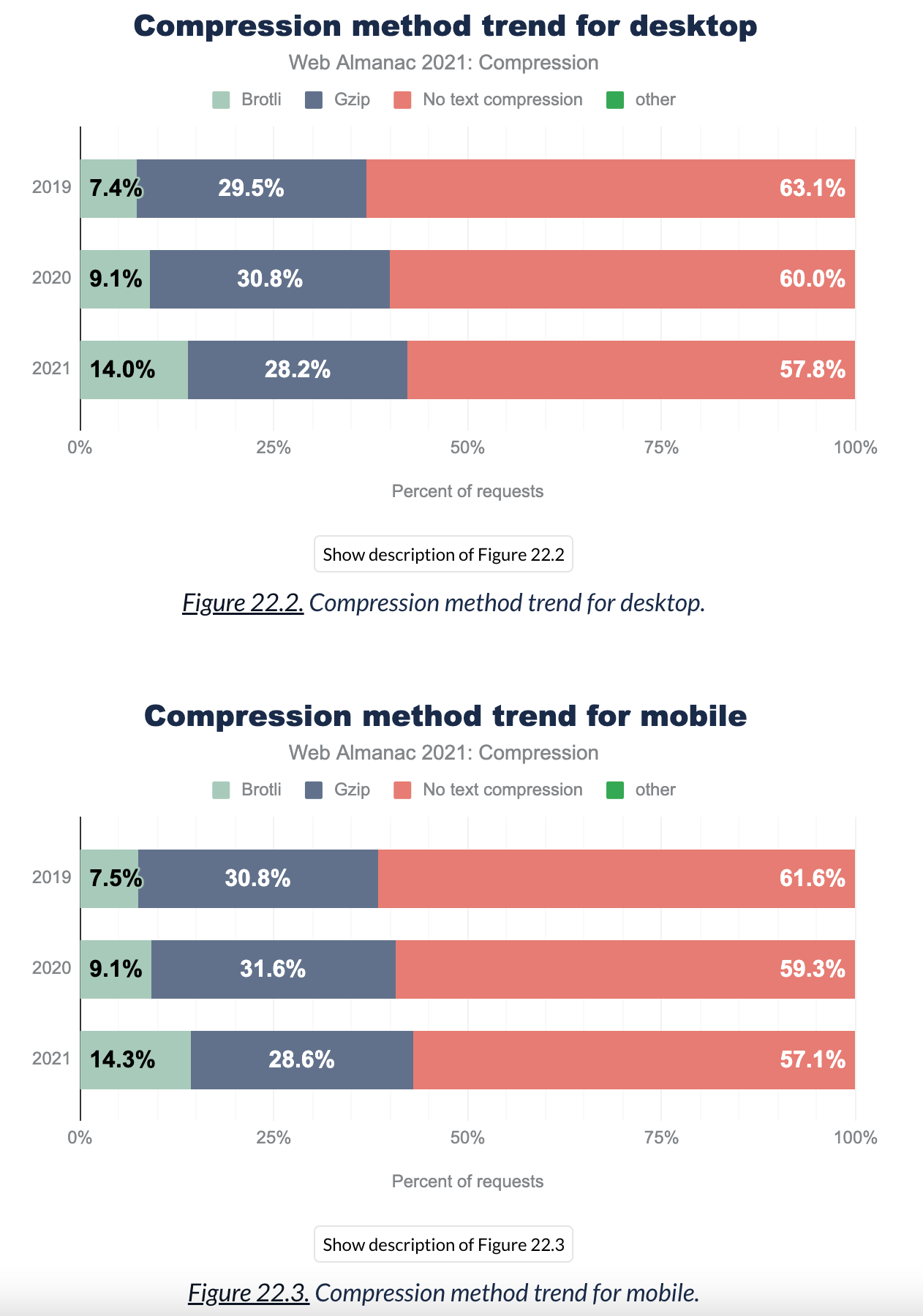
This includes ALL requests - including requests that SHOULD NOT be text-compressed (e.g. images, fonts, video...etc.) as the format itself usually includes compression.
This make people think the vast majority of resources are not compressed when they should be (which may not be the case), and also hides how bad the issue of uncompressed text resources is. How many text resources that should be compressed are not? We don't know.
Can we get a more accurate estimate of by only looking at text responses (HTML, JS, CSS, JSON, SVG, TXT... etc.)? Or, alternatively, by excluding formats known to handle compression themselves (JPG, PNG, WOFF...etc.). Probably best to look at response mimetype to do this.
I for one, would be more interested in seeing that, than the current metric. But happy to include both if still want a comparison on previous years.
Not only that. There is another level of applicability: "br" content-encoding is only advertised (and accepted) by a large portion of browsers ONLY over "https" protocol. So, "br" has no chance to be used for requests sent over "http".
True, though with over 91% of requests being served over HTTP last year (which has probably only gone up this year!), I’m not sure that’s as big a deal. It’s potentially a reason Brotli isn’t used, but not an excuse IMHO 😄
@eustas it looks like you've made a lot of progress on the draft, great work! Can you check off Milestone 1 at the top of this issue? I don't think you've accepted the invitation to join the HA team on GitHub yet, so you may need to go to https://github.com/HTTPArchive to accept it before getting edit access.
@paulcalvano how are Milestones 2 and 3 coming along? The analysis is scheduled to be due next week so I want to make sure we're not blocking the authors. I know you've been (still are?) traveling so feel free to reply whenever you get back.
@eustas @jyrkialakuijala. It looks like you started the draft for the chapter in July, but I don't see any updates since the analysis was complete. Can you please incorporate the graphs from the analysis and add any additional content you'd like? Please let me know when the chapter is ready to be reviewed, or if you need any help.
@eustas @jyrkialakuijala we're a few weeks past the deadline to have the chapter fully written, reviewed, and edited, but it doesn't look like much progress has been made beyond the initial content written in July. Unfortunately, it's looking like we won't be able to release it on time and we're going to have to cut this chapter from the report this year.
There may have been a miscommunication about the data analysis. I see that @paulcalvano pinged the Slack channel last month when the results were available in the sheet, but maybe you didn't get the notification. If you think it might still be possible to wrap this chapter up in a couple of weeks, we could try to release it in a secondary launch with a batch of other delayed chapters. Hoping we can find a way to make this work as it's an important chapter and I see a lot of effort has already gone into it.
Either way, thank you for all of your contributions and I'm sorry about the drastic action.