stable-diffusion-webui
 stable-diffusion-webui copied to clipboard
stable-diffusion-webui copied to clipboard
Implement correct training method, Gradient Accumulation, and more
Some new features, optimizations, and fixes for TI and hypernetwork training!
-
Correctly sample from the VAE encoder while training When encoding the training data image, a random sample should be created for every loop of training. This is the correct implementation of ldm training code. However, for all this time, we have been using just ONE sample from the VAE. This is not how VAE works, its a Variational autoencoder, it encodes data to a normal-distributed latent space, not just one fixed result.
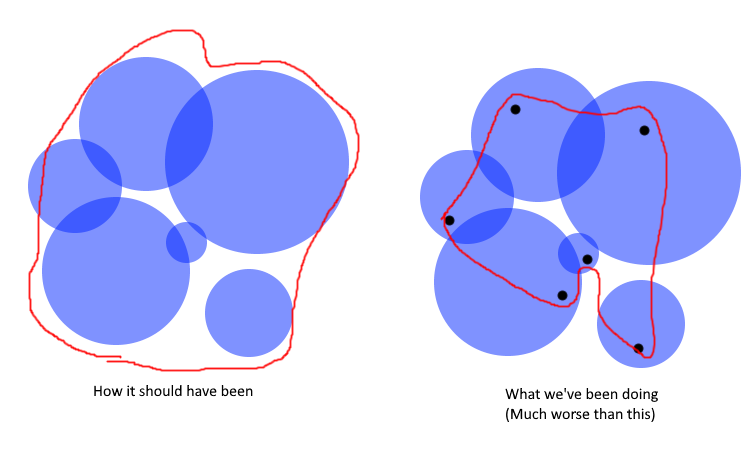
-
Gradient Accumulation added Now we can train with larger batch sizes without being limited by VRAM.
-
Use DataLoader Because the pin_memory feature gives a speed boost. Also makes the code a lot cleaner.
-
This pr partially fixes training when other SD VAE are selected. The error is directly related to scale_factor that is multiplied to the random sample from the encoder. When no VAE is selected, it correctly applies scale_factor=0.18215, but when other VAE is selected, it applies scale_factor=1, botching the training process. This pr universally applies scale_factor=0.18215, but it can still fail with other VAE/model because their optimal scale_factor can be different from 0.18215.
-
Also changed the loss display to show its true value, instead of showing the mean of last 32 steps.
-
Disabled report_statistics for hypernetworks, with gradient accumulation applied, viewing loss for individual images are not needed
-
[x] Gradient Accumulation
-
[ ] DataLoader (Needs adjustments with pin_memory and overall problems with current training loop)
-
[x] Print true loss instead of mean loss
-
[ ] Optimize cond_model in TI
-
[x] Add probablistic latent sampling in training (faithful implementation of original training method)
-
[ ] Add deterministic latent sampling in training (better results could be achieved for TI)
Some room for improvement (Because there's nowhere else to write this down)
- Scaler for torch.autocast is correctly applied to TI, but I couldn't apply this in hypernetworks. This feature is very important, because it can fix the zero weight problem when lr is very low. https://pytorch.org/docs/stable/amp.html
- According to the torch docs, backward process should be outside the autocast block, but we can't do that because the original ldm code has added a checkpoint gradient feature, so inside the backward code, there's another forward process happening (which should be inside autocast block). I don't know how to fix this.
- TI could be accelerated if we can just get the prompt embeddings on data init along with the indices to inject TI embedding.
Good to see delighted pull request! but please keep your title clear, because otherwise we won't be able to see what it is, with first glance. pin_memory helps when you have enough memory on VRAM and when single epoch is fast, In this case, it is not likely help speed drastically, and should be separated as option.
Has dreambooth been trained wrongly too? It also uses a vae component during training.
Good to see delighted pull request! but please keep your title clear, because otherwise we won't be able to see what it is, with first glance. pin_memory helps when you have enough memory on VRAM and when single epoch is fast, In this case, it is not likely help speed drastically, and should be separated as option.
For what I know, pin_memory takes up reserved space in CPU RAM, not VRAM.
