clickhouse-go
 clickhouse-go copied to clipboard
clickhouse-go copied to clipboard
Safety: error out on unsupported server versions
Is your feature request related to a problem? Please describe. we use server version 21.1.8, and upgrade to version 22.3 was delayed. In order to take advantage of performance improvement of client driver v2, we went ahead and upgraded from v1.5.4 to v2.2, without knowing it's not supported for the server version. Our testing didn't catch any problems except for the default conn_open_strategy incompatible change we reported earlier. It was almost 3 weeks after deployment that some problems manifested then it took a village for us to hunt down the potential causes along the long chain of services. Now we realized that this server and client version incompatibility could have caused the silent bugs (we had proof what went wrong - contact me if you need to know details). (Sorry that I'm from commercial software background, and it was hard for me to think the server and client software released within about a year from each other won't work together. So we missed that unsupported list we should have paid attention!)
Describe the solution you'd like the client driver starts with hand-shake with the server, on unsupported server versions, to prevent accidents, it should error out, instead of continuing.
Describe alternatives you've considered A server and client version compatibility matrix page would help users for safe upgrade path.
Additional context Appreciate your understanding and support!!
@ns-gzhang could you please be specific re incompatibilities ? a definitive list would be useful for us to think about preventing moving forward.
Indeed, on our proposed support policy 21.1.8 would indeed not be supported. We should at minimum log warnings.
Note: For CH, we test old server with a new client and old client with a new server on every extension of the protocol. CH policy is simply to not let any incompatibilities - hence the request above for more detail.
Thanks @gingerwizard for your response. I'm glad to hear that server versions and client versions were actually tested for incompatibilities (even they are listed as unsupported, I assume). The problem we encountered was pretty bad and I edited the issue and removed more details due to the sensitive nature of the problem. I can send details to you in a private email if there is a way to do that. (I requested connect with you on LinkedIn, thanks!)
Looks like @gingerwizard was too busy to accept my LinkedIn request :-) I'm going to describe the problem here. Environment: app serving http requests, deployed on K8s, used client driver v2.2 to connect to CH servers (version 21.1.8, 3 replicas per shard) on VMs (os ubuntu 20.04), with non-default user/password, compression and TLS enabled. DB per shard was set to have max open conns of 6, max idle conns of 6, max lifetime of 1 hour, and the round-robin conn open strategy. The following symptom was observed, and they occurred randomly once or a few times in about a million:
- A request
req1got a response from the driver (before CH server finished execution of its SQL). We don't know what the response was. Its real response is denoted asresp1. - About 14 to 25 seconds later, another request
req2came in, and while CH server was executing its SQL and long before it finished, the driver returnedresp1as the result set forreq2.req2got a wrong result set.
We added defensive code doing sanity check to catch the scenario when 2) happened. It caught the errors. This did not happen with v1. We also observed that around times when this happened, the CH servers got unknown packets from the client. It could be coincidence. Or it could be network noise. We did observe that driver could return errors of "driver: bad connection" after starting return of result sets (especially after we downgraded the driver back to v1).
We were not able to reproduce in an isolated environment when the driver had the debug enabled. We are trying with driver debug turned off.
Thanks!
That indeed sounds concerning @ns-gzhang i'll try to reproduce this with a stress test - it sounds like its going to be a fun one to track down.
I assume you're executing these in different go routines and sharing the connection?
oh and linked in request accepted :)
Thanks @gingerwizard . Here are some code snippets:
... // creating a DB (DB connection pool)
clickServers := make([]string, 0, 3)
for _, replica := range replicas {
clickServers = append(clickServers, fmt.Sprintf("%s:%d", replica.Host, replica.Port))
}
tlsconf := &tls.Config{
InsecureSkipVerify: true,
}
opts := &clickhouse.Options{
Interface: clickhouse.NativeInterface,
Addr: clickServers,
Auth: clickhouse.Auth{
Database: defaultDB,
Username: user,
Password: passwd,
},
TLS: tlsconf,
// Debug: true,
Compression: &clickhouse.Compression{
Method: clickhouse.CompressionLZ4,
},
DialTimeout: 5 * time.Second,
ConnOpenStrategy: clickhouse.ConnOpenRoundRobin,
}
client := clickhouse.OpenDB(opts)
client.SetMaxIdleConns(maxIdleConns)
client.SetMaxOpenConns(maxOpenConns)
client.SetConnMaxLifetime(time.Hour)
clientsMapping[cluster] = client
Then the client will be used as db in executing a SQL query:
rows, err := db.QueryContext(ctx, sqlString)
if err == nil {
return rows, nil
}
// if there is an error, we loop to retry after backoff
...
for err != nil {
...
err = db.Ping()
...
rows, err = db.QueryContext(ctx, sqlString)
}
Our understanding is that db is concurrency safe. And the equivalent has been working in v1 for a long time.
