add option AMREX_ALLOW_USER_OMP
Summary
Allows the application code to use multiple OpenMP threads to launch AMReX GPU kernels.
Additional background
This is necessary for Quokka's implementation of communication-computation overlapping: Quokka creates an OpenMP parallel region with 2 threads. Thread 0 is used to call the FillPatch utility routines that block on completion of MPI communication. Thread 1 is used to launch kernels to perform updates on the 'inner' box of each FAB which does not need ghost cells to be updated (i.e., iter.validbox().ngrow(-nghost)). After both of these operations complete, control returns to the main thread, which launches kernels to update the 'outer' boxes of each FAB.
Checklist
The proposed changes:
- [ ] fix a bug or incorrect behavior in AMReX
- [x] add new capabilities to AMReX
- [ ] changes answers in the test suite to more than roundoff level
- [ ] are likely to significantly affect the results of downstream AMReX users
- [ ] include documentation in the code and/or rst files, if appropriate
Can you just include
omp.hin Quokka directly?
This addresses a separate issue. Without this option, kernels from different omp threads aren't launched into different streams. The stream index used by MFIter changes depending on what OpenMP::get_thread_num() returns: https://github.com/AMReX-Codes/amrex/blob/204bd7cf7353e7ccbfdcfdf7834d069b7da33d0f/Src/Base/AMReX_GpuDevice.cpp#L583. This PR changes the implementation of OpenMP::get_thread_num() to actually return the OpenMP thread id: https://github.com/AMReX-Codes/amrex/blob/204bd7cf7353e7ccbfdcfdf7834d069b7da33d0f/Src/Base/AMReX_OpenMP.H#L13 rather than just returning 0: https://github.com/AMReX-Codes/amrex/blob/204bd7cf7353e7ccbfdcfdf7834d069b7da33d0f/Src/Base/AMReX_OpenMP.H#L25
@WeiqunZhang For a fully correct implementation, we also need to be able to set the stream priority on each GPU stream (in order to ensure the buffer packing kernel runs before the inner update kernels, otherwise the inner update could accidentally block the communication).
I was planning to submit a separate PR for this, since it's somewhat more invasive: the calls to cudaStreamCreate have to be replaced with calls to cudaStreamCreateWithPriority. I don't know what the analogous changes for HIP and SYCL are. If there's a better way to do this, let me know.
This should only affect the situation where you would have OpenMP enabled at the compiler level but without using AMREX_USE_OMP, right? I am not sure I understand the motivation for that scenario is.
This should only affect the situation where you would have OpenMP enabled at the compiler level but without using AMREX_USE_OMP, right? I am not sure I understand the motivation for that scenario is.
Yes. The motivation is the communication-compute overlapping implementation that I've linked to this PR. In the level advance, we create an omp parallel num_threads(2) region, which then queries its OMP thread ID: thread 0 calls FillPatch and launches kernels on high-priority CUDA stream gpu_stream[0] while thread 1 launches kernels to update the 'inner' boxes of each FAB on lower-priority gpu_stream[1]. This allows communication overlapping with the inner updates without any changes to the FillPatch utility functions.
This was the least invasive way we could think of to implement communication overlap. If there's a better way, let me know.
we also need to be able to set the stream priority on each GPU stream (in order to ensure the buffer packing kernel runs before the inner update kernels, otherwise the inner update could accidentally block the communication)
You might already have accounted for this and/or it doesn't matter, but just as a note, I think even in CUDA this cannot be semantically guaranteed using stream priority alone. Ultimately one of the two kernels will launch first, and since the NVIDIA driver's scheduler is greedy in the sense that it will launch threadblocks as soon as they're available, you can imagine a scenario where thread 1 executes before thread 0 and thus starts some tiles from the interior because thread 0 hasn't actually launched a kernel yet. I think in practice though if you used an OpenMP barrier to ensure that thread 0 doesn't start launching its work after thread 1, you're probably fine. (But check this, of course.)
I think even in CUDA this cannot be semantically guaranteed using stream priority alone. Ultimately one of the two kernels will launch first, and since the NVIDIA driver's scheduler is greedy in the sense that it will launch threadblocks as soon as they're available, you can imagine a scenario where thread 1 executes before thread 0 and thus starts some tiles from the interior because thread 0 hasn't actually launched a kernel yet. I think in practice though if you used an OpenMP barrier to ensure that thread 0 doesn't start launching its work after thread 1, you're probably fine. (But check this, of course.)
Ah... I was relying on the high-priority stream to preempt the lower-priority one, but I see now that the wording in the documentation does not guarantee preemption ("Work in a higher priority stream may preempt work already executing in a low priority stream").
In practice, the work from thread 0 seems to always be launched first. I don't see how to use an omp barrier in this case. Wouldn't I need something more complicated, say, having thread 1 to spin wait on an atomic set from thread 0 right before it calls MPI_Waitall?
Well, this does appear to be a fatal flaw for correct behavior using an unmodified FillPatch function.
