ElegantRL
 ElegantRL copied to clipboard
ElegantRL copied to clipboard
Massively Parallel Deep Reinforcement Learning. 🔥

执行 `python demo_A2C_PPO.py --gpu=0 --drl=0 --env=6` 出现异常 ``` File "elegantrl/train/evaluator.py", line 176, in get_cumulative_rewards_and_steps tensor_action = tensor_action.argmax(dim=1) IndexError: Dimension out of range (expected to be in range of [-1, 0],...
本人的环境是这样的: 操作系统:win10 cuda:11.8 cudnn:8.8.1 python:3.9.13 pytorch:2.0.0 ElegantRL是最新开发版 情况描述: 如果使用train_agent_multiprocessing,Learner进程通过管道把actor发到work进程这里: ``` '''Learner send actor to Workers''' for send_pipe in self.send_pipes: send_pipe.send(agent.act) ``` agent.act的成员state_std,会从 tensor([1., 1., 1., 1., 1., 1., 1., 1.,...
您好,我直接使用demo_A2C_PPO.py训练pendulum环境下的A2C算法无法收敛,可能算法实现上有问题。AgentDiscreteA2C算法仅继承了AgentDiscretePPO,并未实现自己的update_net函数
第235行部分self.cri.state_std[:] = self.cri.state_std,这样的话cri.state_std是永远不变的
`AgentMATD3` & `AgentMADDPG` cannot be call by `train_agent` or `train_agent_multiprocessing`, when I add them to 'demo_DDPG_TD3_SAC.py' Error shows like that Traceback (most recent call last): File "/Users/c/Downloads/ElegantRL-master/examples/demo_DDPG_TD3_SAC.py", line 238, in...
