Cabana
 Cabana copied to clipboard
Cabana copied to clipboard
Extending halo gather/scatter to allocate+utilize static MPI comms buffers
This draft PR demonstrates an interface to allocate and utilize static MPI comms buffers for the gather/scatter routines in Cabana_Halo.hpp, as opposed to reallocating a new buffer with each call. The interface contains functions that can be used to query the necessary buffer size given the current comms situation, allocate buffers (including support for a multiplicative "overallocation" factor), and check if the current buffer is big enough (which may be an overcomplete set of functions).
The interface is backwards compatible in a way that preserves existing behavior: the existing gather/scatter routines not utilize the new routines "under the hood," dynamically allocating and freeing buffers with each call.
This PR is not merge ready, but it is functional. I am opening this draft PR as an opportunity to share the code and have a discussion on how to evolve it from here. Indeed, some parts of it are redundant (checks, patterns in the gather/scatter, routines that take buffers, etc), and I ran out of stream with documentation in later routines, all of which needs to be addressed.
A representative before/after, demonstrating a gather of atom coordinates:
Before:
Cabana::gather( *halo_all[phase], x );
After:
if (!gather_check_send_buffer(*halo_all[phase], x_send_buffer))
x_send_buffer = Cabana::gather_preallocate_send_buffer(*halo_all[phase], x, 1.1);
if (!gather_check_recv_buffer(*halo_all[phase], x_recv_buffer))
x_recv_buffer = Cabana::gather_preallocate_recv_buffer(*halo_all[phase], x, 1.1);