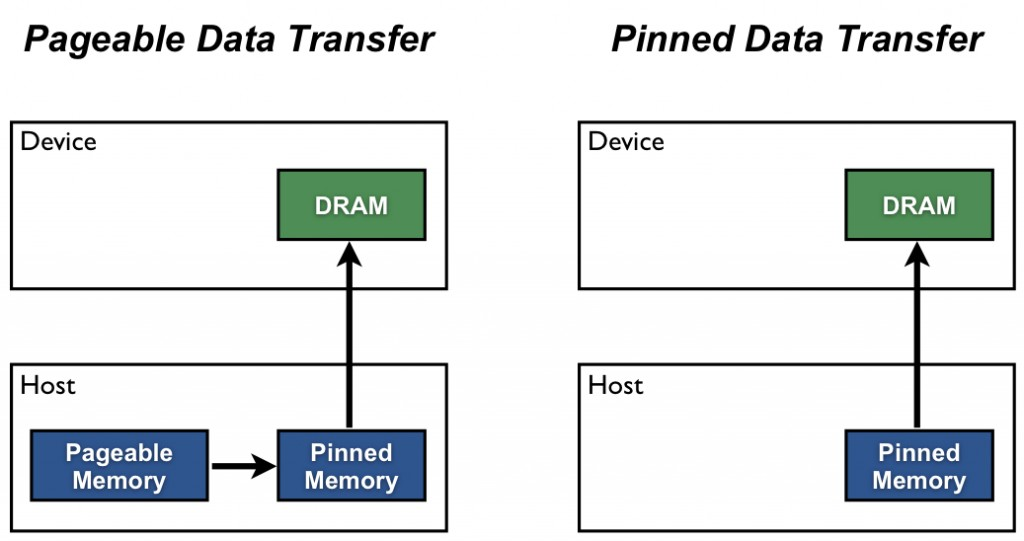 But I'll do some speed tests to check the effects.
But I'll do some speed tests to check the effects.
Has dreambooth been trained wrongly too? It also uses a vae component during training.
Not sure. This doesn't solve the core of the VAE problem.
https://pytorch.org/docs/stable/data.html
At default, pin_memory takes same effect as dataloader.to(device) (only available in pytorch, not in tensorflow)
Optional parameter pin_memory_device can specify where to pin, but normally you pin CUDA/device memory, not RAM. that schema is correct, but host is always CUDA if preferable. CPU actually should only work asynchronously, since its work is agent.
Your code is actually not using VAE, well I saw that you didn't do it... also the code reference came from here
Actually,for proper hacky way, you can just do
self.image_paths = [os.path.join(data_root, file_path) for file_path in os.listdir(data_root)] * 2
which creates multiple properly sampled latents. Or, of course you can do list[list[latents], ...] and pick from list.
Current method is definitely flawed, since it does not really sample, or nor uses encode_first_stage for sampling.
Well the purpose of this proposed change is to make random sampling possible without the need to call VAE model, so I just brought the functions.
The output of encode_first_stage is the DiagonalGaussianDistribution class instance, and get_first_stage_encoding is used to call the sample function of that instance. What my code does is store the results of encode_first_stage in the dataset, and use the same code to just sample for every training loop.
The original sampling method will still be usable. I will add additional select buttons for it so you can choose what method to use.
I tested this quickly by setting the accumulation step to the size of the whole data set, then batch size to highest my VRAM allows. It seems to be important that the accumlation and patch size divide nicely as in: 30 picture = 5 batch size and 6 accumulation. I'd say this "fixes" the TI system as a whole. However there needs to be a clear explanation for users what gradient accumulation is. I had to read up on it from a another source.
Would it be possible to see events inside the accumulation step? Since now you only get information when the step is finished (things like loss, prompt, iteration speeds).
I managed to quickly get very good results just by using subject.txt. No need to describe even "bad" images. The AI will no longer seem to get lost and drift as it used to.
Hey @aria1th You wrote above
TI could be accelerated if we can just get the prompt embeddings on data init along with the indices to inject TI embedding.