@WeiqunZhang would the team consider merging FillPatch_nowait and FillPatch_finish asynchronous functions if we wrote them for our use case? This seems to be the next best option, but please advise.
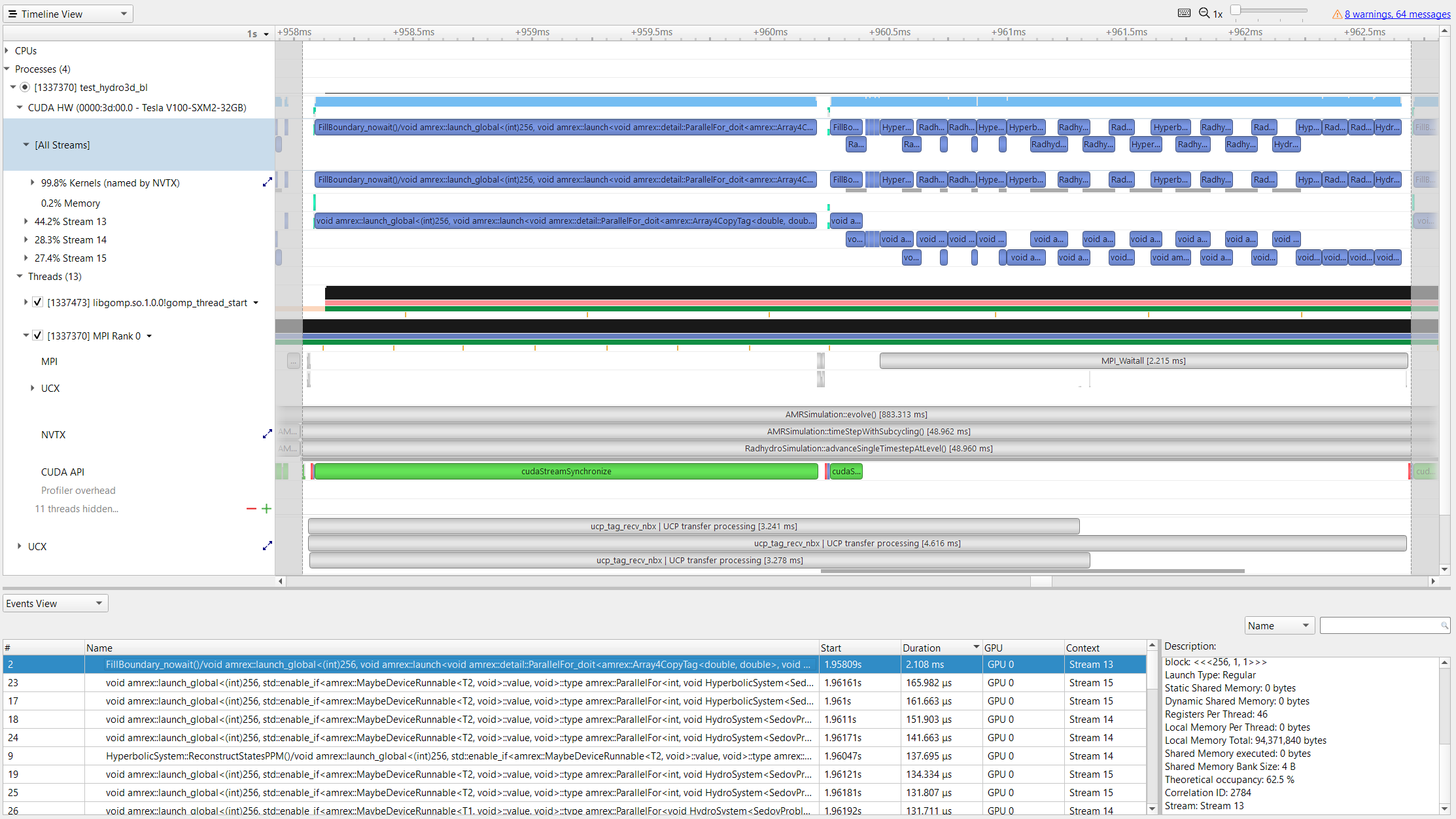
Here's a trace showing MPI_Waitall successfully overlapping with the inner updates on the GPU. Thread 0 wins the race to launch kernels from FillBoundary_nowait before the inner updates launch. Surprisingly (to me, at least), the packing kernel uses a lot of registers (46 registers per thread) and doesn't effectively overlap with the inner update kernels:
This does not seem right. It changes amrex:OpenMP::get_max_threads() etc. while everywhere in amrex we use ifdef AMREX_USE_OMP around OMP paragmas. Maybe we could add a special macro in Device::gpuStream function instead.
As for splitting FillPatch functions, yes, we will consider merging your changes if it is shown to be beneficial.
Finally, I have to say I am worried about the extra cost by splitting the computation into inner boxes and boundary cells. The cost of computation is not simply proportional to the number of cells. The memory access pattern for the boundary cells only kernel is not going to be great.
