TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10
 TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10 copied to clipboard
TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10 copied to clipboard
Training with model_main.py
This is not an issue, more of a how-to on using model_main.py.
Edje, if you are reading this, I wanted to tell you and anyone reading how to train using model_main.py instead of train.py.
Required applications/libraries: Microsoft VS C++ Build Tools 2015 pycocotools Cython Git Tensorflow 1.14.0*
- Tensorflow 1.13.1 has been known to cause issues with model_main.py; install 1.14.0 to avoid these issues
Tensorflow 2.0 is not compatible as of yet with the Object Detection API; do not use TF 2.0 for training
Step 1: Install Git from here (Choose all default settings) Step 2: Install Microsoft VS C++ Build Tools 2015 from here (Choose all default settings; of note: this is a large installation) Step 3: Install cython with the following pip command: pip install cython Step 4: Install pycocotools with the following pip command: pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI Step 5: Install Tensorflow 1.14.0 For GPU (make sure to set up your environment for this; see the tutorial): pip install tensorflow-gpu==1.14.0 For CPU: pip install tensorflow-cpu==1.14.0
On running model_main.py, it is not much different than running train.py in terms of the cmd command: From the object_detection directory:
python model_main.py --model_dir=training --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config
model_dir is referring to where checkpoints need to be saved (same as train_dir in train.py) pipeline_config_path is the same in both files
You only need to replace your train.py command (keep everything else like setting PYTHONPATH and whatnot).
Of note: From what I have observed, model_main.py actually uses less memory than train.py (In my specific case: average about 14.9 GBs for train.py and 9-10.5 GBs for model_main.py, less CPU as well)
As for the output, model_main.py will output every 100 steps when using faster_rcnn_inception_v2_pets.
Every once in a while, model_main will run an eval on your model. If you look at Tensorboard immediately, you will see a lack of classification_loss graphs, lack of localization_loss graphs, etc. model_main does not output those scalars until after it runs its eval. Eval is ran every 10 minutes with outputs for training every 100 steps.
If you have questions, feel free to ask!
EDIT: Tensorflow 2.x is now supported in the official object detection API; however, I still recommend using Tensorflow 1.x for stability reasons and to keep compatibility with this repository's tutorial (Remember, you are not doing any real programming in this tutorial and there is no real performance difference between 1.x and 2.x; so no need to switch)
Also, you can download the master repository as-is. There is compatibility support for both 1.x and 2.x. However, there is a slight change in the paths for the API installation:
cd models/research
## Compile protos.
protoc object_detection/protos/*.proto --python_out=.
# Install TensorFlow Object Detection API.
cp object_detection/packages/tf1/setup.py .
python -m pip install .
New model-zoo URL: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md Installation tutorial URL: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1.md
Thank man , i will try it , but i found many error as below , is it okay ? i am using TF 1.13.1 CPU here
WARNING:tensorflow:Using temporary folder as model directory: C:\Users\USER\AppD
ata\Local\Temp\tmpc9n7hiv1
WARNING:tensorflow:Estimator's model_fn (<function create_model_fn.<locals>.mode
l_fn at 0x000000001BCF8CA8>) includes params argument, but params are not passed
to Estimator.
WARNING:tensorflow:From C:\Users\USER\AppData\Local\Programs\Python\Python37\lib
\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with
(from tensorflow.python.framework.ops) is deprecated and will be removed in a fu
ture version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:num_readers has been reduced to 1 to match input file shards.
WARNING:tensorflow:From C:\tensorflow1\models\research\object_detection\builders
\dataset_builder.py:86: parallel_interleave (from tensorflow.contrib.data.python
.ops.interleave_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.experimental.parallel_interleave(...)`.
WARNING:tensorflow:From C:\Users\USER\AppData\Local\Programs\Python\Python37\lib
\site-packages\tensorflow\python\ops\image_ops_impl.py:1049: to_float (from tens
orflow.python.ops.math_ops) is deprecated and will be removed in a future versio
n.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From C:\Users\USER\AppData\Local\Programs\Python\Python37\lib
\site-packages\tensorflow\python\ops\image_ops_impl.py:1055: to_int32 (from tens
orflow.python.ops.math_ops) is deprecated and will be removed in a future versio
n.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From C:\tensorflow1\models\research\object_detection\builders
\dataset_builder.py:158: batch_and_drop_remainder (from tensorflow.contrib.data.
python.ops.batching) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.batch(..., drop_remainder=True)`.