This is actually very important in my opinion. I think automatic implements the TI incorrectly right now, because here the input embedding to the text encoder is optimised, while in official code for TI authors hijack the output embedding from text encoder and replace it with trained one. This in theory should make optimisation task much easier and possibly could lead to better results. And of course without backprop through whole text-encoder it should become quicker
@5KilosOfCheese Accumulation steps are treated same as batch sizes, so they follow the same procedure. 1 step = 1 loss change, so it is pretty irrelevant what's happening inside 1 step. @bonlime Actually the code does have a hijack code that replaces the embeddings, but the order of functions are kinda inefficient. I did actually manage to change it by implementing another hijack function, but it crashes during backprop so I'm not going to fix it in this pr.
This is amazing, great work! Trained a TI of myself with 4 vectors, on 30 images.
Gradient accumulation set at 30 works so well with a really high learning rate, I'm using LR = 0.1!!! Just a couple of minutes on a 3090, 30 steps of training, and the previews look like me! I generate a preview image and embedding every step!
It's night and day compared to the previous method. At such high LRs initialisaion text doesn't matter either, I just used a a a a, it's blasted away in the first couple of steps.
Pulling the latest code, there seems to be a bug when interrupting and resuming. The generated preview image that was quite stable suddenly changes hugely, and then begins to stabilise again? I noticed this trying batch 4 gradientaccum 20 with 80 images.
@Luke2642 I guess it has to do with the optimizer resetting its values every time training restarts? But TI stabilizes very quickly, so it wouldn't really be much of a problem.
@JaredS215 'random'
With this change I am now able to train cartoon styles. I have trained >300 successful models and my cartoon attempts always exploded.
We also need to change the default parameters. 100000 steps is nonsense, especially if the default training rate doesn't follow a schedule. Speaking of that, we should use a schedule as the default. 5e-3:1000,1e-3:3000,1e-4:5000 etc.
From my black-box studies the learning rate is amplified by increasing the token count, and I feel there needs to be some acknowledgement of that.
With this change I am now able to train cartoon styles. I have trained >300 successful models and my cartoon attempts always exploded.
We also need to change the default parameters. 100000 steps is nonsense, especially if the default training rate doesn't follow a schedule. Speaking of that, we should use a schedule as the default.
5e-3:1000,1e-3:3000,1e-4:5000etc.From my black-box studies the learning rate is amplified by increasing the token count, and I feel there needs to be some acknowledgement of that.
The default steps and schedule do seem really wrong and setting up novices for failures. The problem with 5e-3:1000,1e-3:3000,1e-4:5000 as a default is it would actually differ based on the batch size of the user. I think to normalize the UI and the schedule with epochs instead of steps so users don't have to do the math of images count/(batch size*gradient step) would be more intuitive and less confusing to users.
Indeed, we need to calculate the effective steps so people can understand the relationship between all of the parameters. The scheduling system could also support percentages ex. 5e-3:20%, 1e-3:40%, 1e-4:100% and calculate the integer based step schedule once the effective steps is calculated.
Indeed, we need to calculate the effective steps so people can understand the relationship between all of the parameters. The scheduling system could also support percentages ex. 5e-3:20%, 1e-3:40%, 1e-4:100% and calculate the integer based step schedule once the effective steps is calculated.
I'd suggest decimals as in 0.2 0.4 1.0. This is to unify the standard of interaction in the system. All other parameters are in decimal values, so the interface should be consistent in the input style. The problem with the presentation you suggested is vaguesness. I realise that you mean % of the total steps intended as goal posts; but in presentation even the concept of 40% after 20% can be seen in an incorrect manner misleading the average user. Unless clear documentation is written to ensure all the parameters are explained well. Task which isn't hard to do with slightest experiences in manual writing and following the guideline of "Only present meaningful information and meaningful choices".
Also can we be sure that presenting the markers like this won't cause an issue with suddenly getting decimals of steps? As in 5e-3:0.2 leading to suddenly the limit being 3.333... steps? Would the system throw a tantrum?
But earlier on @JaredS215 suggested using epochs instead. This would make sense in technical and user interaction sense. And the notation could be simplified to an easier: 0.005:1. Since the exponent marking is not used in any other interaction of this system other than training. Unify all interaction to same presentation and interaction.