Tetrahedral Lut3D CPU SIMD Optimizations
I added SIMD optimizations to FFmpeg's lut3d filter a while ago and recently set up a small project to measure the performance of various tetrahedral Lut3D implementations with different compilers.
https://github.com/markreidvfx/lut3d_perf
The FFmpeg implementation was done in x86_64 assembly, but I've since ported it to SSE2, AVX and AVX2 intrinsics and have come up with a few more optimizations.
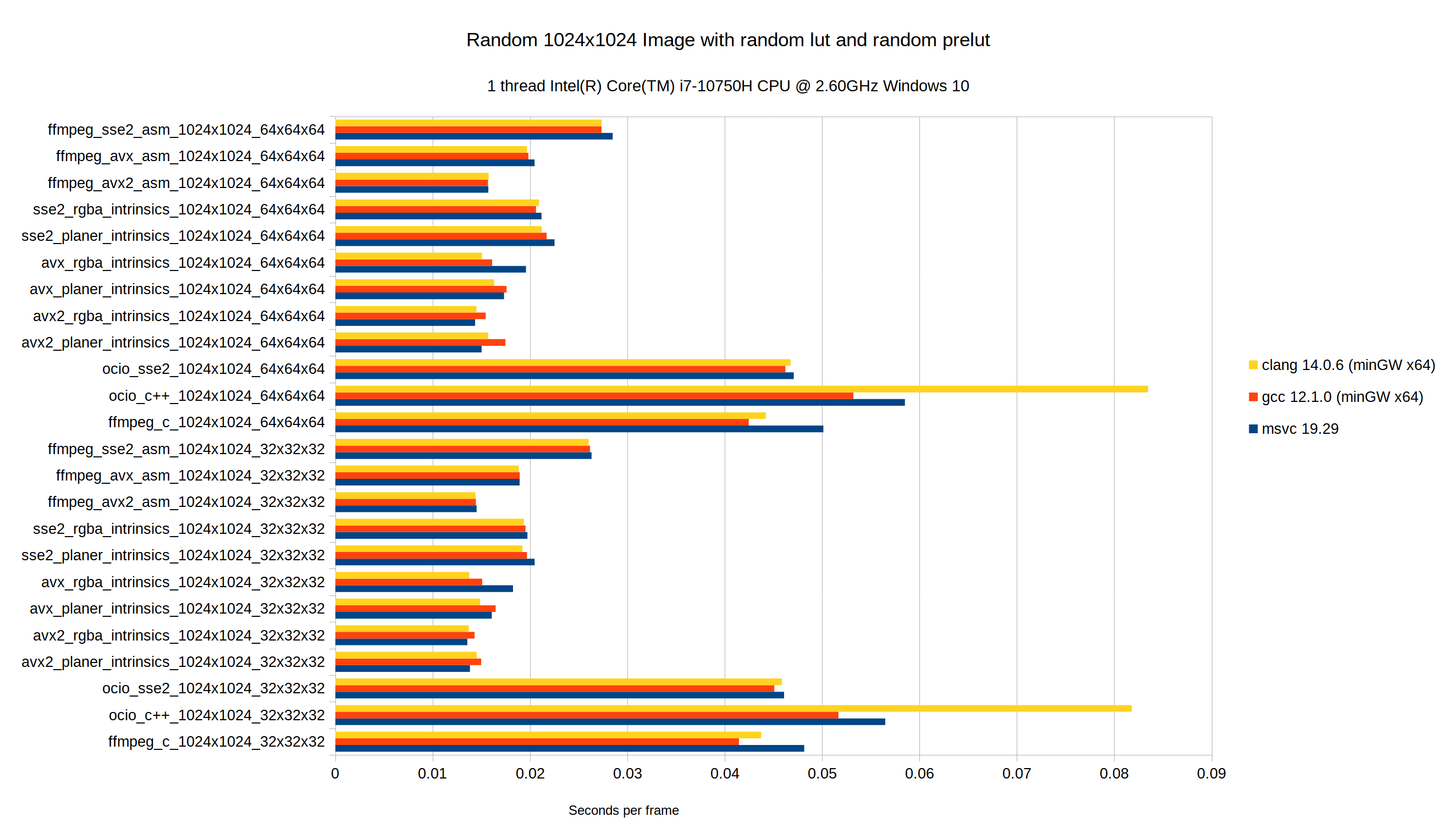
Compared to OCIO's implementation, my branchless approach appears to be more performant, at least on the platforms I've tested.