WARNING:tensorflow:From C:\Users\USER\AppData\Local\Programs\Python\Python37\lib
\site-packages\tensorflow\contrib\layers\python\layers\layers.py:1624: flatten (
from tensorflow.python.layers.core) is deprecated and will be removed in a futur
e version.
Instructions for updating:
Use keras.layers.flatten instead.
WARNING:tensorflow:From C:\tensorflow1\models\research\object_detection\meta_arc
hitectures\faster_rcnn_meta_arch.py:2766: get_or_create_global_step (from tensor
flow.contrib.framework.python.ops.variables) is deprecated and will be removed i
n a future version.
Instructions for updating:
Please switch to tf.train.get_or_create_global_step
WARNING:tensorflow:From C:\tensorflow1\models\research\object_detection\core\los
ses.py:350: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops
) is deprecated and will be removed in a future version.
Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow
into the labels input on backprop by default.
See `tf.nn.softmax_cross_entropy_with_logits_v2`.
C:\Users\USER\AppData\Local\Programs\Python\Python37\lib\site-packages\tensorflo
w\python\ops\gradients_impl.py:110: UserWarning: Converting sparse IndexedSlices
to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
2019-10-31 09:51:16.703018: I tensorflow/core/platform/cpu_feature_guard.cc:141]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2```
Hi @JulianOrteil , thanks for providing this information, it's very useful!
The main reason I haven't changed the instructions to use model_main.py is that it requires the extra steps to install pycocotools, as you listed. I feel like this process is already complicated enough as it is, so I don't want to add even more steps. I also don't like that it doesn't immediately show any activity in the console - I'm sure that will make people confused about whether it's actually working or not.
Having said that, I didn't realize it had a performance improvement. Does the decrease from 14.9GBs to 9-10.5GBs mean that the models will train more quickly?
Thanks again!
@kirlein84
Those aren't errors, but warnings saying 'Hey, we just want to let you know that we encountered issues while setting up the training environment and parameters, but we can work through them no problem'. You'll have those deprecation outputs no matter what version of Tensorflow 1.x you use because Tensorflow 2.0 has been released. However, the Tensorflow authors have not yet released an object detection api that is compatible with Tensorflow 2.0.
@EdjeElectronics Of course, no problem! I just want to point out that I haven't tried model_main.py on any model except for Faster RCNN. And no worries about not using model_main.py; the install instructions should work for both installing straight into a user-based Python environment (no conda) and a conda environment if you change your mind.
As for RAM, I believe there is a slight improvement. I was getting about 34 seconds per 100 steps when using model_main.py as compared to about 40 seconds per 100 steps when using train.py. However, evaluation does take a little bit of time as training does pause for that, so overall it may take a little longer. You do get better metrics as to how the model is performing though, so it is a trade-off that you will have to consider.
@EdjeElectronics
Model_main actually does output immediately after training is started. It'll output the starting (step 0) loss for Tensorboard. After about (in my case) 35 seconds, it'll output the loss for step 100 of training.
Also, in Tensorboard (TF v1.15), you can actually view the model's predictions on 10 random images after the evaluation is done as you can see below if you use model_main.py. You'll have to enable the tab by clicking on "INACTIVE" and choosing "Images" from the drop down list
(Model's prediction to the left, groundtruth--or what you annotated--to the right)


When I try this I get an error saying that there is no module named 'absl' when I do have that module when I use "model_main.py --model_dir=training --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config"
and when using "python model_main.py --model_dir=training --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config" the program locks up after it uccessfully opened CUDA library cublas64_100.dll locally. Am I doing something wrong or missing something?
Sorry, updated the post. You do need to use 'python' in front of 'model_main.py'. My apologies.
What is your environment for python, Tensorflow version, CUDA version, and cuDNN version? Can you send a screenshot of where the program is locking up?