Are there any demos that can illustrate the process of using MATD3 / MADDPG to process discrete actions?
---> 5 from elegantrl.train.run import Arguments 6 from numpy import random as rd 7 ImportError: cannot import name 'Arguments' from 'elegantrl.train.run' (/usr/local/lib/python3.8/dist-packages/elegantrl/train/run.py)
I'm confused why we use 'logprob = dist.log_prob(a_avg)' instead of 'logprob = dist.log_prob(action)' in line 247 of elegantrl/agents/net.py. I think the latter is consistent to the original paper. Is using...
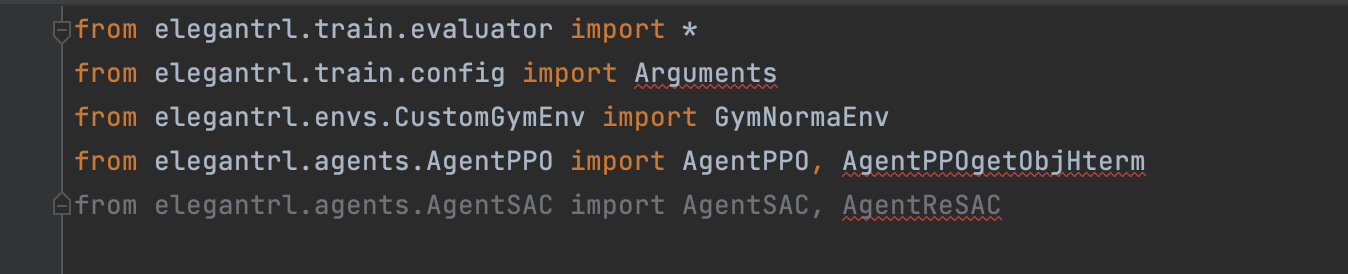 in "demo_mujoco_draw_obj_h.py"  in "demo_Isaac_Gym.py"  in "demo_DDPG_H.py"  in "demo_vec_env_A2C_PPO.py" 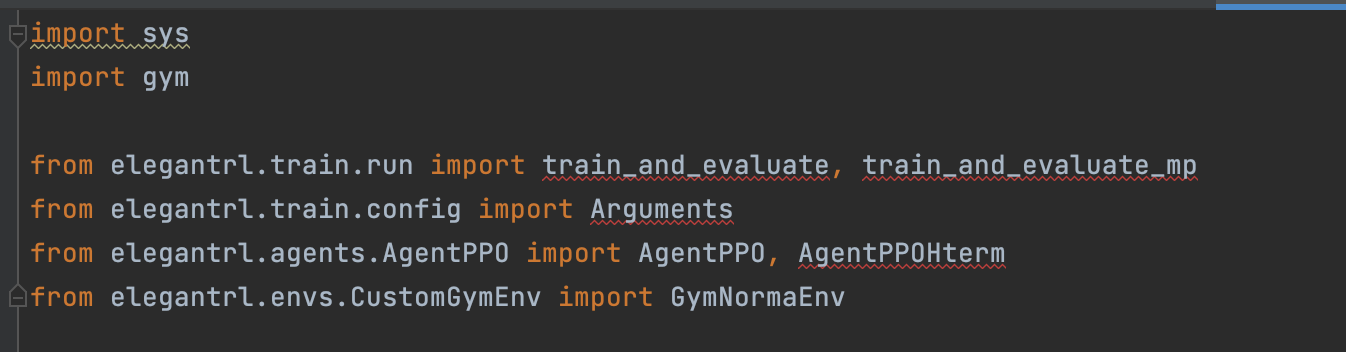 in "demo_PPO_H.py" 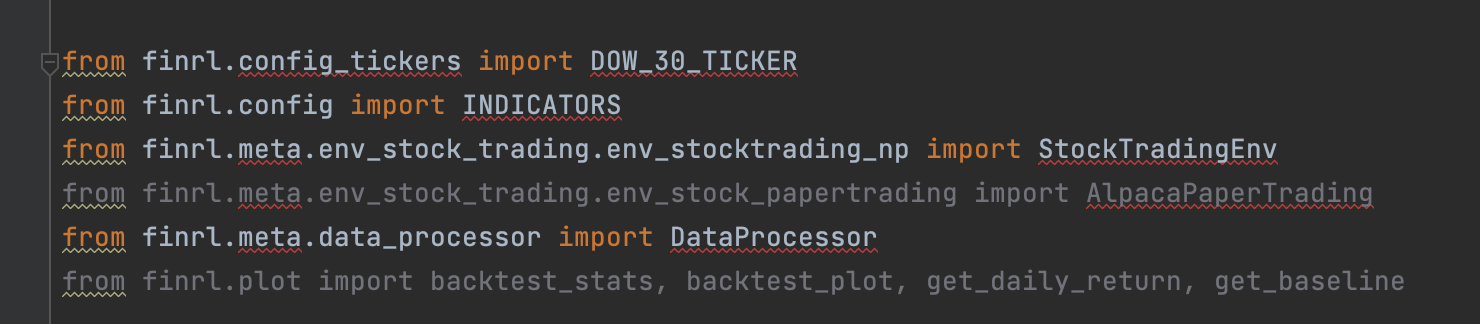 in "demo_PaperTradingEnv_PPO.py"  in "demo_mujoco_render.py"  in "tutorial_LunarLanderContinous-v2.py" 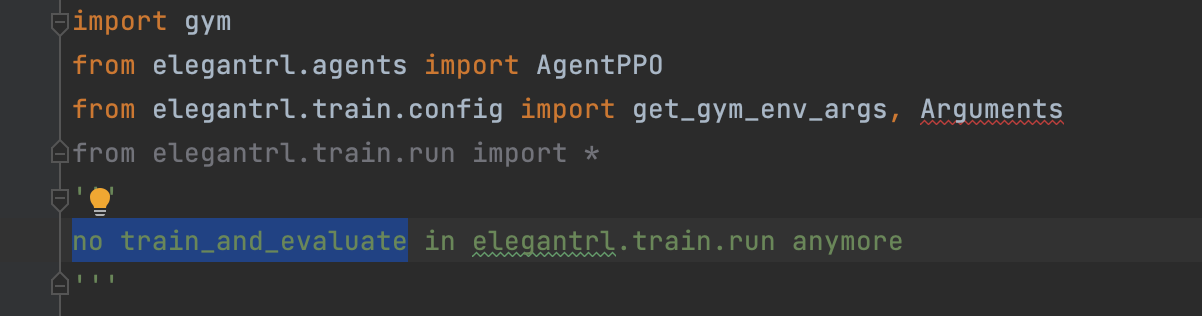 in "tutorial_Hopper-v3.py"  in "...
Metadata
Owner
Metadata
Massively Parallel Deep Reinforcement Learning. 🔥