Goroutines are from the go-chi framework.
We are using go v1.17. Hope this helps you to pin-point the root cause.
@gingerwizard We had some interesting scenario as more background for your investigation. This may or may not lead to the problem we had above. Here is the observation for one request (with the v1 driver):
- we set the timeout limit to 90s, and sent the query to clickhouse-go client.
- from CH server query_log, we found the query arrived the server (QueryStart event) about 89s later.
- we assumed that clickhouse-go driver was waiting for an open connection (during relatively busy time, all connections were used).
- the clickhouse-go client timed out after 90s, and went away (the CH server noticed that event).
- the CH server finished the query in 6+s, and tried to send the results back, and found the client left already, resulting in 210 error code.
The reason I'd like to describe this scenario is that there might be a possibility in the v2 driver, the timed-out connection could be reused by a future request, while the connection didn't get "reset" when it timed out by the client earlier. Is it possible? Thanks.
The "reset" keyword in my previous posting triggered me to search for more in code that resets a connection. I couldn't find in the v1 code, but in v2, I've found this:

I cannot be sure if this is consistent with database/sql/driver spec without knowing the whole history of a connection, after timeout and then being reused:

I'm getting to another piece of code - when timing out, cancel() is called to close the connection:
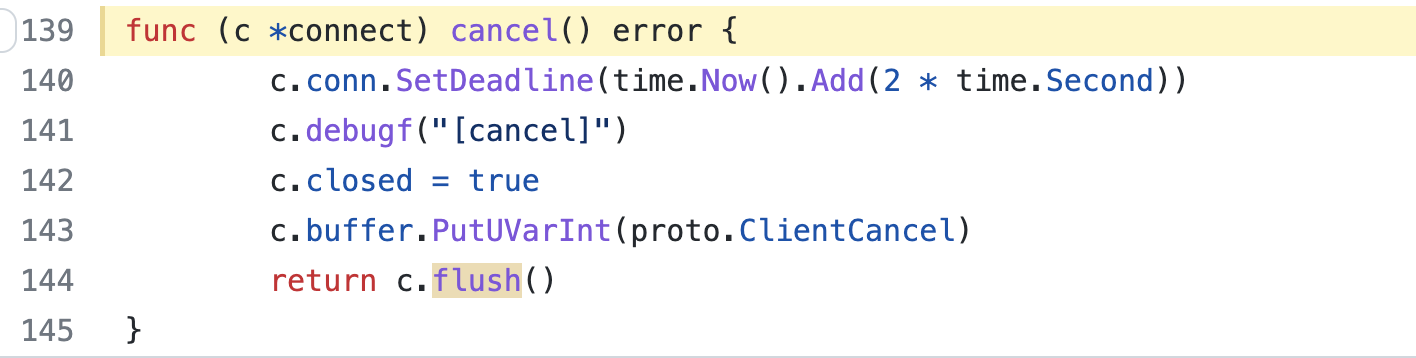 As I mentioned earlier, the CH server did complain it received unknown packet from the client during the times of errors. So wondering if the