I'm using an anaconda environment on python 3.6.9, tensorflow-gpu 1.13.1, cuda 10.0, cuDNN 7.6.0

Hm, that is quite interesting; I haven't encountered that one before. I do see a few instances of this error (ArithmeticOptimizer failing to load) with only TF 1.13.1. Try installing Tensorflow-gpu 1.14.0 (fix from these issues):
https://github.com/tensorflow/tensorflow/issues/29052 https://github.com/tensorflow/tensorrt/issues/62
Install command (from the conda env): pip install tensorflow-gpu==1.14.0
Hey there, I had similiar issue while using train.py . My training hangs on random step : like below
 So , I've tried with model_main.py. the result was like my friend above - had same issue, training stuck on cublas64_dll line.
Then I've decided to upgrade tensorflow as u posted to 1.14
Still something is wrong.
So , I've tried with model_main.py. the result was like my friend above - had same issue, training stuck on cublas64_dll line.
Then I've decided to upgrade tensorflow as u posted to 1.14
Still something is wrong.
 Do you guys have any advice ?
Do you guys have any advice ?

@Clouxie
For your first screenshot, I believe that issue is caused by 'gast'. I believe you need to install gast 0.2.2
Run: pip install gast==0.2.2
As for your second screenshot, training actually did not quit; it was still running. Model_main outputs differently than train.py (see Edje's concern above). Model_main will output a training step every 100 steps. Depending on your hardware and training configuration, it may take some time to see anything from Tensorflow. (For example, training for me takes ~35 seconds to see any output; but that is because I am only running one image through for each batch because they are so large).
Fire up Tensorboard and you will also see a lack of a couple of graphs as compared to train.py. Just let TF run for a little while and you'll see output from the training and more graphs in Tensorboard.
Okey then, for The First screenshot i'll try you Solution at the evening. Im not sure about second one, I could wait for even 30min with that state, even tho training folder still stayed empty. The same results are one with playing cards dataset, and my own, a little bigger.
pip install gast==0.2.2 solved problem --- Previously i had version > 0.3 , i believe its not compatible with TF < 2.0
Hmm, I though problem is solved , but it again stucked on saving checkpoint... - Using train.py
@Clouxie
I'm not sure about the saving checkpoint issue. I suggest taking that over to Tensorflow's Github instead of here. As for model_main.py, lower the batch size a little bit in your training config. Set it to 1 just to make sure the file is running properly. It should output something pretty early on.
What is your hardware configuration?
Try updating to CUDA 10.0 and cuDNN 7.60 (uninstall CUDA 8.0 and cuDNN 7.4 first).
I can't really think of anything beyond that. If nothing happens after about 10 minutes, I'd hop over to TF's GitHub and ask them if they have any ideas.
`C:\Users\holox\models-r1.13.0\research\object_detection>python model_main.py --logtostderr --train_dir=training/ --pipeline_config_path=training\faster_rcnn_inception_v2_pets.config C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\framework\dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\holox\Anaconda3\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see:
- https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
- https://github.com/tensorflow/addons
- https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\slim\nets\inception_resnet_v2.py:373: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\slim\nets\mobilenet\mobilenet.py:397: The name tf.nn.avg_pool is deprecated. Please use tf.nn.avg_pool2d instead.
WARNING:tensorflow:From model_main.py:109: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\config_util.py:102: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
W1111 20:24:57.400801 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\utils\config_util.py:102: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:616: The name tf.logging.warning is deprecated. Please use tf.compat.v1.logging.warning instead.
W1111 20:24:57.402801 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:616: The name tf.logging.warning is deprecated. Please use tf.compat.v1.logging.warning instead.
WARNING:tensorflow:Forced number of epochs for all eval validations to be 1. W1111 20:24:57.403802 8476 model_lib.py:617] Forced number of epochs for all eval validations to be 1. WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\config_util.py:488: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.
W1111 20:24:57.403802 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\utils\config_util.py:488: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.
