Add AVX2/AVX/SSE2 SIMD accelerated 1D/3D LUTS
I'm still messing around with this but wanted to share a work in progress for some feedback. This is based off of work I've done with 3d luts here #1681 and most of the code is ported from that project.
Here are some of the current performance results
ocioperf.exe --transform tests/data/files/clf/lut1d_32f_example.clf
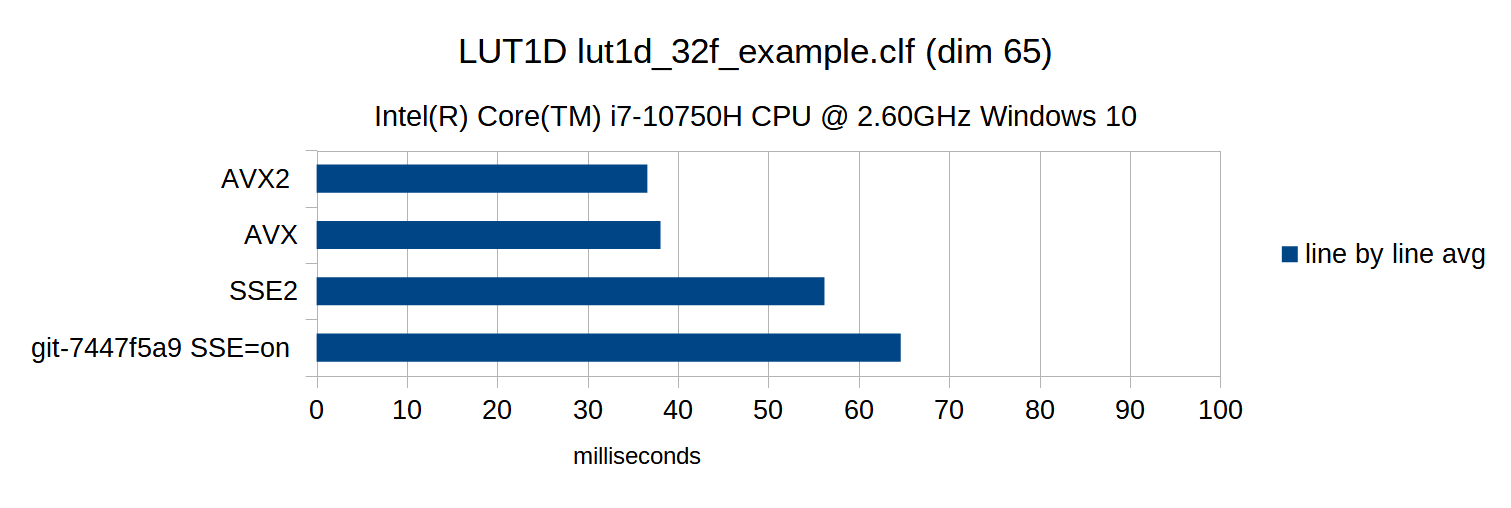
ocioperf.exe --transform tests/data/files/clf/lut3d_preview_tier_test.clf
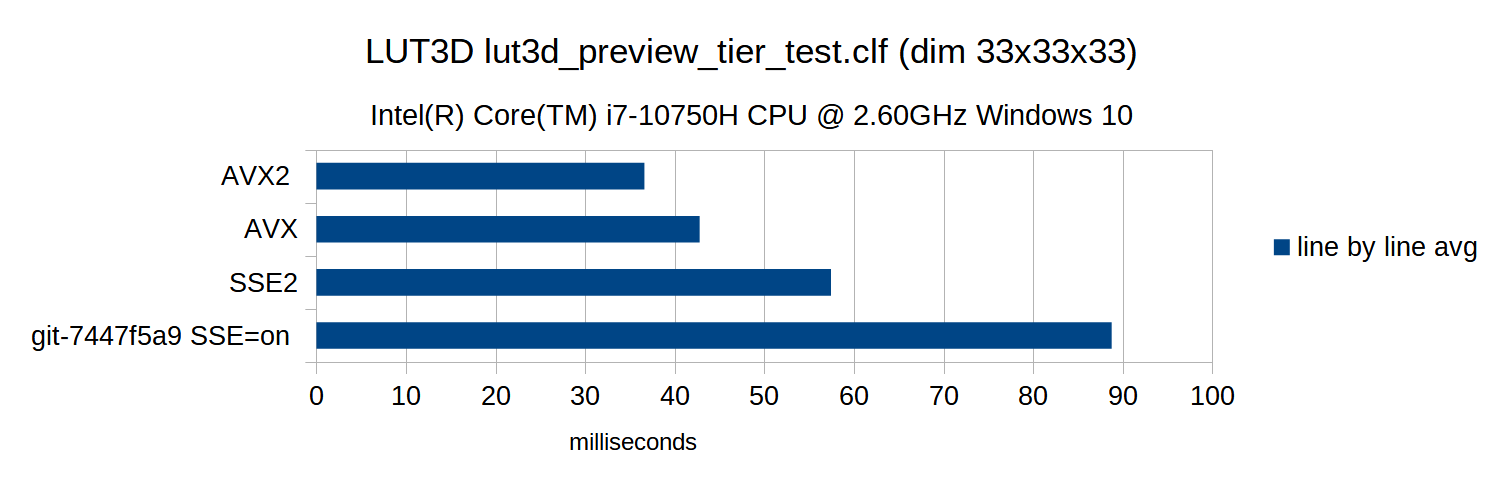
Supporting additional x86 SIMD instruction sets adds more complexity to the build system. Some of following things need to get considered.
- is the instruction set enabled in the build?
- is the instruction set supported by compiler and what are the flags to turn it on?
- is the instruction set supported by cpu?
The really tricky bit is that what SIMD instruction sets a cpu has varies between models and brands. If a cpu encounters an instruction it doesn't have, a program will just crash. So you can't just turn on the AVX/AVX2 compiler flags for the whole build if you want to run on a wide variety of systems. Instead, each implementation is a separate compilation unit and the compiler flags are only used on that unit.
The cpuid instruction can be used at runtime to determine what instructions your cpu has and the best implementation can be chosen then, currently being done with a function pointer.
Some of the things I' currently thinking of doing
- Cleanup and move CMake SIMD detection to separate cmake files
- Put CPUInfo class in platform.cpp?
- Change the file naming, was thinking something like this
- ops/lut3d/x86/avx2.cpp
- ops/lut3d/x86/avx.cpp
- ops/lut3d/x86/sse2.cpp