My results running on CentOS VM on an AMD EPYC 7F72 24-Core Processor with devtoolset-6 and devtoolset-9 compilers
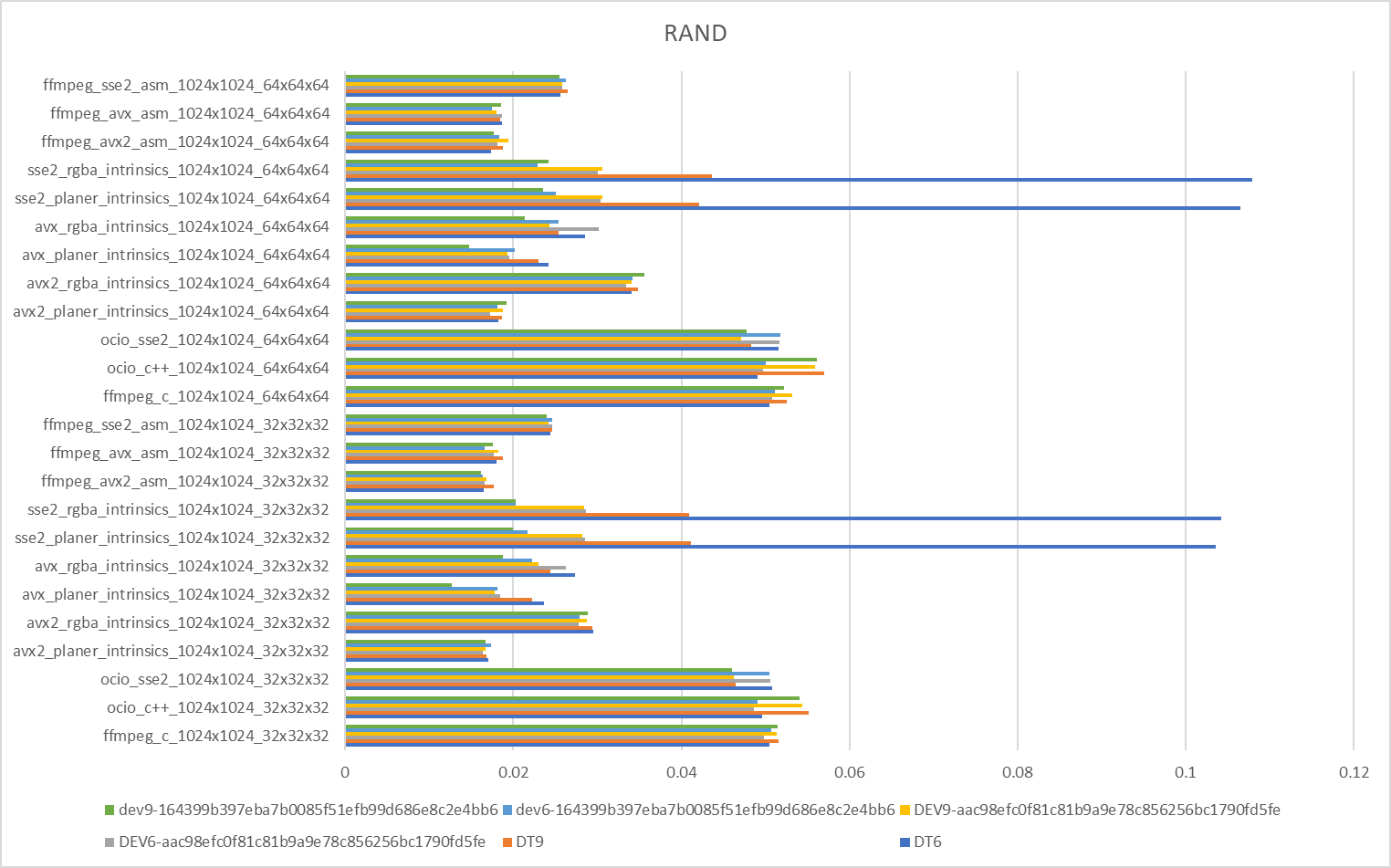
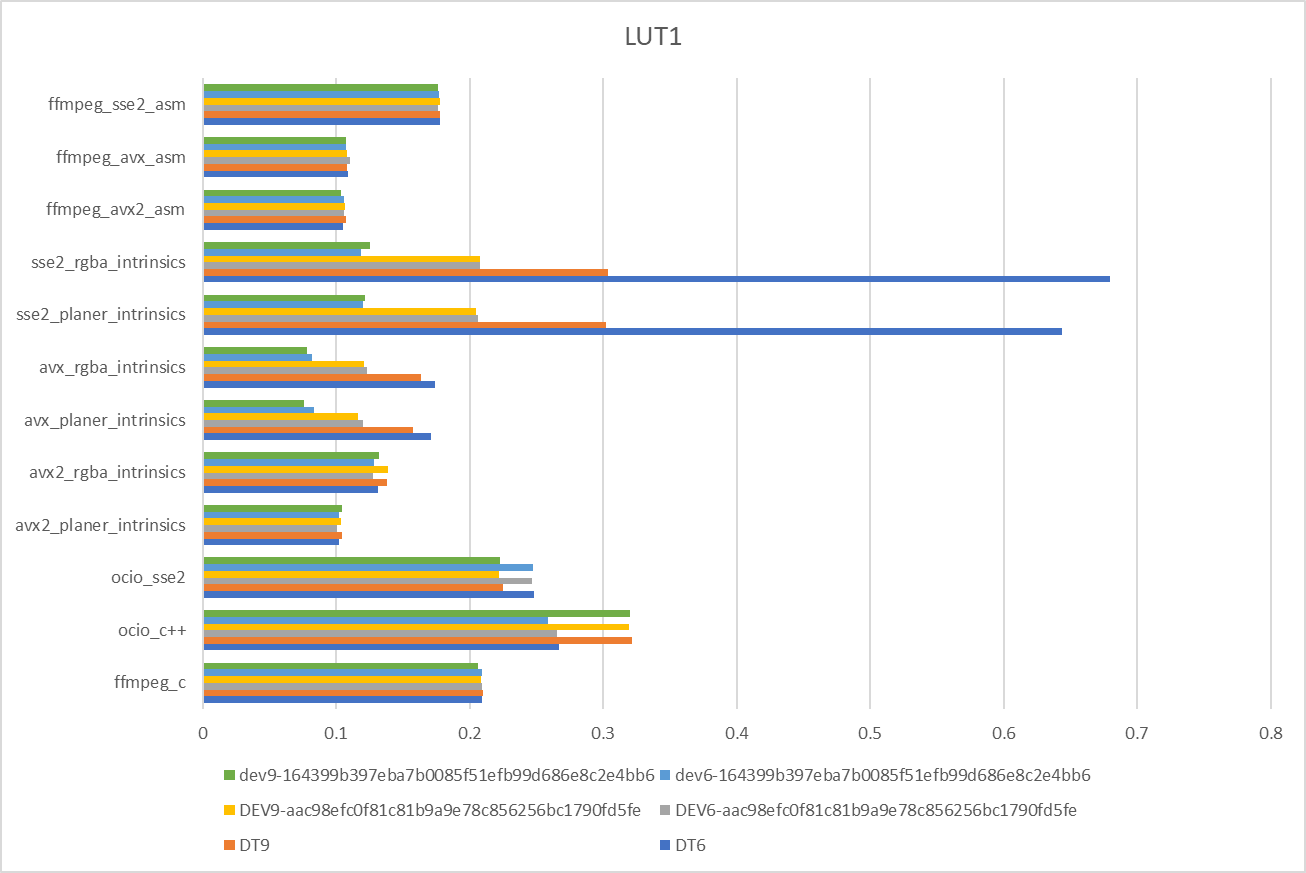
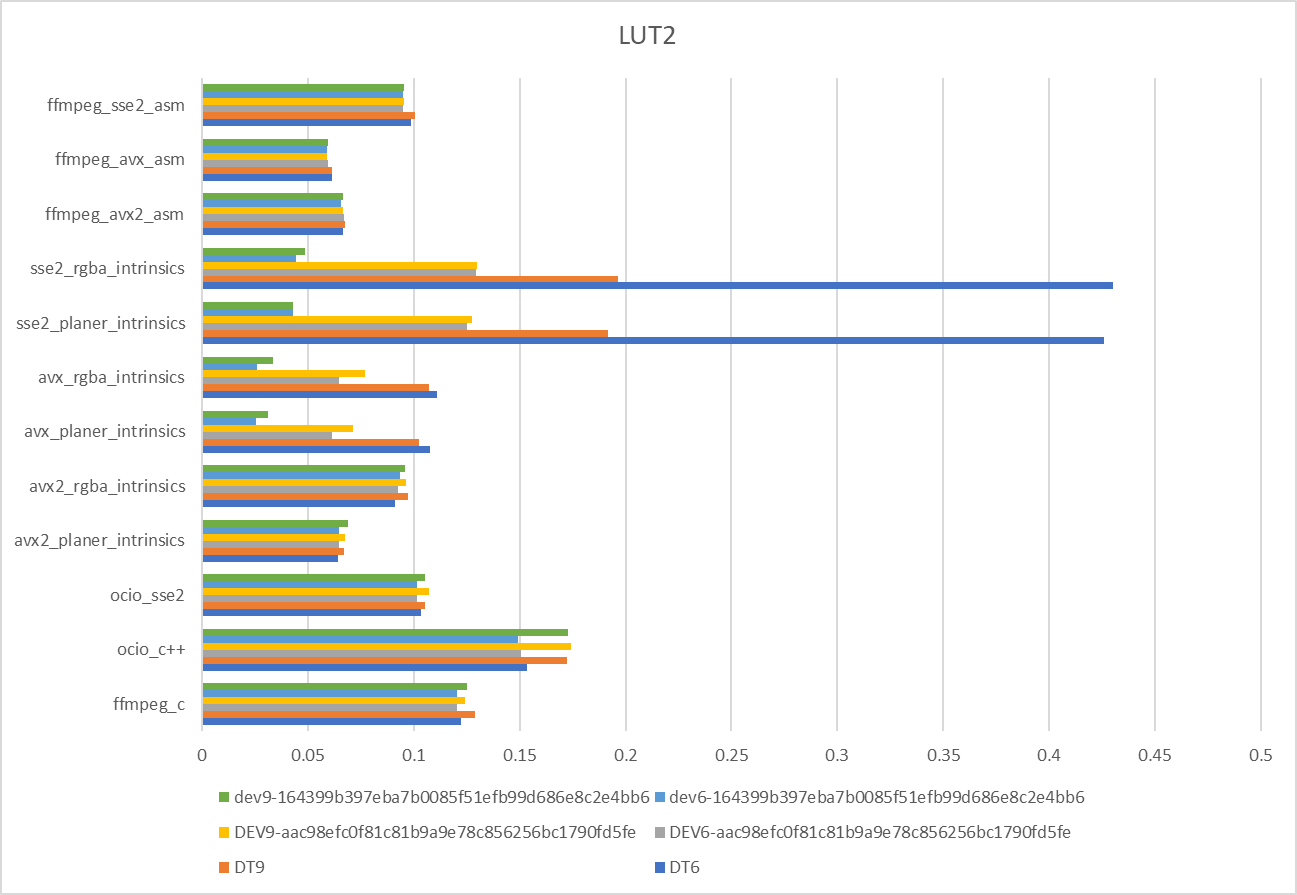
We see an improvement with the latest build so SSE2 and AVX intrinsics are now better than the existing
Wow, didn't expect AVX to out perform AVX2 that much! Even SSE2 does in LUT2. The main difference is AVX2 is using the vgatherdps instruction. I guess the way I changed the gather in SSE2/AVX is more cache friendly. AMD's vgatherdps might also not be as optimal as Intel's. I'll try changing the AVX2 version to use the AVX technique, if it doesn't improve perf, there might not be much need for a AVX2 version.,
I look a bit more into this. According to FFmpeg, AMD Zen 3 and earlier have slow gather, same with intel Haswell.
AMD EPYC 7F72 is a Zen 2 architecture, so I think the performance in AVX2 makes sense. The cpuid instruction can be used to identify these cpus and not use the AVX2 version.