INFO:tensorflow:Maybe overwriting train_steps: None
I1111 20:24:57.404791 8476 config_util.py:488] Maybe overwriting train_steps: None
INFO:tensorflow:Maybe overwriting use_bfloat16: False
I1111 20:24:57.405802 8476 config_util.py:488] Maybe overwriting use_bfloat16: False
INFO:tensorflow:Maybe overwriting sample_1_of_n_eval_examples: 1
I1111 20:24:57.406802 8476 config_util.py:488] Maybe overwriting sample_1_of_n_eval_examples: 1
INFO:tensorflow:Maybe overwriting eval_num_epochs: 1
I1111 20:24:57.406802 8476 config_util.py:488] Maybe overwriting eval_num_epochs: 1
INFO:tensorflow:Maybe overwriting load_pretrained: True
I1111 20:24:57.407792 8476 config_util.py:488] Maybe overwriting load_pretrained: True
INFO:tensorflow:Ignoring config override key: load_pretrained
I1111 20:24:57.409793 8476 config_util.py:498] Ignoring config override key: load_pretrained
WARNING:tensorflow:Expected number of evaluation epochs is 1, but instead encountered eval_on_train_input_config.num_epochs = 0. Overwriting num_epochs to 1.
W1111 20:24:57.410793 8476 model_lib.py:633] Expected number of evaluation epochs is 1, but instead encountered eval_on_train_input_config.num_epochs = 0. Overwriting num_epochs to 1.
INFO:tensorflow:create_estimator_and_inputs: use_tpu False, export_to_tpu False
I1111 20:24:57.410793 8476 model_lib.py:668] create_estimator_and_inputs: use_tpu False, export_to_tpu False
WARNING:tensorflow:Using temporary folder as model directory: C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k
W1111 20:24:57.412792 8476 estimator.py:1811] Using temporary folder as model directory: C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k
INFO:tensorflow:Using config: {'_model_dir': 'C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x0000026F09BFA860>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
I1111 20:24:57.413794 8476 estimator.py:209] Using config: {'_model_dir': 'C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x0000026F09BFA860>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
WARNING:tensorflow:Estimator's model_fn (<function create_model_fn.
W1111 20:24:57.428797 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\data_decoders\tf_example_decoder.py:182: The name tf.FixedLenFeature is deprecated. Please use tf.io.FixedLenFeature instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\data_decoders\tf_example_decoder.py:197: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.
W1111 20:24:57.429797 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\data_decoders\tf_example_decoder.py:197: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:64: The name tf.gfile.Glob is deprecated. Please use tf.io.gfile.glob instead.
W1111 20:24:57.438799 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:64: The name tf.gfile.Glob is deprecated. Please use tf.io.gfile.glob instead.
WARNING:tensorflow:num_readers has been reduced to 1 to match input file shards.
W1111 20:24:57.443799 8476 dataset_builder.py:72] num_readers has been reduced to 1 to match input file shards.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:86: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE) instead. If sloppy execution is desired, use tf.data.Options.experimental_determinstic.
W1111 20:24:57.446800 8476 deprecation.py:323] From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:86: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE) instead. If sloppy execution is desired, use tf.data.Options.experimental_determinstic.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:155: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.data.Dataset.map() W1111 20:24:57.461803 8476 deprecation.py:323] From C:\Users\holox\Desktop\models-master\research\object_detection\builders\dataset_builder.py:155: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.data.Dataset.map()
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\ops.py:491: The name tf.is_nan is deprecated. Please use tf.math.is_nan instead.
W1111 20:24:57.603836 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\utils\ops.py:491: The name tf.is_nan is deprecated. Please use tf.math.is_nan instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\ops.py:493: add_dispatch_support.
W1111 20:24:57.632843 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\core\preprocessor.py:626: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\core\preprocessor.py:2412: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.
W1111 20:24:57.658849 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\core\preprocessor.py:2412: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.