Cabana::gather( *halo_all[phase], x, x_send_buffer, x_recv_buffer);
In the "before" case, exactly sized send and receive buffers are allocated within gather each time it's called. On the other hand, in the later case, we carry around a static send (x_send_buffer) and receive (x_recv_buffer) buffer, and follow a standard pattern:
- Check and see if the existing buffer is large enough (
gather_check_[send/recv]_buffer); if not allocate a new one (gather_preallocate_[send/recv]_buffer) with an optional overallocation factor, here1.1, to avoid frequent re-allocations. - Call a new variation of
gatherwhich takes in these send and receive buffers.
This pattern can be applied directly to the atom migration routines as well, I just hadn't gotten there yet. Since gather, scatter, and particle migration can all follow the same pattern of buffer check/reallocate if necessary/perform exchange, there's some scope to unify how buffer (re-)allocation is done.
This is great! I went through a round of cleanup, but I still need to:
- [x] Add this option to the comm benchmark
- [x] Add this to the halo unit test
- [x] Make sure there's nothing that would cause an issue for the same type of interfaces in particle migrate
- [x] Run benchmarks
Codecov Report
Merging #549 (b304012) into master (a43c919) will increase coverage by
0.0%. The diff coverage is96.5%.
@@ Coverage Diff @@
## master #549 +/- ##
=======================================
Coverage 94.9% 94.9%
=======================================
Files 47 47
Lines 5633 5734 +101
=======================================
+ Hits 5346 5444 +98
- Misses 287 290 +3
| Impacted Files | Coverage Δ | |
|---|---|---|
| core/src/Cabana_Halo.hpp | 95.1% <95.8%> (-0.3%) |