The pull request is also very large so I was thinking I might break it into separate smaller requests.
Perhaps one for the AVX2/AVX build support/tests, one for lut3d and one for lut1d.
![]()
The committers listed above are authorized under a signed CLA.
- :white_check_mark: login: markreidvfx / name: Mark Reid (540c6a6c5121bfd67f007c0d2522ce05d6ad6cea, 9d4d108cb861886f22dd510254e47fcfb7dd6480, 7b9beeb0b14c06be72edf33ad220cd87f78495f9, c4f4961a0462175de0612121f4f4155137f0a88f, 0df767c3f229f0c2aeedb4383b0e55bd50672874, d8a575bd0bc1150d2857daa65325a5704b238f41, 0e1f8ab7efb2f74212f621e9c0ad658ec34022a3, c77b4490cf1639aae14708ddd7665a2dedc2e2c6, e6aae813cee97c52485a8d2a51ac50a2ec3aa74a, 33810d318c74767200f7898862e0099f0da69557)
- :white_check_mark: login: doug-walker / name: Doug Walker (80d0d1fc3ae0a7b4ff971de3e0acdcfed0a531b4)
@markreidvfx, it's going to take some time for me to do a proper review, but I just wanted to say thank you so much for this PR! I especially appreciate the comments explaining the packing being used with the intrinsics and the many unit tests. It's really great to have you contributing to the project!
I think the naming is fine as is (leaving lut1d or lut3d in the module names) and it's fine to leave it in one big PR, if that's easiest.
Thanks @doug-walker :) I tried to add a lot test for the packing/unpacking because it can be tricky to get right, and I'm hoping the infrastructure could be use for adding SIMD acceleration to other ops in the future.
Thank you for the PR @markreidvfx, the implementation looks great! I commented on a few minor things and asked some questions.
-
Cleanup and move CMake SIMD detection to separate cmake files
-
Put CPUInfo class in platform.cpp?