INFO:tensorflow:Calling model_fn. I1111 20:24:57.892912 8476 estimator.py:1145] Calling model_fn. WARNING:tensorflow:From C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\ops\init_ops.py:1251: calling VarianceScaling.init (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version. Instructions for updating: Call initializer instance with the dtype argument instead of passing it to the constructor W1111 20:24:57.916918 8476 deprecation.py:506] From C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\ops\init_ops.py:1251: calling VarianceScaling.init (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version. Instructions for updating: Call initializer instance with the dtype argument instead of passing it to the constructor INFO:tensorflow:Scale of 0 disables regularizer. I1111 20:24:59.326224 8476 regularizers.py:98] Scale of 0 disables regularizer. INFO:tensorflow:Scale of 0 disables regularizer. I1111 20:24:59.336226 8476 regularizers.py:98] Scale of 0 disables regularizer. INFO:tensorflow:depth of additional conv before box predictor: 0 I1111 20:24:59.337226 8476 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0 WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\spatial_transform_ops.py:418: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version. Instructions for updating: box_ind is deprecated, use box_indices instead W1111 20:24:59.949364 8476 deprecation.py:506] From C:\Users\holox\Desktop\models-master\research\object_detection\utils\spatial_transform_ops.py:418: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version. Instructions for updating: box_ind is deprecated, use box_indices instead WARNING:tensorflow:From C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\contrib\layers\python\layers\layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version. Instructions for updating: Use keras.layers.flatten instead. W1111 20:25:00.292442 8476 deprecation.py:323] From C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\contrib\layers\python\layers\layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version. Instructions for updating: Use keras.layers.flatten instead. INFO:tensorflow:Scale of 0 disables regularizer. I1111 20:25:00.422472 8476 regularizers.py:98] Scale of 0 disables regularizer. INFO:tensorflow:Scale of 0 disables regularizer. I1111 20:25:00.604513 8476 regularizers.py:98] Scale of 0 disables regularizer. WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\meta_architectures\faster_rcnn_meta_arch.py:2651: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version. Instructions for updating: Please switch to tf.train.get_or_create_global_step W1111 20:25:00.622517 8476 deprecation.py:323] From C:\Users\holox\Desktop\models-master\research\object_detection\meta_architectures\faster_rcnn_meta_arch.py:2651: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version. Instructions for updating: Please switch to tf.train.get_or_create_global_step WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\utils\variables_helper.py:139: The name tf.train.NewCheckpointReader is deprecated. Please use tf.compat.v1.train.NewCheckpointReader instead.
W1111 20:25:00.623517 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\utils\variables_helper.py:139: The name tf.train.NewCheckpointReader is deprecated. Please use tf.compat.v1.train.NewCheckpointReader instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:345: The name tf.train.init_from_checkpoint is deprecated. Please use tf.compat.v1.train.init_from_checkpoint instead.
W1111 20:25:00.630518 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:345: The name tf.train.init_from_checkpoint is deprecated. Please use tf.compat.v1.train.init_from_checkpoint instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:177: The name tf.losses.huber_loss is deprecated. Please use tf.compat.v1.losses.huber_loss instead.
W1111 20:25:01.396691 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:177: The name tf.losses.huber_loss is deprecated. Please use tf.compat.v1.losses.huber_loss instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:183: The name tf.losses.Reduction is deprecated. Please use tf.compat.v1.losses.Reduction instead.
W1111 20:25:01.398692 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:183: The name tf.losses.Reduction is deprecated. Please use tf.compat.v1.losses.Reduction instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:350: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version. Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow into the labels input on backprop by default.
See tf.nn.softmax_cross_entropy_with_logits_v2.
W1111 20:25:01.427698 8476 deprecation.py:323] From C:\Users\holox\Desktop\models-master\research\object_detection\core\losses.py:350: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version. Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow into the labels input on backprop by default.
See tf.nn.softmax_cross_entropy_with_logits_v2.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:372: The name tf.train.get_or_create_global_step is deprecated. Please use tf.compat.v1.train.get_or_create_global_step instead.
W1111 20:25:01.571742 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:372: The name tf.train.get_or_create_global_step is deprecated. Please use tf.compat.v1.train.get_or_create_global_step instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\builders\optimizer_builder.py:58: The name tf.train.MomentumOptimizer is deprecated. Please use tf.compat.v1.train.MomentumOptimizer instead.
W1111 20:25:01.576743 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\builders\optimizer_builder.py:58: The name tf.train.MomentumOptimizer is deprecated. Please use tf.compat.v1.train.MomentumOptimizer instead.
WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:400: The name tf.summary.scalar is deprecated. Please use tf.compat.v1.summary.scalar instead.