As I mentioned earlier, the CH server did complain it received unknown packet from the client during the times of errors. So wondering if the proto.ClientCancel is something the v21.1.8 server does not recognize? (unlikely - something else in play)
I found two differences: in comparison, v1 cancel() does not have 2 seconds timeout, and also calls Close():
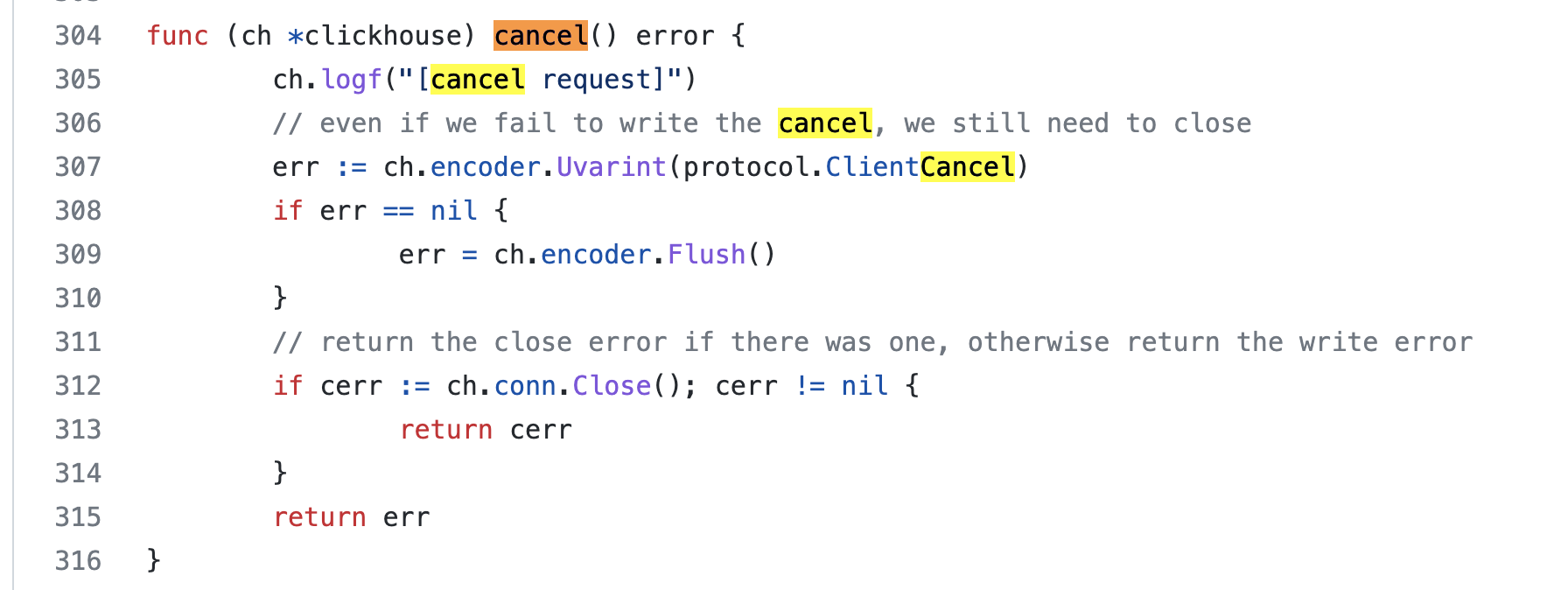 Hope my investigation helps to speed up diagnosis on your end. We cannot upgrade to v2 without a fix of this problem. Thanks.
Hope my investigation helps to speed up diagnosis on your end. We cannot upgrade to v2 without a fix of this problem. Thanks.
I'm getting to another piece of code - when timing out, cancel() is called to close the connection
after ClientCancel you can still be getting the data, clickhouse-client uses something like buffer draining there.
https://github.com/ClickHouse/ClickHouse/blob/3396ff6c3a2cd050ea4c53e7f1981f3a95fa2ad4/src/Client/ClientBase.cpp#L809
Alternative is connection closing.
Hi Dale @gingerwizard , @filimonov has helped to pinpoint the trouble spot in the code logic above. It's very dangerous for all the customers who are using the V2 driver, IMHO. Just to raise your awareness. Thanks!
Yes agreed. I will aim to fix this weekend or early next week @ns-gzhang apologies for delay this issue needs a new title indicating its priority.
Safe thing to do is maybe just close the connection and read a new connection to the pool @filimonov ?
Yep, that is safe. Draining is more expensive / slower. Connection closing may leave a warning in server error log (but it's ok).
Issue re concurrency here https://github.com/ClickHouse/clickhouse-go/issues/761 @ns-gzhang
This will be closed by https://github.com/ClickHouse/clickhouse-go/pull/792. Concurrency issue tracked in #761
@ns-gzhang we decided to warn vs error out on unsupported versions.