-
Change the file naming, was thinking something like this
- ops/lut3d/x86/avx2.cpp
- ops/lut3d/x86/avx.cpp
- ops/lut3d/x86/sse2.cpp
-
That would be preferable as I mentioned in the comments section.
-
I don't necessarily have a strong opinion, but it is indeed a platform-specific thing, so that could make sense. (see comment in PR)
-
I like the folder structure as it feels more organized, but I do think that both work and have different arguments going for them. I'm leaning a bit more toward the folder side as I find it a more structured, organized and simpler filename.
It is going to conflict a bit with the work done in Adsk Contrib - Add support for neon intrinsic #1775 but it shouldn't be too major.
Thanks for reviewing the pull request! Its been a while since I looked at this code, I'll take a deeper dive when I get a chance.
Thanks again everyone for taking the time to review! @cedrik-fuoco-adsk I'll move the cmake code to a separate file. I'm going leave the rest of folder/file structure as it is for now, unless anyone objects.
I don't want to derail this PR, it's really none of my business, but I thought it might be helpful to give a data point about how we handled SIMD in OIIO and OSL.
I think I'm reasonably savvy about hardware features? But I stumble over the intrinsics constantly, can't remember what they mean without looking each one up, and generally find code littered with intrinsics to be nearly impossible to maintain (not to mention that it must be repeated for each ISA you want to code). And code that uses the intrinsics is unreviewable by anybody not intimately familiar with the instruction sets and what each intrinsic does.
So the approach I took in OIIO is to hide it all behind intuitive vector classes in a single header file. This one header is the only place in the entire code base where a CPU-specific intrinsic can be found. The implementations -- be they SSE, AVX, NEON, as well as non-SIMD reference/fallback code -- are within each function or method, separated by appropriate #if guards. This means that places that use the intrinsics (i.e. use the classes) look generic, need no separate implementations for each CPU ISA, and are totally straighforward to read, understand, and review, without any knowledge of CPU intrinsics at all (as long as you trust the underlying class implementations).
Here is an example of how 4-wide SIMD is used to accelerate an "over" operation. Clear, yes? And no separate code needed for each ISA.
Here is an example that is even better, a fast implementation of exp2. Where are the intrinsics? They're all hidden behind the templating, because all the right functions and operators are overloaded, so you can say fast_exp2(float) or fast_exp2(vfloat4) or fast_exp2(vfloat8), or whatever. No fuss, no coding it separately for every ISA.
Last example, this time from OSL (which uses OIIO's simd.h, and please excuse the use of the old name, "float4" instead of the new name "vfloat4"), of how OSL implements Perlin noise with OIIO's simd classes. This works for both SSE and NEON, as well as fully non-SIMD on other architectures.
Honestly, there's nothing special about OIIO's simd.h. There are other implementations of SIMD vector classes out there that are roughly equivalent. But I want to make a case for the improved readability of restricting the literal reference to the intrinsic names to just one place in the code base, and wrap them with classes that make all the other scattered uses very intuitive, readable, maintainable even by non-experts, and templatable.
Thank you @lgritz , for bringing that to our attention! I agree, it's a much more readable and maintainable approach.
Sorry it took me so long to get back to this.
I'm very comfortable with intel intrinsics which is the main reason I did it this way. Personally, I like the simplicity of just using the intrinsic directly without needing to know inner workings of some complex wrapper. I also like being able to freely modified one platform with zero worry of effecting another. There are a few other reasons but I can totally see how people can be turned off by this approach.
I'll take a deeper look at OIIO simd header when I get some time but at first glance looks pretty straight forward. I'm not doing anything too fancy but also not sure how this would effect performance, without porting and measuring. Everything will need to be reworked if this is route we wish to take.
@lgritz out of curiosity, how does OIIO do single binary builds that support multiple x86 simd instruction sets dynamically?
OIIO doesn't currently do single binary builds that support multiple ISAs. It's chosen at build time. OSL does have something relevant, though, where certain functions that are worth building with ISA-specific instructions are put into a secondary library and compiled separately for several ISAs, then the specific one is incorporated at runtime via dlopen'ing the one that corresponds to the hardware found.
I think its good to remove the Draft.
There is a better SSE2 fallback I'd like to add for cpu's that don't have the F16C extensions, but I can do that in a later pull request.