chproxy
 chproxy copied to clipboard
chproxy copied to clipboard
Memory consumption spikes after upgrading to v1.16.x
We're running chproxy in k8s, before we were using v1.13.2 and memory consumption was constantly low, we used 512Mi limit and it was enough.
After upgrading to v1.16.x we've got chproxy PODs OOMed constantly, and with 8Gi limit picture look like following:

There are very clear seasonality, in the beginning of 10th minute we have a memory consumption spike. But not always

Here is some go memstats metrics, exported by the chproxy instance:

For this instance, we do not have any file_system type caches, but have 3 caches in Redis.
We have 4 different clusters, 10 cluster users and about 150 users configured.
I tested this configuration on the another chproxy instance, constantly staying idle (no user-requests served), and memory consumption there remain constant (no spikes).
For now, even with a 8Gi limit we have chproxy PODs oomed sometimes :(
Our current version is 1.16.3
Any ideas how to find a cause of this issue? Thanks!
Hi,
Are you running queries that retrieve a lot of data? If yes then it's a "known" issue.
It was created during the implementation of the redis cache feature and it's linked to the flow of a query in chproxy. Here is how a not cached query is handled: [send request to clickhouse] => [temporary store the result] => [check if the query is worth caching] => [cache query if needed] => [return result to the sender]. Before the Redis implementation, the temporary storage was disk based, now it's memory based.
I think we will do a quick fix and go back with a disk based temporary storage. The ideal solution would be to avoid the temporary storage and stream everything but it might require a huge refactoring of the code. What do you think @Garnek20 ?
Are you running queries that retrieve a lot of data?
For some queries response body size can be few MBs, i'm not sure it's a lot or not:
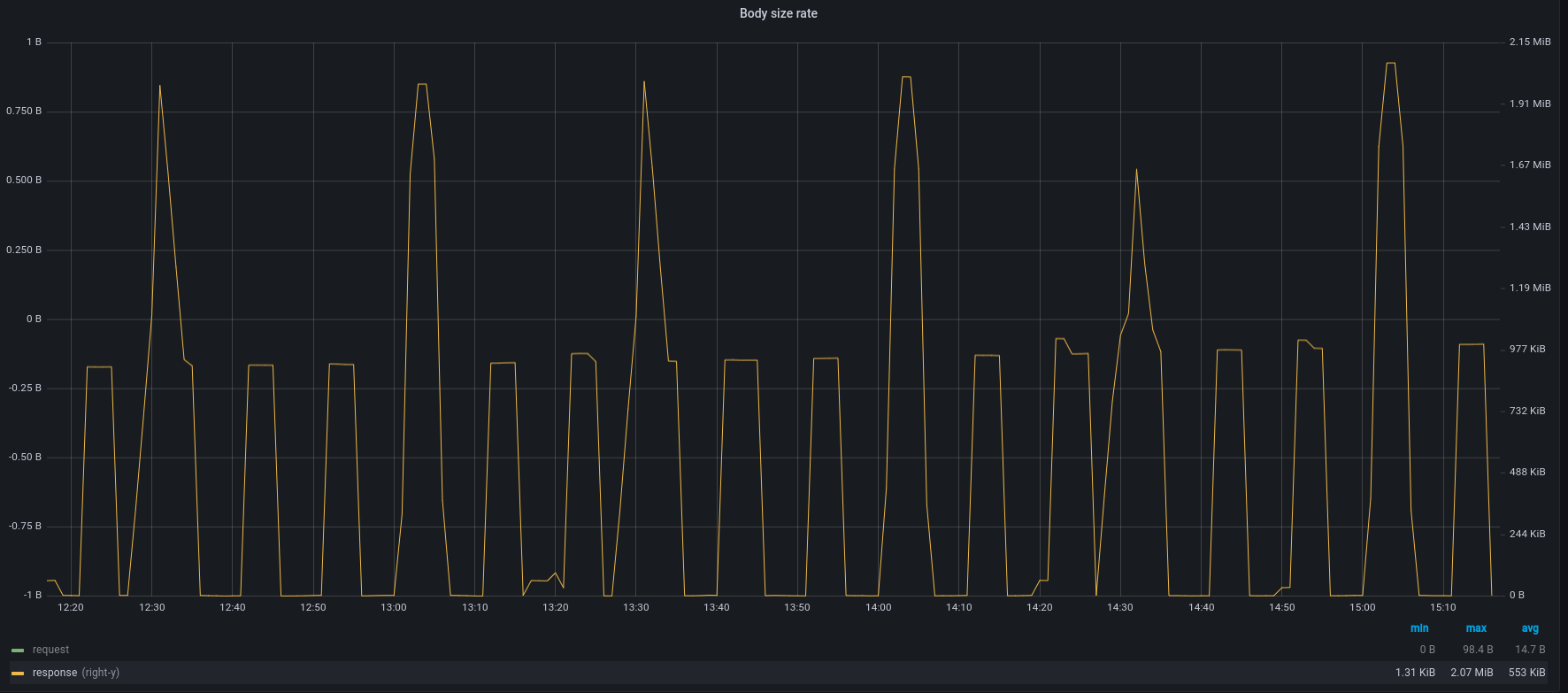