Hi @BenWibking,
I think the main things for merging this are:
1. Instead of changing the behavior of amrex::OpenMP::get_max_threads(), etc. globally, could you isolate the changes to the Device::gpuStream function here: https://github.com/AMReX-Codes/amrex/blob/d849a0f1b8cb2e88c2a916a502498b02e31c30b7/Src/Base/AMReX_GpuDevice.H#L55
2. Could you change the name of the macro to something more specific, like AMReX_DO_QUOKKA_INTERIOR_EXTERIOR, for example?
I think the main things for merging this are: 1. Instead of changing the behavior of
amrex::OpenMP::get_max_threads(), etc. globally, could you isolate the changes to theDevice::gpuStreamfunction here:https://github.com/AMReX-Codes/amrex/blob/d849a0f1b8cb2e88c2a916a502498b02e31c30b7/Src/Base/AMReX_GpuDevice.H#L55
I can change that, but there are some other places in the code that reference the OMP thread ID that it seems might also need changes. For instance, it looks like the MFIter loop sets the stream with setStreamIndex when initialized here: https://github.com/AMReX-Codes/amrex/blob/9473062293af7901e8ad24b103d063217f13995e/Src/Base/AMReX_MFIter.cpp#L346 and also when iterating through the boxes here: https://github.com/AMReX-Codes/amrex/blob/9473062293af7901e8ad24b103d063217f13995e/Src/Base/AMReX_MFIter.cpp#L506
setStreamIndex directly references the OMP thread ID. Does this also need to be changed? https://github.com/AMReX-Codes/amrex/blob/d849a0f1b8cb2e88c2a916a502498b02e31c30b7/Src/Base/AMReX_GpuDevice.cpp#L583
Will it work if you enable both GPU and OMP without any changes?
I'll test this and let you know.
@WeiqunZhang enabling AMREX_USE_OMP with the upstream AMReX leads to lots of bizarre crashes and test failures, so that's not a viable alternative.
I think the main things for merging this are: 1. Instead of changing the behavior of
amrex::OpenMP::get_max_threads(), etc. globally, could you isolate the changes to theDevice::gpuStreamfunction here: https://github.com/AMReX-Codes/amrex/blob/d849a0f1b8cb2e88c2a916a502498b02e31c30b7/Src/Base/AMReX_GpuDevice.H#L55I can change that, but there are some other places in the code that reference the OMP thread ID that it seems might also need changes. For instance, it looks like the MFIter loop sets the stream with
setStreamIndexwhen initialized here:https://github.com/AMReX-Codes/amrex/blob/9473062293af7901e8ad24b103d063217f13995e/Src/Base/AMReX_MFIter.cpp#L346
and also when iterating through the boxes here: https://github.com/AMReX-Codes/amrex/blob/9473062293af7901e8ad24b103d063217f13995e/Src/Base/AMReX_MFIter.cpp#L506
setStreamIndexdirectly references the OMP thread ID. Does this also need to be changed?https://github.com/AMReX-Codes/amrex/blob/d849a0f1b8cb2e88c2a916a502498b02e31c30b7/Src/Base/AMReX_GpuDevice.cpp#L583
I think that, if in your new implementation of Device::gpuStream, you use the gpu_stream_pool vector directly in the AMReX_DO_QUOKKA_INTERIOR_EXTERIOR branch instead of the gpu_stream vector, then what setStreamIndex does will be irrelevant. It will have a race condition, in that multiple threads will try to update the one value of gpu_stream that actually exists, but that value will never be used. By default, there will be 4 streams available in the gpu_stream_pool, and you can return whichever two you want to use.
@WeiqunZhang enabling AMREX_USE_OMP with the upstream AMReX leads to lots of bizarre crashes and test failures, so that's not a viable alternative.
If the crashes come from AMReX, could you let us know so that we can fix them? I just did a small test. It seems to work.
amrex/Tests/Amr/Advection_AmrCore/Exec(development)$ make -j4 USE_OMP=TRUE USE_CUDA=TRUE
$ OMP_NUM_THREADS=4 mpiexec -n 2 ./main2d.gnu.MPI.OMP.CUDA.ex inputs
Initializing CUDA...
CUDA initialized with 1 GPU(s) and 2 ranks.
MPI initialized with 2 MPI processes
MPI initialized with thread support level 0
OMP initialized with 4 OMP threads
AMReX (22.07-11-gb673d81723c5) initialized
In AMReX, we disable omp parallel with
#pragma omp parallel if (Gpu::notInLaunchRegion())
@WeiqunZhang enabling AMREX_USE_OMP with the upstream AMReX leads to lots of bizarre crashes and test failures, so that's not a viable alternative.
If the crashes come from AMReX, could you let us know so that we can fix them? I just did a small test. It seems to work.
It works fine with the unmodified code, but it fails when I explicitly create OMP regions in the level advance and put MFIters in them. I think I can modify the Advection example to reproduce the issue.