:arrow_down: |
| core/src/Cabana_CommunicationPlan.hpp | 98.5% <98.5%> (-0.1%) |
:arrow_down: |
| core/src/Cabana_Tuple.hpp | 100.0% <0.0%> (ø) |
:mega: We’re building smart automated test selection to slash your CI/CD build times. Learn more
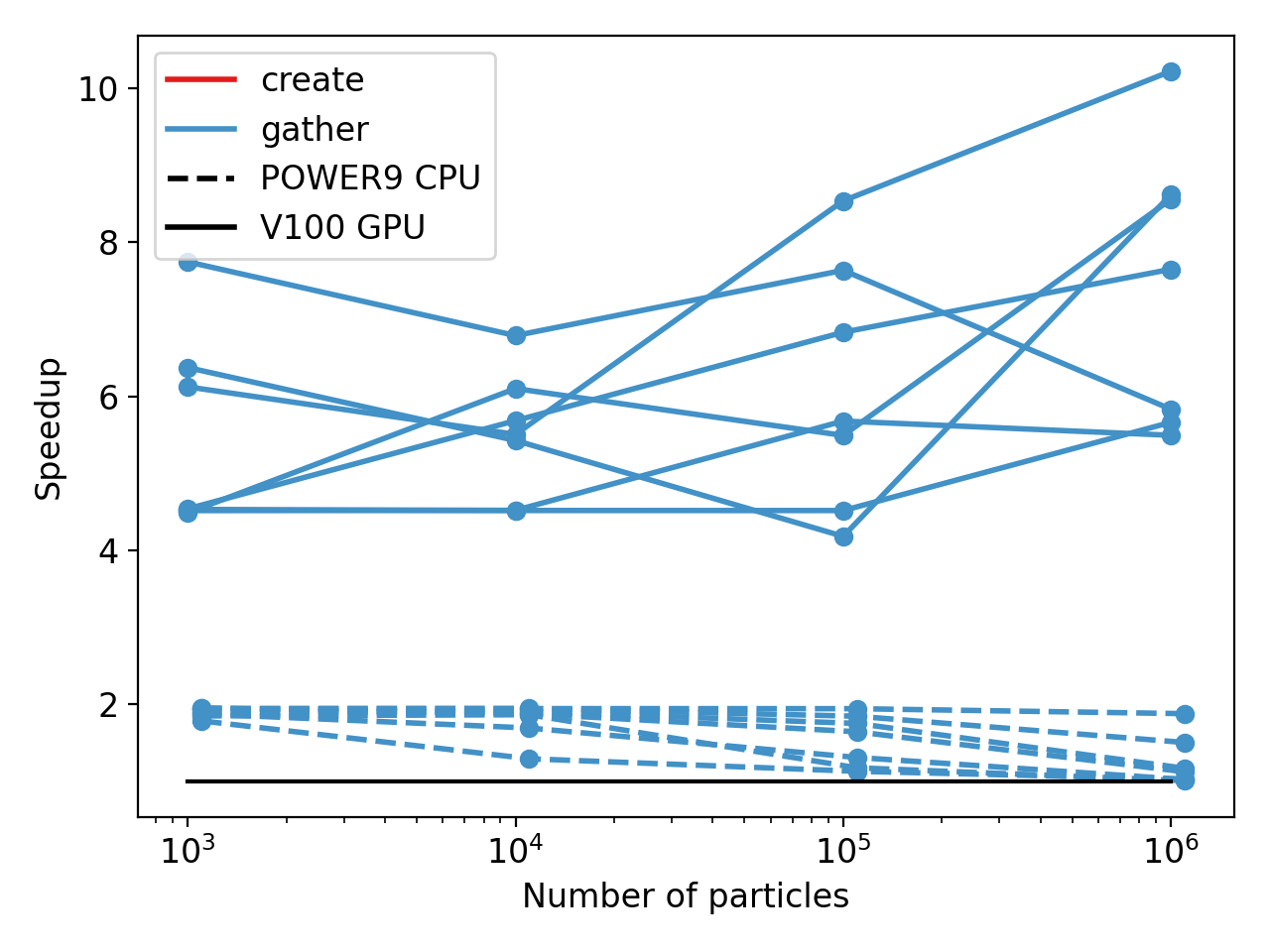 Here are the Summit results for gather (very similar for scatter) on a single rank. Each line is a different fraction of particles communicated. Very nice to see 4-10x speedup on a single V100 and 1-2x on the CPU (more clear trend where the largest sizes can nearly hide the allocation). Multi-rank tests showed more variability, but were similar overall
Here are the Summit results for gather (very similar for scatter) on a single rank. Each line is a different fraction of particles communicated. Very nice to see 4-10x speedup on a single V100 and 1-2x on the CPU (more clear trend where the largest sizes can nearly hide the allocation). Multi-rank tests showed more variability, but were similar overall
@weinbe2 @sslattery this is a rewrite with new Gather/Scatter objects to handle the buffers for the user. Base classes should make the migrate versions easier (future PR). This is missing variadic slice options though
New performance results (slices & scatter as well) - a little more noisy, but same overall
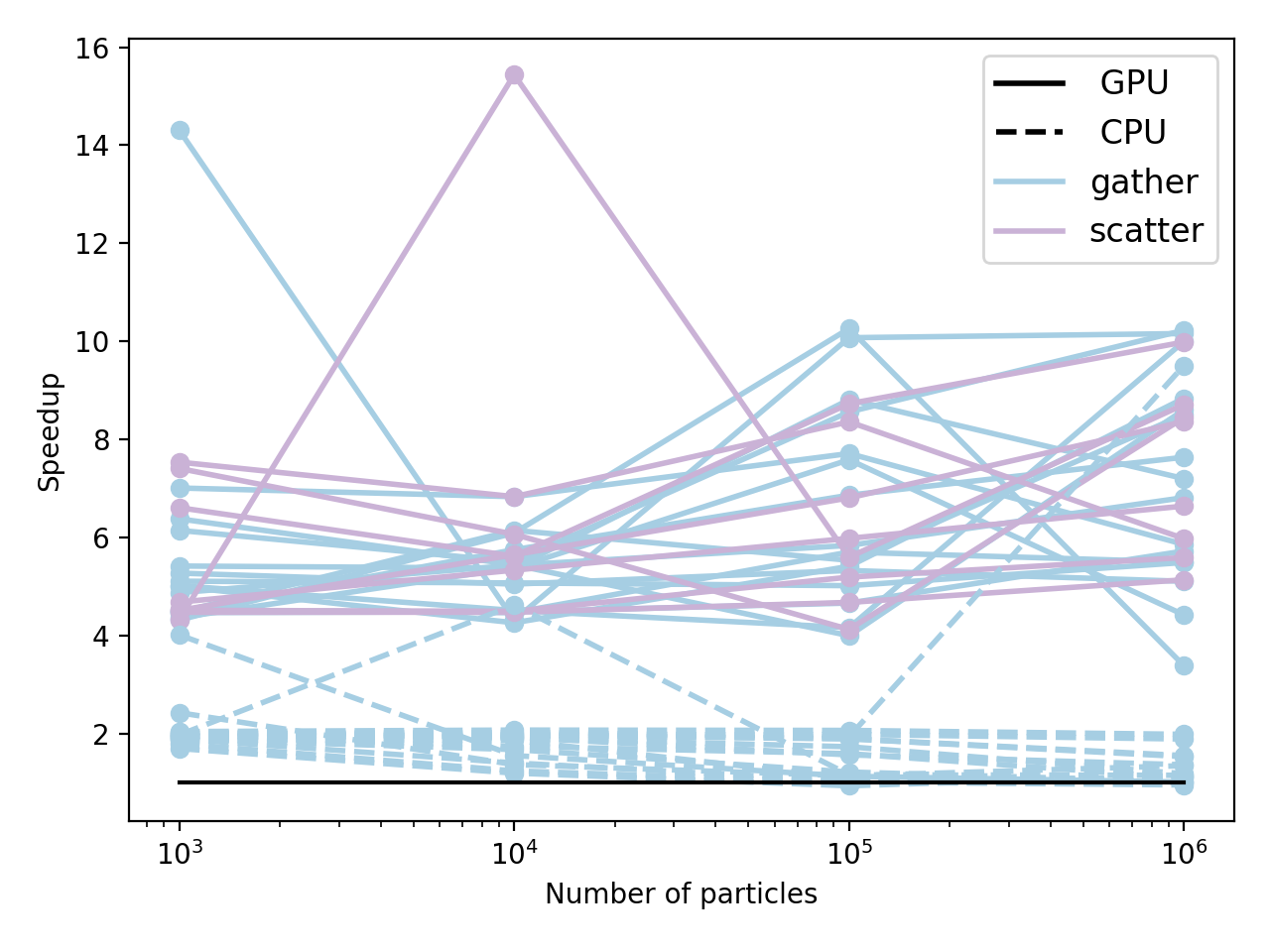
Well I thought this was done, but I hit a segfault. Only on the 1 million particle performance test, but it's something in the last 3 commits
@sslattery @weinbe2 Last issue I mentioned was just for the host/device benchmark case because of missing mirrors. No change in performance comparisons and ready for final review