W1111 20:25:01.577743 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:400: The name tf.summary.scalar is deprecated. Please use tf.compat.v1.summary.scalar instead.
C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\ops\gradients_util.py:93: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory. "Converting sparse IndexedSlices to a dense Tensor of unknown shape. " C:\Users\holox\Anaconda3\lib\site-packages\tensorflow\python\ops\gradients_util.py:93: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory. "Converting sparse IndexedSlices to a dense Tensor of unknown shape. " WARNING:tensorflow:From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:503: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.
W1111 20:25:03.760224 8476 deprecation_wrapper.py:119] From C:\Users\holox\Desktop\models-master\research\object_detection\model_lib.py:503: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.
INFO:tensorflow:Done calling model_fn. I1111 20:25:04.026296 8476 estimator.py:1147] Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. I1111 20:25:04.028285 8476 basic_session_run_hooks.py:541] Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. I1111 20:25:05.757686 8476 monitored_session.py:240] Graph was finalized. 2019-11-11 20:25:05.759517: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2019-11-11 20:25:05.770646: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library nvcuda.dll 2019-11-11 20:25:05.795044: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties: name: GeForce GTX 1070 major: 6 minor: 1 memoryClockRate(GHz): 1.7845 pciBusID: 0000:06:00.0 2019-11-11 20:25:05.800817: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check. 2019-11-11 20:25:05.806092: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0 2019-11-11 20:25:06.217399: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-11-11 20:25:06.222314: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0 2019-11-11 20:25:06.224729: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N 2019-11-11 20:25:06.228476: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6386 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1070, pci bus id: 0000:06:00.0, compute capability: 6.1) INFO:tensorflow:Running local_init_op. I1111 20:25:08.494727 8476 session_manager.py:500] Running local_init_op. INFO:tensorflow:Done running local_init_op. I1111 20:25:08.675768 8476 session_manager.py:502] Done running local_init_op. INFO:tensorflow:Saving checkpoints for 0 into C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k\model.ckpt. I1111 20:25:13.194029 8476 basic_session_run_hooks.py:606] Saving checkpoints for 0 into C:\Users\holox\AppData\Local\Temp\tmp5p6_n20k\model.ckpt. INFO:tensorflow:loss = 4.5861278, step = 0 I1111 20:25:20.487580 8476 basic_session_run_hooks.py:262] loss = 4.5861278, step = 0`
Yeah, as far as I can see, the training is running fine; it is just coming down to time. Just let it run for a little while (I'd say 30 mins if you can).
Just run train.py if nothing happens with that time and kick this over to TF's Github if you haven't already as that is pretty strange behavior. Let me know what happens! :)
Hi! @JulianOrteil Thanks for explaining the code and the process of calling it. I've just tried here and worked fine running on Ubuntu. But I have a (stupid) question: why does it only evaluate one time, for only one epoch? (precisely the last epoch of the trained model). When I follow it on Tensorboard, it plots only one point... You've mentioned that Eval is ran every 10 minutes, but my code ends its run without errors and doesn't seems to run again because there's no scheduled task or recursive running setup.
I'm feeling that I've lost any step here and I thought that this code would run recursively through the same steps of training session and evaluating losses and precision for each epoch, so I could observe the progress of model using validation dataset.
What I am doing wrong? (Sorry for any concepts mistakes or dummy questions... I'm just taking my first steps...)
Could you post a screenshot of the issue you're having? From what I'm understanding, the process exits after running eval once?
If the terminal returns for you to enter commands again (like username@host:~$) then this is usually indicative of errors in the background that Tensorflow didn't catch and report. I'm speculating right now, so when you have the chance, please provide a screenshot.
@JulianOrteil hey, what version of tensorflow's models repositary did you use? 1.13? I have to use tensorflow 1.14 just like you did, but I don't know what repositary I need to download
@goalpang You should be able to use the master branch as-is. They have compatibility for both 1.x and 2.x Tensorflow. If following my tutorial here, you should not have to change anything except for a path. I'll make the notes in my post.