Before the Redis implementation, the temporary storage was disk based, now it's memory based.
Aah, okay, this explains everything. Previous solution was working pretty much fine, but with a current implementation if, for example, some clients fetching more data, than current mem limit, chproxy will just crash due to OOM. If mem-backed temporary storage has been implement to reduce the latency for "short" queries, then small results may be stored in the memory, but big one (>threshold?) may be stored on the disk-backed storage. Just an idea.
Anw it's good to know it's a "known" issue :)
Hi @PhantomPhreak , can you also share how many QPS chproxy handles during OOMs for the queries of roughly 5Mb / query result?
@Garnek20 hi
we've got it OOMed @ 13:31:02, here is a related graphs for this timeperiod:
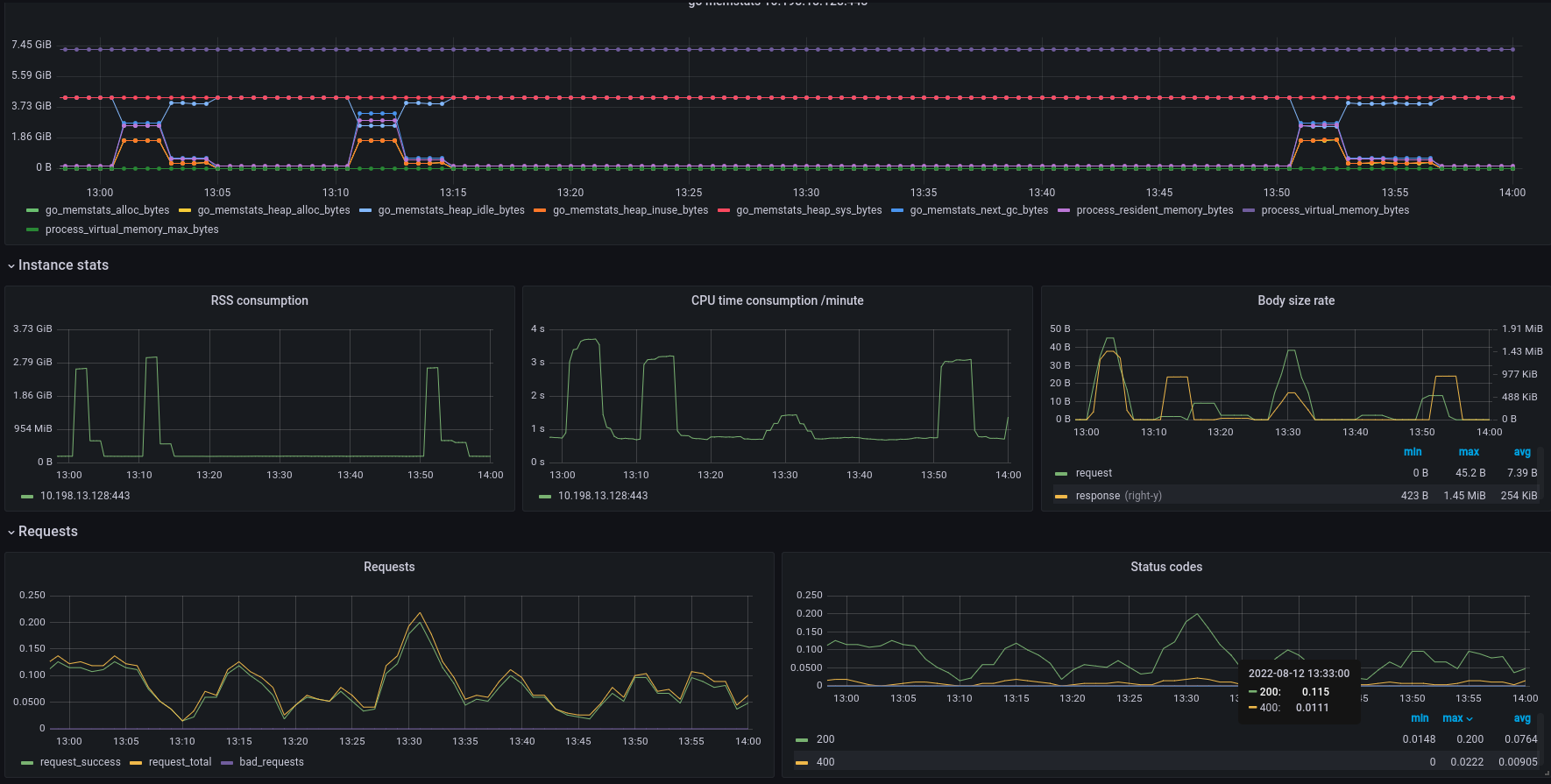
i hope it helps!
Hi, thanks it helps.
FYI we took a look at the pb and it seems deeper than expected. The redis feature (that needed a huge refacto of the code) added a few hidden copies of objects so there is an amplification btw the result of the query and the amount of memory needed in chproxy to handle it. It's also lightly impacts the old filesystem cache (there is at least one full copy of the result). It's a huge regression that started since 1.15.X versions.
We're going to release a fix ASAP (at least a huge improvement even if it doesn't fix everything) but since it's deep and we're partially off next week, don't expect something before next 2 weeks.
Hi, FYI a fix is almost ready, it should be available next week (we will release a new version as soon as the PR is merged). You can read the description of the PR to see what you can expect. https://github.com/ContentSquare/chproxy/pull/212
A new version with the fix is released https://github.com/ContentSquare/chproxy/releases/tag/v1.17.0 feel free to use it. I close the PR, if this new version still doesn't solve your memory overhead, feel free to reopen it.