@JulianOrteil I followed your instruction and resulted in to this. 8 seconds per 100 steps as seen below

When I tried to look at the tensorboard using the "tensorboard --logdir C:\tensorflow1\models\research\object_detection\training --host=127.0.0.1" this is what I see

My main concern when I followed the instruction is maybe I can see the mAP graph as well as training loss, validation loss and total loss because when I use train.py and view the tensorboard all I can see is the learning rate, losses but not the mAP and PR-Curves
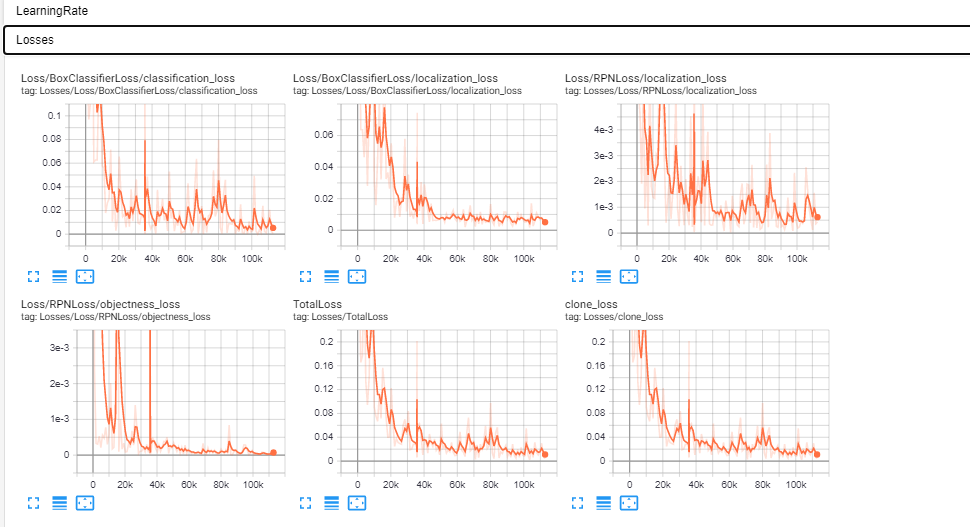

This is what I am trying to achieve
EDIT: when running model_main.py for 30 mins now I noticed that in the training folder, there was no checkpoint "model.ckpt-XXXX" like this one compared to train.py
@shawntyshawny How long did you let the training run? Did model_main reach the eval stage? Most graphs will not be visible until an eval is ran on your model.
@JulianOrteil in my first try, I waited about for it to finish 200k steps. I realized that my command was wrong it should have been --model_dir=training. I was able to make the mAP graph show in tensorboard but when I tried viewing for PR-Curves I still get this.
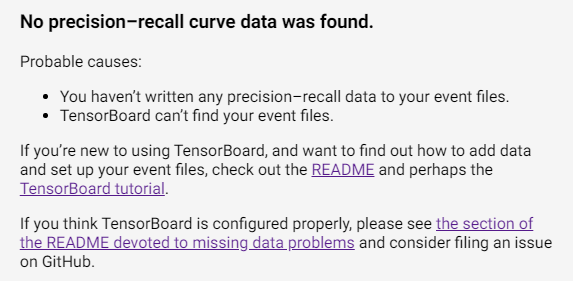
@shawntyshawny
I do not think that model_main produces PR graphs that Tensorboard displays in that category. You will have to research how to modify the training scripts to provide those graphs.
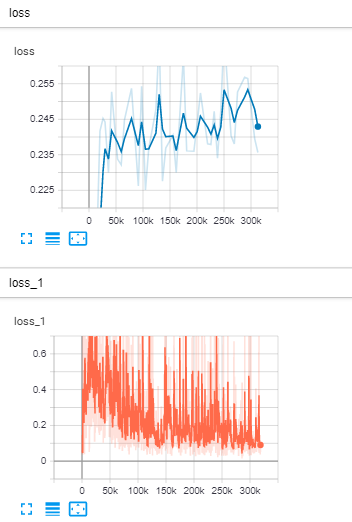
@JulianOrteil comparing with train.py and model_main.py, my totalloss on train.py decreases through iteration to less than 0.05 and smooth where in when using model_main.py the totalloss is increasing and loss_1 is spiking. Maybe I missed a step or something